分布式并行训练 - FSDP
Fully Sharded Data Parallel
DDP 回顾
名词解释
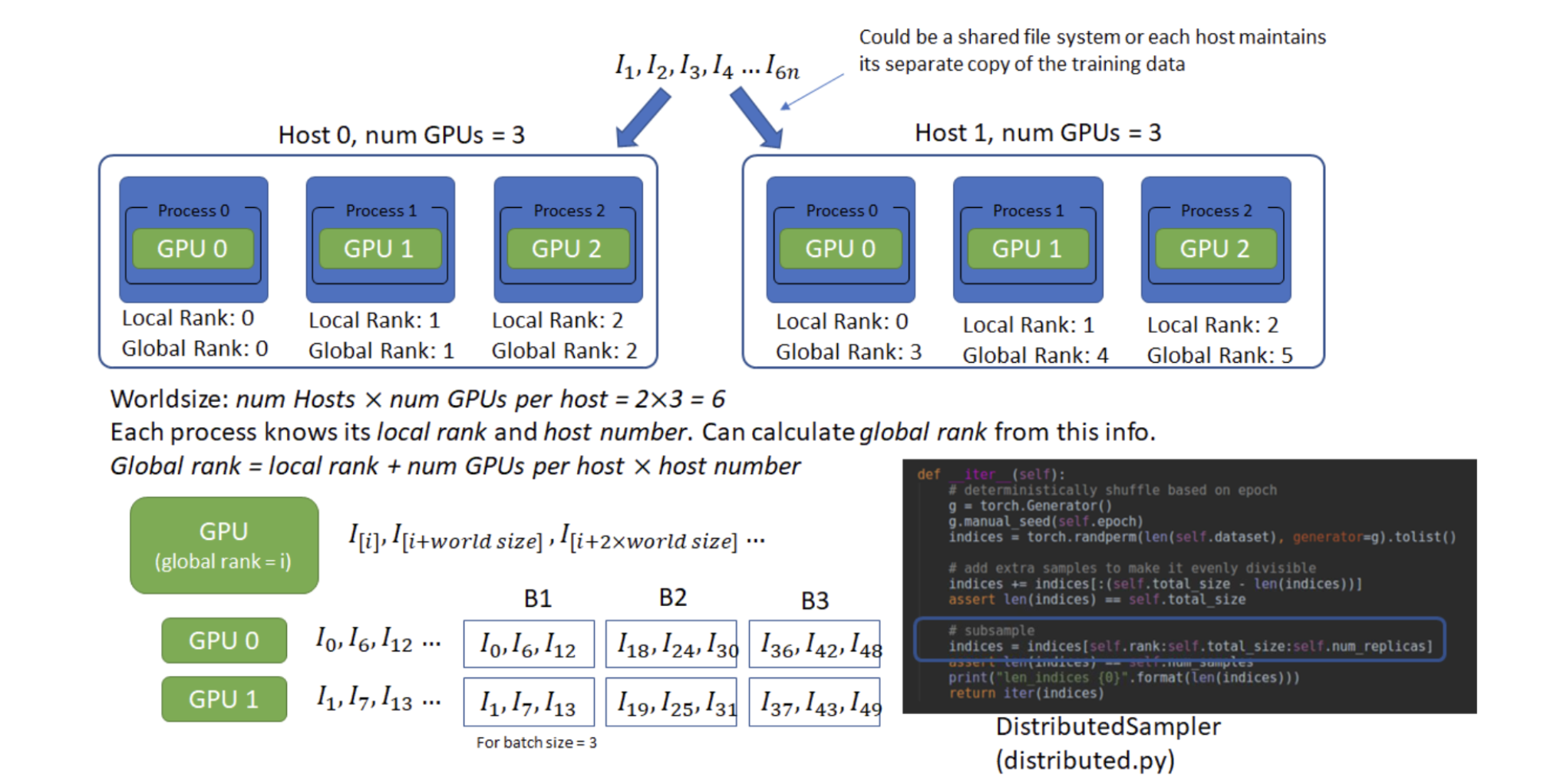
Host:可以理解为⼀台主机,每个主机有⾃⼰的IP地址,⽤于通信。
Local Rank:每个主机上,对不同GPU设备的编。
Global Rank:全局的GPU设备编号,Global Rank = Host * num GPUs per host + Local Rank。
Worldsize:总的GPU个数。num Hosts * num GPUs per host
DDP 参数更新过程
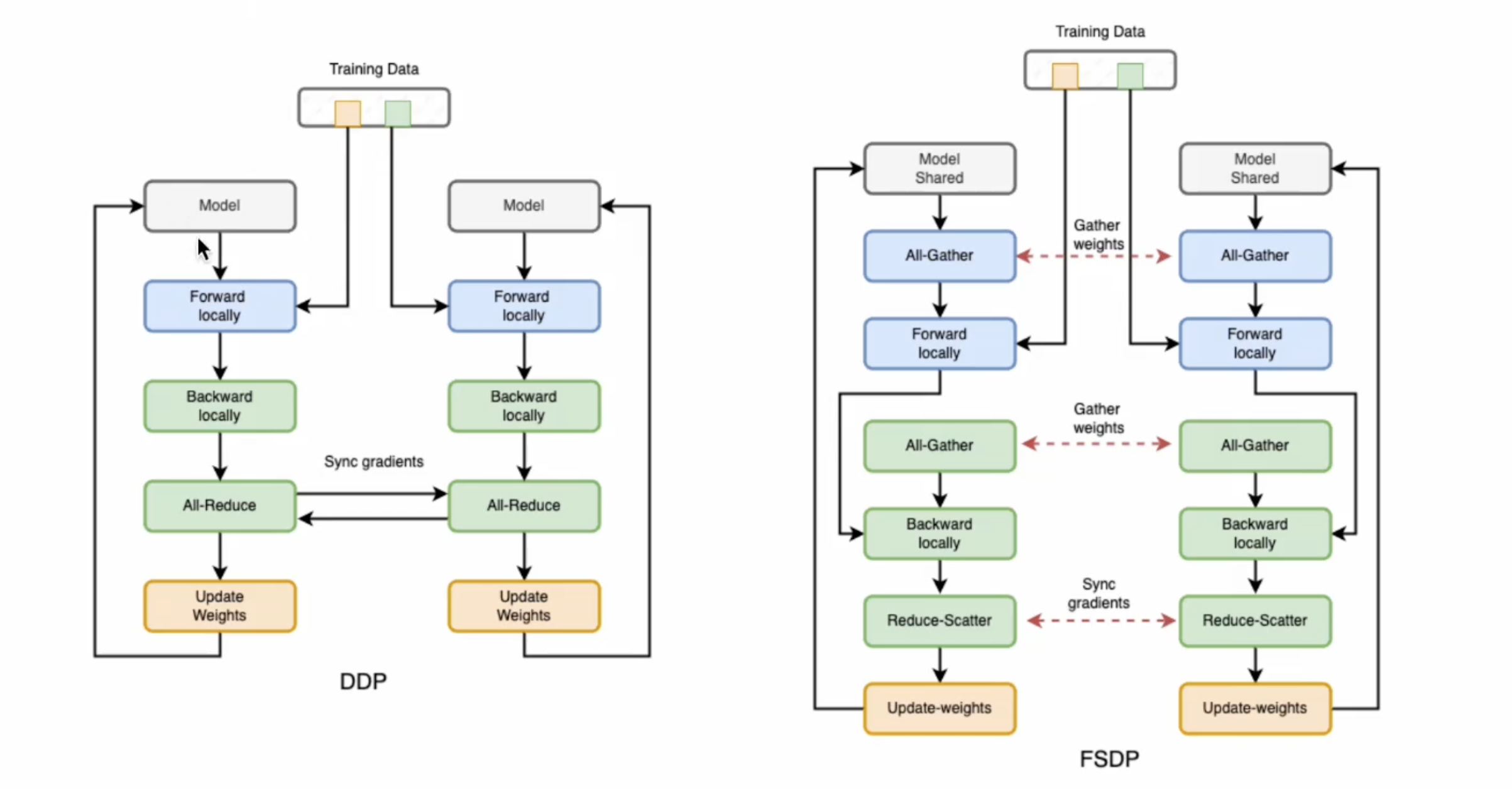
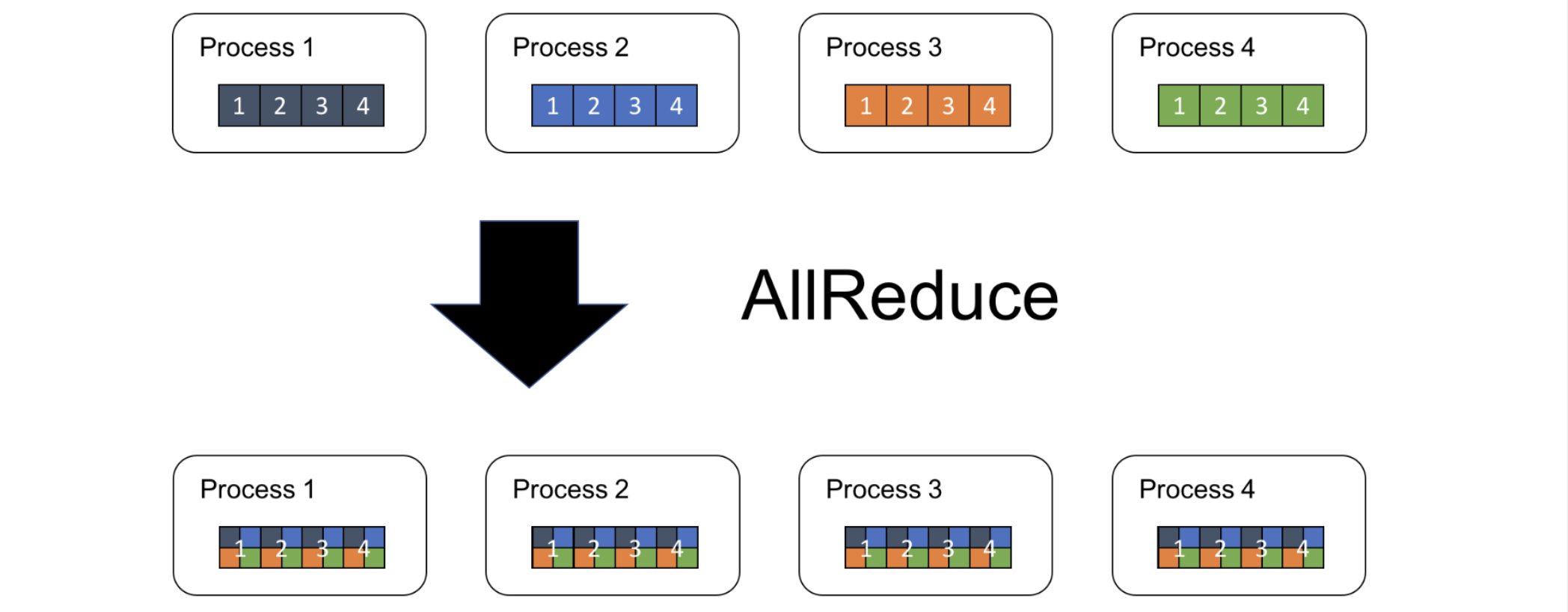
all-reduce 操作:同步,将所有GPU设备上的梯度进⾏求和取平均
缺点:每个设备都要进行设备的拷贝,存在模型的冗余
FSDP2 的工作原理
与 DDP 相比,FSDP 通过分片模型的参数、梯度和优化器状态来减少 GPU 内存占用,通过通信操作(all-gather/reduce-scatter)在计算需要时重建完整参数:

常规状态(非计算时):所有参数默认保持"分片"状态(即被分散存储在不同设备上)
前向/反向计算准备阶段;当需要计算时,系统会通过 all-gather 操作从所有设备收集参数分片,所有GPU均拥有完整的参数副本,但每个GPU处理的数据不同。
在同一轮前向传播和反向传播中,同一个GPU处理的始终是同一个Batch的数据
反向传播阶段:计算得到完整的本地梯度后,使用 reduce-scatter 操作将梯度重新分散到各设备,每个设备最终只保留自己负责的那部分梯度
- Reduce(聚合):对所有GPU的梯度 按元素相加,得到全局梯度
G_total = G0 + G1 + ...。
- Scatter(分片):将
G_total按参数分片规则拆分,每个GPU只保留自己负责的部分。
GPU0: [G0] --\ /-- [G_total_part0] → GPU0 GPU1: [G1] ---⊕--> | -- [G_total_part1] → GPU1 GPU2: [G2] ---/ \-- [G_total_part2] → GPU2- Reduce(聚合):对所有GPU的梯度 按元素相加,得到全局梯度
参数更新阶段:每个设备只更新自己持有的那部分参数(参数分片)、只使用对应的梯度分片,优化器状态也是分片存储的。

完整过程
Constructor
对模型参数进行切片分发到每个rank上
Forward pass
- 对每个 FSDP unit,运行 all_gather 收集所有 rank 上的模型参数切片,使每个 rank 上拥有当前 unit 的全部参数
- 执行前向计算
- 重新执行切片,丢掉不属于当前rank的模型参数,释放 memory
Backward pass (梯度)
- 对每个 FSDP unit,运行 all_gather 收集所有 rank 上的模型参数切片
- 执行反向计算
- 重新执行切片丢掉不属于当前 rank 的模型参数,释放 memory
- 执行 reduce_scatter,在不同的 rank 间同步梯度
Optimizer updates (优化器状态)
每个 rank 对属于自己的局部梯度的分片进行更新
FSDP 可以被视为 DDP 的 all-reduce 分解为 reduce-scatter 和 all-gather 的操作。

- 与 FSDP1 相比,FSDP2 的优点:
- 将分片参数表示为在 dim-i 上分片的 DTensor,从而可以轻松作单个参数、无通信分片状态字典 和 更简单的元设备初始化流程。
- 改进内存管理系统,通过避免
recordStream(doc) 实现更低且确定的 GPU 内存,并且能在没有任何 CPU 同步的情况下这样做。 - 提供张量子类扩展点来自定义 all-gather,例如,对于用于 float8 线性的 float8 all-gather 和 用于 QLoRA 的 NF4。
- 将 frozen 和非 frozen 参数混合到同一个通信组中,无需使用额外的内存。
FSDP 的使用
模型初始化
以一个小模型在 MNIST 数据集上运行训练以进行演示:
1.1 安装 PyTorch 和 Torchvision
1.2 导入必要包
1.3 分布式训练设置。
FSDP 是一种需要分布式训练环境的数据并行类型,因此这里我们使用两个辅助函数来初始化分布式训练的进程并进行清理。
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
2.1 定义用于分类手写数字的模型 Net()
2.2 定义训练函数 train()
2.3 定义验证函数 test()
2.4 定义一个用 FSDP 包装模型的分布式训练函数
[!IMPORTANT]
为了保存 FSDP 模型,我们需要在每个进程上调用 state_dict,然后在 Rank 0 上保存整体状态。
def fsdp_main(rank, world_size, args):
# 初始化分布式训练环境
setup(rank, world_size)
# 定义数据预处理变换
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL图像转换为Tensor
transforms.Normalize((0.1307,), (0.3081,)) # 标准化(MNIST数据集的均值和标准差)
])
# 加载MNIST训练集和测试集
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
# 为分布式训练创建采样器
# 训练集采样器,会打乱数据
sampler1 = DistributedSampler(dataset1, rank=rank, num_replicas=world_size, shuffle=True)
# 测试集采样器,不打乱数据
sampler2 = DistributedSampler(dataset2, rank=rank, num_replicas=world_size)
# 配置训练和测试的数据加载器参数
train_kwargs = {'batch_size': args.batch_size, 'sampler': sampler1}
test_kwargs = {'batch_size': args.test_batch_size, 'sampler': sampler2}
# CUDA相关的数据加载配置
cuda_kwargs = {'num_workers': 2, # 数据加载的线程数
'pin_memory': True, # 将数据固定在内存中加速传输到GPU
'shuffle': False} # 采样器已经处理了shuffle,所以这里设为False
# 合并参数
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
# 创建训练和测试数据加载器
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
# 定义FSDP的自动包装策略 - 当模块参数大于100时进行分片
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=100
)
# 设置当前使用的GPU设备
torch.cuda.set_device(rank)
# 创建 CUDA 事件用于计时
init_start_event = torch.cuda.Event(enable_timing=True)
init_end_event = torch.cuda.Event(enable_timing=True)
# 初始化模型并移动到当前GPU
model = Net().to(rank)
# 使用FSDP包装模型
model = FSDP(model)
# 定义优化器(Adadelta)和学习率调度器
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
# 开始计时
init_start_event.record()
# 训练循环
for epoch in range(1, args.epochs + 1):
train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=sampler1)
test(model, rank, world_size, test_loader)
scheduler.step() # 更新学习率
# 结束计时
init_end_event.record()
# 主进程(rank 0)打印训练时间和模型信息
if rank == 0:
init_end_event.synchronize()
print(f"CUDA event elapsed time: {init_start_event.elapsed_time(init_end_event) / 1000}sec")
print(f"{model}")
# 如果需要保存模型
if args.save_model:
# 使用屏障确保所有进程完成训练
dist.barrier()
# 获取模型状态字典
states = model.state_dict()
# 只有主进程保存模型
if rank == 0:
torch.save(states, "mnist_cnn.pt")
# 清理分布式训练环境
cleanup()
2.5 最后,解析参数并设置主函数
if __name__ == '__main__':
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
torch.manual_seed(args.seed)
WORLD_SIZE = torch.cuda.device_count()
# 使用多进程启动分布式训练
mp.spawn(fsdp_main, # 主训练函数
args=(WORLD_SIZE, args), # 传递给主训练函数的参数
nprocs=WORLD_SIZE, # 启动的进程数(等于GPU数量)
join=True) # 等待所有进程完成
用 FSDP 包装模型后,模型将如下所示,我们可以看到模型被包装在一个 FSDP 单元中:
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper( # FSDP 内部的一个辅助模块,用于扁平化参数
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): Linear(in_features=9216, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
)
auto_wrap_policy
- 背景:假设模型包含 100 个 Linear 层,
- 执行 FSDP(model) 只会有一个 FSDP 单元包装整个模型。在这种情况下,all-gather 会收集所有 100 个 Linear 层的全部参数,因此不会节省 CUDA 内存用于参数分片;
- 此外,对于所有 100 个 Linear 层只有一个阻塞的 all-gather 调用,层之间不会有通信和计算重叠。
解决方式:传入一个 auto_wrap_policy,当满足指定条件(如大小限制)时,它会自动密封当前 FSDP 单元并启动一个新的单元。
例如,有 5 个 FSDP 单元,每个单元包装 20 个 Linear 层。那么,在前向传播中,第一个 FSDP 单元会收集前 20 个 Linear 层的参数,进行计算,丢弃参数,然后继续处理接下来的 20 个 Linear 层。因此,在任何时间点,每个进程只实例化 20 个而不是 100 个 Linear 层的参数/梯度:
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=20000
)
torch.cuda.set_device(rank)
model = Net().to(rank)
model = FSDP(model,
auto_wrap_policy=my_auto_wrap_policy)
应用 auto_wrap_policy 后,模型将如下所示:
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): FullyShardedDataParallel( # fc1 嵌套封装 FSDP
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Linear(in_features=9216, out_features=128, bias=True)
)
)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
在 2.4 中,我们只需将 auto_wrap_policy 添加到 FSDP 包装器中:
model = FSDP(model,
auto_wrap_policy=my_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True))
DDP 中,每个进程都持有一个模型的副本,因此内存占用量更高;FSDP 将模型参数、优化器状态和梯度分片到 DDP 进程中,内存占用量更小。
使用带有 auto_wrap policy 的 FSDP 的峰值内存使用量最低,其次是 FSDP 和 DDP。
有关 DDP 和 FSDP 的详细分析和比较:请见博客。
使用 FSDP 进行高级模型的训练
以使用 FSDP 微调 HuggingFace (HF) T5 模型进行文本摘要为例:
FSDP 工作原理回顾
从高层次看,FSDP 工作流程如下:
在构造函数中
- 分片模型参数,每个 Rank 只保留自己的分片
在前向传播中
运行 all_gather 收集所有 Rank 的所有分片,以恢复此 FSDP 单元的完整参数,并运行前向计算
丢弃刚刚收集的非自身拥有的参数分片以释放内存
在反向传播中
运行 all_gather 收集所有 Rank 的所有分片,以恢复此 FSDP 单元的完整参数,并运行反向计算
丢弃非自身拥有的参数以释放内存。
运行 reduce_scatter 以同步梯度