分布式并行训练 - DDP
分布式训练将训练工作负载分散到多个工作节点,因此可以显著提高训练速度和模型准确性。
Distributed Data Parallel
- 为什么用 Distributed Training? 节约时间、增加计算量、模型更快。
- 如何实现?
- 在同一机器上使用多个 GPUs
- 在集群上使用多个机器
什么是DDP?
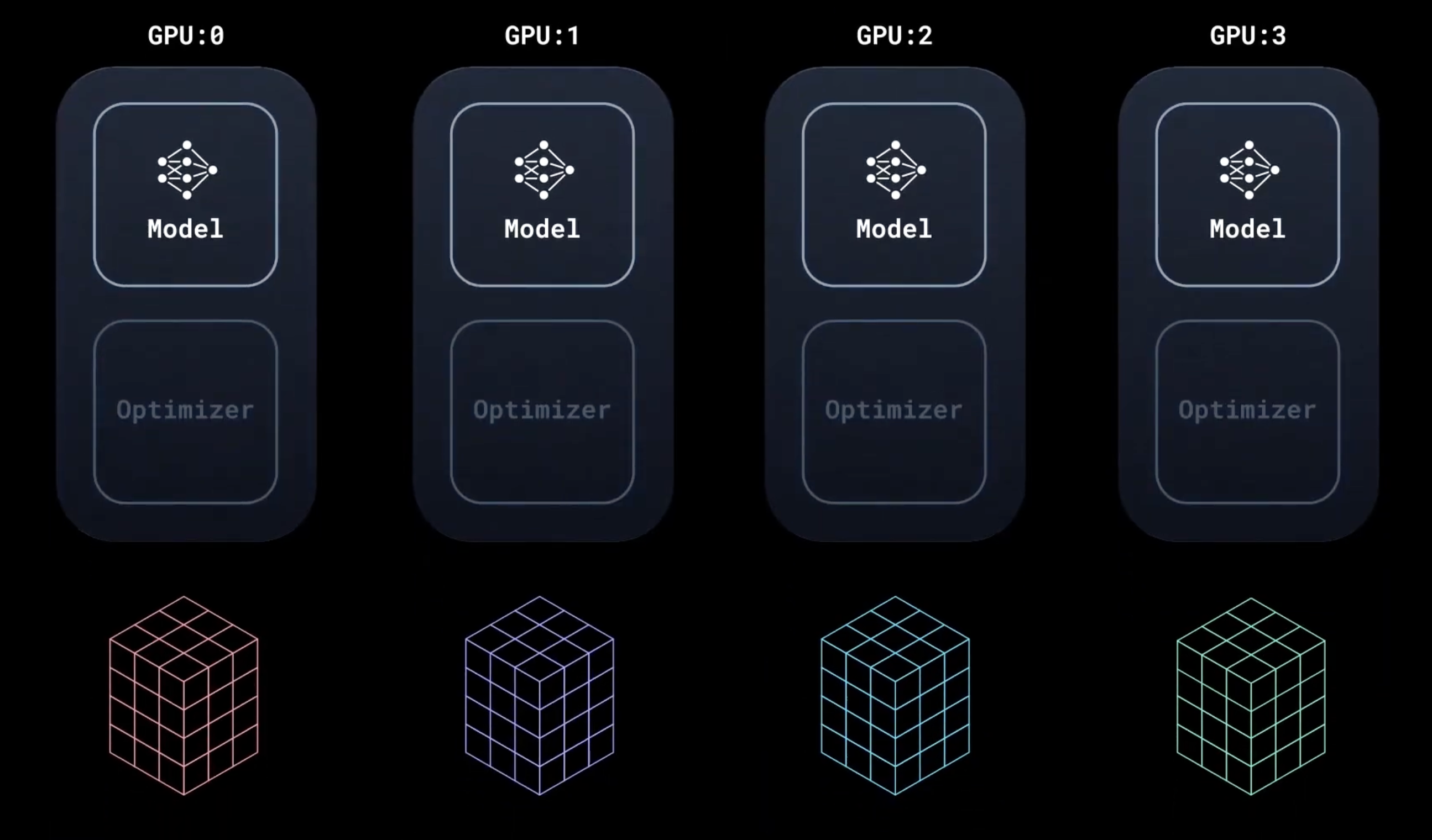
即在训练过程中内部保持同步:每个 GPU 进程仅数据不同。
模型在所有设备上复制。DistributedSampler 确保每个设备获得不重叠的输入批次,从而处理 n 倍数据。

模型接受不同输入的数据后,在本地运行前向传播和后向传播。
每个副本模型累计的梯度不同,DDP 启动同步:使用环状 AllReduce 算法聚合所有副本的梯度,将梯度与通信重叠
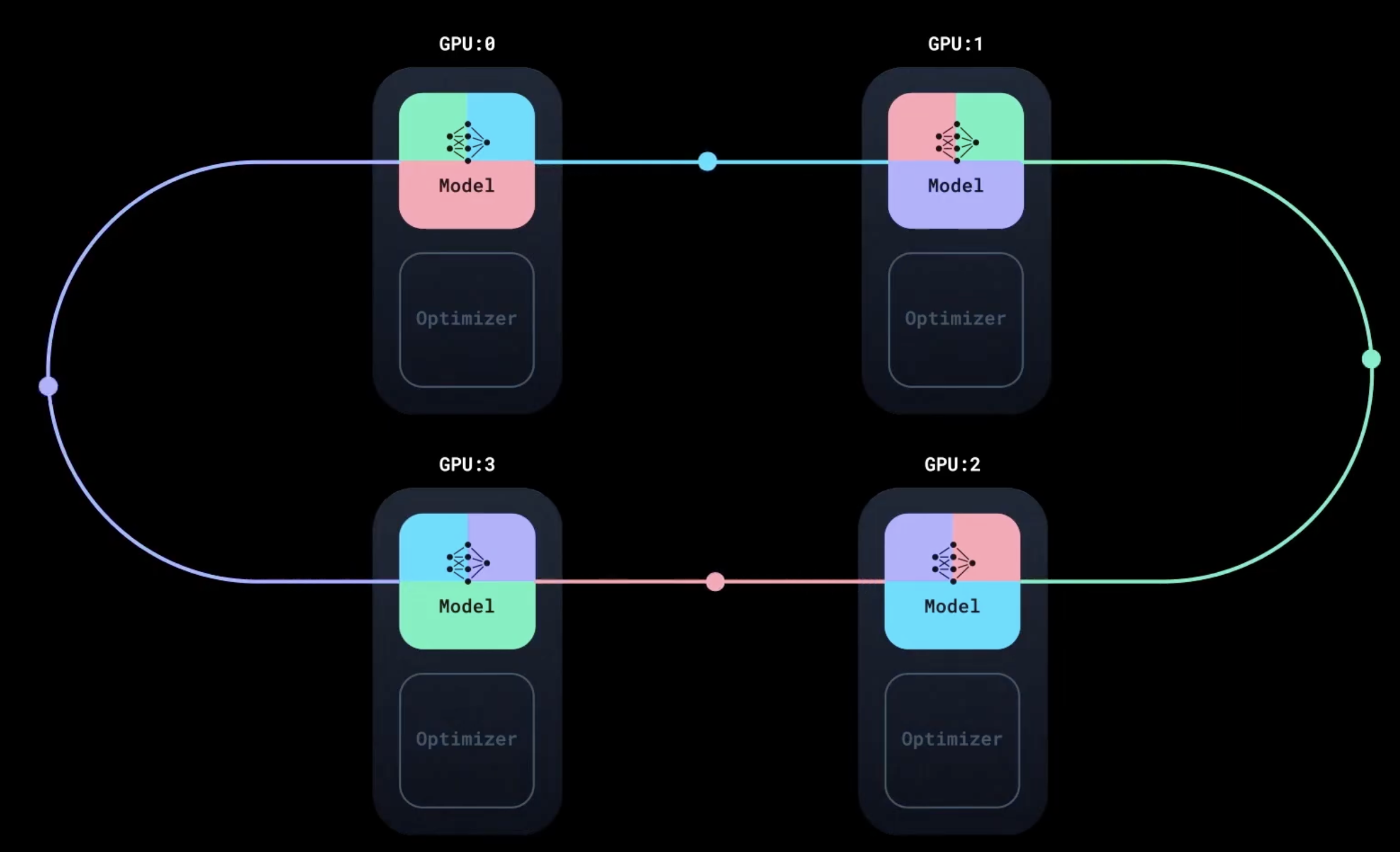
同步 不会等待所有的梯度计算完成,它在反向传播进行的同时沿环进行通信,确保 GPU 不会空闲
运行优化器,将所有副本模型的参数更新为相同的值
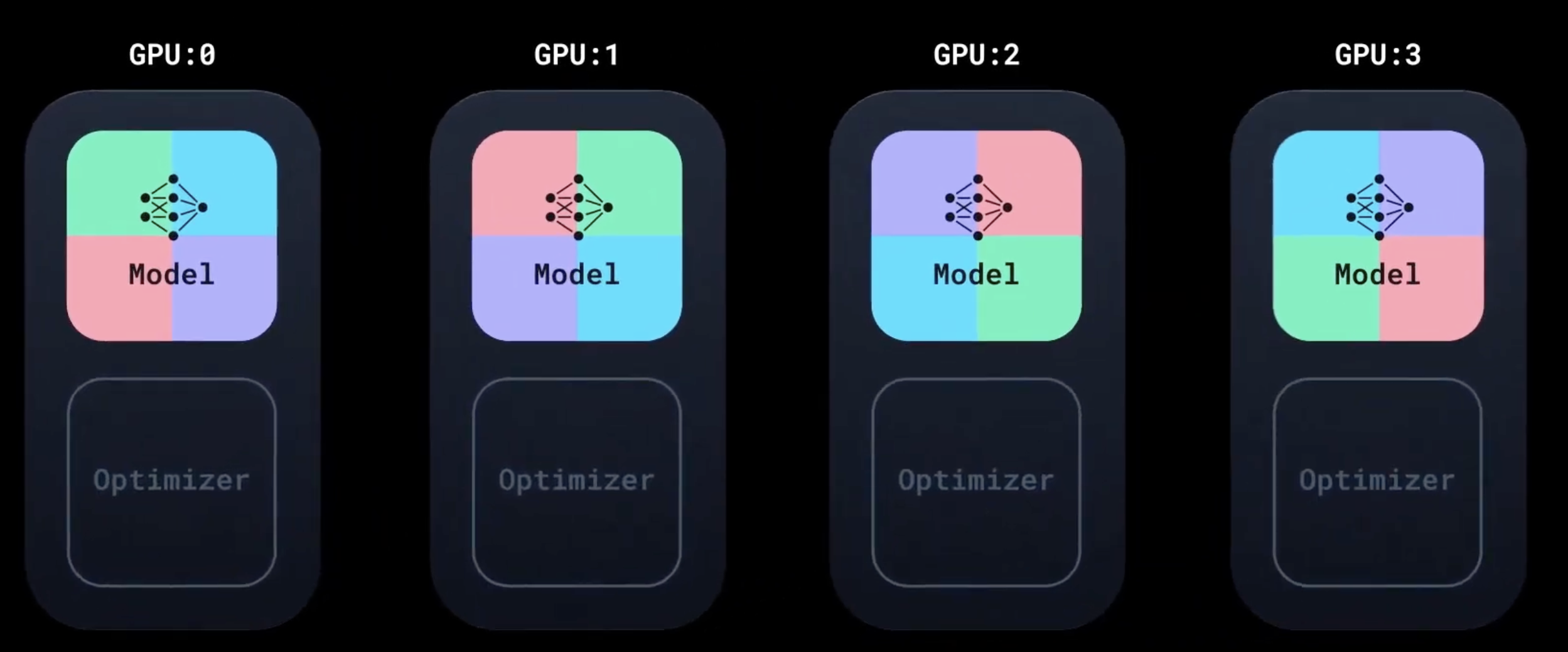
对比
DataParallel(DP):DP 非常简单(只需额外一行代码),但性能要差得多。单节点多 GPU 训练 - 单台机器上使用多 GPU 训练模型
增加 import 模块
import torch.multiprocessing as mp from torch.utils.data.distributed import DistributedSampler from torch.nn.parallel import DistributedDataParallel as DDP from torch.distributed import init_process_group, destroy_process_group import ostorch.multiprocessing是 PyTorch 对 Python 原生多进程的封装分布式进程组包含所有可以相互通信和同步的进程。
构建进程组(ddp_setup 函数)
def ddp_setup(rank, world_size): """ Args: rank: Unique identifier of each process world_size: Total number of processes """ os.environ["MASTER_ADDR"] = "localhost" # master主管其他进程 os.environ["MASTER_PORT"] = "12355" torch.cuda.set_device(rank) init_process_group(backend="nccl", rank=rank, world_size=world_size)set_device 为每个进程设置默认 GPU,防止 GPU:0 上的挂起或过度内存占用。
进程组通过 TCP(默认)或共享文件系统进行初始化。
init_process_group 初始化分布式进程组。
[!TIP]
阅读更多关于选择 DDP 后端的信息
用 DDP 包装 Trainer
class Trainer: def __init__( self, model: torch.nn.Module, train_data: DataLoader, optimizer: torch.optim.Optimizer, gpu_id: int, save_every: int, ) -> None: self.gpu_id = gpu_id self.model = model.to(gpu_id) self.train_data = train_data self.optimizer = optimizer self.save_every = save_every self.model = DDP(model, device_ids=[gpu_id])保存模型:用modul 访问底层模型参数
def _save_checkpoint(self, epoch): ckp = self.model.module.state_dict() PATH = "checkpoint.pt" torch.save(ckp, PATH) print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")仅保存一个进程的检查点即可
def train(self, max_epochs: int): for epoch in range(max_epochs): self._run_epoch(epoch) if self.gpu_id == 0 and epoch % self.save_every == 0: self._save_checkpoint(epoch)如果没有 if 条件,每个进程都会保存一份相同的模型副本。
分布式输入数据:DataLoader 要包含 DistributedSampler,且不 shuffle
def prepare_dataloader(dataset: Dataset, batch_size: int): return DataLoader( dataset, batch_size=batch_size, pin_memory=True, shuffle=False, sampler=DistributedSampler(dataset) )DistributedSampler 将输入数据分块分发到所有分布式进程。
DataLoader 结合了数据集和采样器,并为给定数据集提供一个可迭代对象。
- 每个进程将接收一个包含 32 个样本的输入批次;有效批次大小是
32 * nprocs,在使用 4 个 GPU 时为 128。
- 每个进程将接收一个包含 32 个样本的输入批次;有效批次大小是
更新 main 函数
def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int): ddp_setup(rank, world_size) dataset, model, optimizer = load_train_objs() train_data = prepare_dataloader(dataset, batch_size) trainer = Trainer(model, train_data, optimizer, rank, save_every) trainer.train(total_epochs) destroy_process_group()spwn() 启动多进程,并行执行制定函数
if __name__ == "__main__": import argparse parser = argparse.ArgumentParser(description='simple distributed training job') parser.add_argument('total_epochs', type=int, help='Total epochs to train the model') parser.add_argument('save_every', type=int, help='How often to save a snapshot') parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)') args = parser.parse_args() world_size = torch.cuda.device_count() mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)包含新的参数
rank(替换device)和world_size。调用 mp.spawn 时,
rank由 DDP 自动分配。world_size是整个训练任务中的进程数。对于 GPU 训练,这对应于使用的 GPU 数量,并且每个进程在一个专用的 GPU 上工作。
[!NOTE]
如果模型包含任何
BatchNorm层,则需要将其转换为SyncBatchNorm,以便在副本之间同步BatchNorm层的运行统计信息。使用辅助函数 torch.nn.SyncBatchNorm.convert_sync_batchnorm(model) 可以将模型中的所有
BatchNorm层转换为SyncBatchNorm。
容错分布式训练 -
torchrun使分布式训练具有鲁棒性在分布式训练中,单个进程故障可能会中断整个训练任务。我们希望训练脚本具有鲁棒性、训练任务具有弹性,例如,计算资源可以在任务执行期间动态加入和离开。
torchrun提供了容错和弹性训练功能。当发生故障时,torchrun会记录错误并尝试从上次保存的训练任务“快照”自动重启所有进程。快照保存模型状态、已运行的 epoch 数量、优化器状态 / 训练任务连续性所需的任何其他有状态属性的详细信息。进程组初始化:
def ddp_setup(): torch.cuda.set_device(int(os.environ["LOCAL_RANK"])) init_process_group(backend="nccl")torchrun会自动分配RANK、WORLD_SIZE和其他环境变量在 Trainer 构造函数中加载快照
class Trainer: def __init__( self, model: torch.nn.Module, train_data: DataLoader, optimizer: torch.optim.Optimizer, save_every: int, snapshot_path: str, ) -> None: self.gpu_id = int(os.environ["LOCAL_RANK"]) # 使用 torchrun 提供的环境变量 self.model = model.to(self.gpu_id) self.train_data = train_data self.optimizer = optimizer self.save_every = save_every self.epochs_run = 0 # 当重启中断的训练任务时,脚本将首先尝试加载快照以从中恢复训练 self.snapshot_path = snapshot_path if os.path.exists(snapshot_path): print("Loading snapshot") self._load_snapshot(snapshot_path) self.model = DDP(self.model, device_ids=[self.gpu_id])保存和加载快照
def _load_snapshot(self, snapshot_path): loc = f"cuda:{self.gpu_id}" snapshot = torch.load(snapshot_path, map_location=loc) self.model.load_state_dict(snapshot["MODEL_STATE"]) self.epochs_run = snapshot["EPOCHS_RUN"] print(f"Resuming training from snapshot at Epoch {self.epochs_run}")def _save_snapshot(self, epoch): snapshot = { "MODEL_STATE": self.model.module.state_dict(), "EPOCHS_RUN": epoch, } torch.save(snapshot, self.snapshot_path) print(f"Epoch {epoch} | Training snapshot saved at {self.snapshot_path}")定期将所有相关信息存储在快照中,可以使我们的训练任务在中断后无缝恢复
训练脚本(从断点处开始训练):
def train(self, max_epochs: int): # 训练可以从上次运行的 epoch 恢复,而不是从头开始 for epoch in range(self.epochs_run, max_epochs): self._run_epoch(epoch) if self.gpu_id == 0 and epoch % self.save_every == 0: self._save_snapshot(epoch)def main(save_every: int, total_epochs: int, batch_size: int, snapshot_path: str = "snapshot.pt"):: ddp_setup() dataset, model, optimizer = load_train_objs() train_data = prepare_dataloader(dataset, batch_size) trainer = Trainer(model, train_data, optimizer, save_every, snapshot_path) trainer.train(total_epochs) destroy_process_group()如果发生故障,
torchrun将终止所有进程并重新启动它们。每个进程入口点首先加载并初始化上次保存的快照,然后从那里继续训练。因此,在任何故障发生时,你只会丢失上次保存快照之后的训练进度。
在弹性训练中,无论何时发生成员变化(添加或移除节点),
torchrun都会 终止 并 在可用设备上生成进程,从而确保训练任务可以在无需手动干预的情况下继续进行。运行脚本
if __name__ == "__main__": import argparse parser = argparse.ArgumentParser(description='simple distributed training job') parser.add_argument('total_epochs', type=int, help='Total epochs to train the model') parser.add_argument('save_every', type=int, help='How often to save a snapshot') parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)') args = parser.parse_args() # torchrun 会自动生成进程 main(args.save_every, args.total_epochs, args.batch_size)删除了所有显示的环境变量,因为
torchrun会处理这些变量。torchrun --standalone --nproc_per_node=4 multigpu_torchrun.py 50 10
为何使用
torchrun:- 无需设置环境变量或显式传递
rank和world_size;torchrun会自动分配环境变量。 - 无需在脚本中调用
mp.spawn;只需要一个通用的main()入口点,然后使用torchrun启动脚本。同一个脚本可以在非分布式、单节点和多节点环境中运行。 - 从上次保存的训练快照处重启训练。
多节点训练 - 在多台机器上用多个 GPU 训练模型
- 多节点训练指将训练作业部署到多台机器上。有两种方法可以实现:
- 在每台机器上运行具有相同 rendezvous 参数的
torchrun命令,或 - 使用**工作负载管理器(如 SLURM)**将其部署在计算集群上
- 在每台机器上运行具有相同 rendezvous 参数的
- Torchrun 支持异构扩展,即: 每个多节点机器可以参与训练作业的 GPU 数量不同
多节点训练的瓶颈在于节点间通信延迟。在单个节点上使用 4 个 GPU 运行训练作业将比在 4 个节点上每个节点使用 1 个 GPU 运行要快。
本地 Rank 和全局 Rank
self.local_rank = int(os.environ["LOCAL_RANK"]) self.global_rank = int(os.environ["RANK"])def _run_epoch(self, epoch): b_sz = len(next(iter(self.train_data))[0]) print(f"[GPU{self.global_rank}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}") self.train_data.sampler.set_epoch(epoch) for source, targets in self.train_data: source = source.to(self.local_rank) targets = targets.to(self.local_rank) self._run_batch(source, targets)

[!WARNING]
请勿在训练作业的关键逻辑中使用
RANK。当torchrun在故障或成员变更后重启进程时,无法保证进程会保持相同的LOCAL_RANK和RANKS方法一:在每台机器上运行
torchrun例如

方法二:使用 SLURM 运行
torchrun在AWS上设置集群
运行脚本
cat slurm/sbatch_run.sh检查状态
squeue查看输出
cat slurm-15.out
故障排除
确保节点可以通过 TCP 相互通信。
将环境变量
NCCL_DEBUG设置为INFO以打印详细日志:export NCCL_SOCKET_IFNAME=eth0有时可能需要显式设置分布式后端的网络接口(
export NCCL_SOCKET_IFNAME=eth0)。
- 多节点训练指将训练作业部署到多台机器上。有两种方法可以实现:
使用 DDP 训练 miniGPT 模型
首先,克隆 minGPT 仓库,并重构 Trainer。代码重构完成后,首先在带有 4 个 GPU 的单节点上运行它,然后在 slurm 集群上运行。
用于训练的文件
trainer.py:包含 Trainer 类,基于提供的数据集在模型上运行分布式训练迭代。
model.py:定义了 GPT 模型架构。
char_dataset.py:包含字符级别数据集的
Dataset类。gpt2_train_cfg.yaml:包含数据、模型、优化器和训练运行的配置。
使用 hydra 集中管理训练运行的所有配置。
main.py:训练任务的入口点,设置 DDP 进程组,读取 yaml 中的配置来启动训练任务。
使用混合精度:可加快训练速度。在混合精度中,训练过程的某些部分以较低精度进行,而对精度下降更敏感的其他步骤则保持 FP32 精度。
何时 DDP 不够用?
内存占用包括模型权重、激活、梯度、输入批次和优化器状态。由于 DDP 在每个 GPU 上复制模型,因此只有当 GPU 有足够的容量容纳全部内存占用时才能工作
- 当模型变得更大时:
- 激活检查点:在正向传播期间,不保存中间激活,而是在反向传播期间重新计算激活。计算增加。
- 全分片数据并行 (FSDP):模型不是复制的,而是在所有 GPU 上“分片”,计算与前向和后向传播中的通信重叠。例如,使用 FSDP 训练具有 1 万亿参数的模型。
- 当模型变得更大时: