工具链-强化学习
1. gym
官方文档:https://www.gymlibrary.dev
最小例子
CartPole-v0import gymenv = gym.make('CartPole-v0') env.reset() for _ in range(1000): env.render() env.step(env.action_space.sample()) # take a random action
观测 (Observations)
在 Gym 仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据标志位 done 的状态,来决定是否进行下一次回合。代码表示:
env.step() 函数对每一步进行仿真,返回 4 个参数:
观测 Observation (Object):当前 step 执行后,环境的观测(类型为对象)。例如,从相机获取的像素点,机器人各个关节的角度或棋盘游戏当前的状态等;
奖励 Reward (Float): 执行上一步动作(action)后,智体(agent)获得的奖励,不同的环境中奖励值变化范围也不相同,但是强化学习的目标就是使得总奖励值最大;
完成 Done (Boolen): 表示是否需要将环境重置
env.reset。
大多数情况下,当 Done 为 True时,就表明当前回合(episode)或者试验(tial)结束。例如当机器人摔倒或者掉出台面,就应当终止当前回合进行重置(reset);
- 信息 Info (Dict): 针对调试过程的诊断信息。在标准的智体仿真评估当中不会使用到这个 info。
总结来说,这就是一个强化学习的基本流程:在每个时间点上,智体执行 action,环境返回上一次 action 的观测和奖励。
空间(Spaces)
每次执行的动作(action)都是从环境动作空间中随机进行选取的.
在 Gym 的仿真环境中,有运动空间 action_space 和观测空间 observation_space 两个指标,程序中被定义为 Space类型,用于描述有效的运动和观测的格式和范围。
import gymenv = gym.make('CartPole-v0')
print(env.action_space)#> Discrete(2)
print(env.observation_space)#> Box(4,)
[33mWARN: gym.spaces.Box autodetected dtype as <class 'numpy.float32'>. Please provide explicit dtype.[0m
Discrete(2)
Box(4,)
注册表
Gym 是一个包含各种各样强化学习仿真环境的大集合,并且封装成通用的接口暴露给用户,查看所有环境的代码如下:
from gym import envsprint(envs.registry.all())
dict_values([EnvSpec(Copy-v0), EnvSpec(RepeatCopy-v0), EnvSpec(ReversedAddition-v0), EnvSpec(ReversedAddition3-v0), EnvSpec(DuplicatedInput-v0), EnvSpec(Reverse-v0), EnvSpec(CartPole-v0), EnvSpec(CartPole-v1), EnvSpec(MountainCar-v0), EnvSpec(MountainCarContinuous-v0), EnvSpec(Pendulum-v0), EnvSpec(Acrobot-v1), EnvSpec(LunarLander-v2), EnvSpec(LunarLanderContinuous-v2), EnvSpec(BipedalWalker-v2),...
Gym 支持将用户制作的环境写入到注册表中,需要执行 gym.make() 和在启动时注册 register,如:
register(
id='CartPole-v0',
entry_point='gym.envs.classic_control:CartPoleEnv',
max_episode_steps=200,
reward_threshold=195.0,
)
gym 基本函数接口
- make():生成环境对象
- reset():环境复位初始化函数。将环境的状态恢复到初始状态。
- env.state:查看环境当前状态。
- env.step():单步执行/智能体与环境之间的一次交互,即智能体在当前状态s下执行一次动作a,环境相应地更新至状态s’,并向智能体反馈及时奖励r。
- env.render():环境显示。以图形化的方式显示环境当前状态,在智能体与环境的持续交互过程中,该图形化显示也是相应地持续更新的。
- env.close():关闭环境。
- env.sample_space.sample(): 对动作空间进行随机采样。
- env.seed():指定随机种子。
2. stable-baselines3
强化学习资源:https://stable-baselines3.readthedocs.io/en/master/guide/rl.html
强化学习训练技巧:https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html
PPO 官方文档:https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html
1. PPO 源码阅读
train()
输入:使用预先收集的rollout buffer数据
输出:更新策略网络参数
核心操作:n_epochs 次的批量梯度更新,包含策略损失、值函数损失和熵正则项
def train(self) -> None:
"""
Update policy using the currently gathered rollout buffer.
"""
# 预处理
# train for n_epochs epochs
for epoch in range(self.n_epochs):
# 训练
# 策略评估
# 优势归一化
# PPO核心损失:
# 1. Clipped Surrogate Loss
# 2. 值函数损失
# 3. 熵正则项
# 多组件加权损失
loss = policy_loss + self.ent_coef * entropy_loss + self.vf_coef * value_loss
# Early Stopping
# Optimization step
self.policy.optimizer.zero_grad()
loss.backward()
# Clip grad norm
if not continue_training:
break
self._n_updates += self.n_epochs
explained_var = explained_variance(self.rollout_buffer.values.flatten(), self.rollout_buffer.returns.flatten())
# Logs 监控指标
预处理
- 动态学习率:
_update_learning_rate根据训练进度调整优化器学习率 - Clip范围计算:
- 策略网络clip范围
clip_range(随时间衰减) - 值函数clip范围
clip_range_vf(可选)
- 策略网络clip范围
# Update optimizer learning rate self._update_learning_rate(self.policy.optimizer) # Compute current clip range clip_range = self.clip_range(self._current_progress_remaining) # Optional: clip range for the value function if self.clip_range_vf is not None: clip_range_vf = self.clip_range_vf(self._current_progress_remaining) entropy_losses = [] pg_losses, value_losses = [], [] clip_fractions = [] continue_training = True- 动态学习率:
训练循环
策略评估、损失计算、参数更新
approx_kl_divs = [] # Do a complete pass on the rollout buffer for rollout_data in self.rollout_buffer.get(self.batch_size): actions = rollout_data.actions if isinstance(self.action_space, spaces.Discrete): # Convert discrete action from float to long actions = rollout_data.actions.long().flatten() # Re-sample the noise matrix because the log_std has changed # TODO: investigate why there is no issue with the gradient # if that line is commented (as in SAC) if self.use_sde: self.policy.reset_noise(self.batch_size)策略评估
计算当前策略下动作的价值估计、对数概率和熵
values, log_prob, entropy = self.policy.evaluate_actions(rollout_data.observations, actions)
values = values.flatten()
优势归一化
标准化优势值以稳定训练
advantages = rollout_data.advantages advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)PPO核心损失
Clipped Surrogate Loss:
# ratio between old and new policy, should be one at the first iteration ratio = th.exp(log_prob - rollout_data.old_log_prob) # clipped surrogate loss policy_loss_1 = advantages * ratio policy_loss_2 = advantages * th.clamp(ratio, 1 - clip_range, 1 + clip_range) policy_loss = -th.min(policy_loss_1, policy_loss_2).mean()值函数损失(支持clip):
if self.clip_range_vf is None: # No clipping values_pred = values else: # Clip the different between old and new value # NOTE: this depends on the reward scaling values_pred = rollout_data.old_values + th.clamp( values - rollout_data.old_values, -clip_range_vf, clip_range_vf) # Value loss using the TD(gae_lambda) target value_loss = F.mse_loss(rollout_data.returns, values_pred) value_losses.append(value_loss.item())熵正则项:
# Entropy loss favor exploration if entropy is None: # Approximate entropy when no analytical form entropy_loss = -th.mean(-log_prob) else: entropy_loss = -th.mean(entropy) entropy_losses.append(entropy_loss.item())
优化
Early Stopping:当近似KL散度超过阈值时终止训练
# Calculate approximate form of reverse KL Divergence for early stopping # see issue #417: https://github.com/DLR-RM/stable-baselines3/issues/417 # and discussion in PR #419: https://github.com/DLR-RM/stable-baselines3/pull/419 # and Schulman blog: http://joschu.net/blog/kl-approx.html with th.no_grad(): log_ratio = log_prob - rollout_data.old_log_prob approx_kl_div = th.mean((th.exp(log_ratio) - 1) - log_ratio).cpu().numpy() approx_kl_divs.append(approx_kl_div) if self.target_kl is not None and approx_kl_div > 1.5 * self.target_kl: continue_training = False if self.verbose >= 1: print(f"Early stopping at step {epoch} due to reaching max kl: {approx_kl_div:.2f}") break梯度裁剪
# Clip grad norm th.nn.utils.clip_grad_norm_(self.policy.parameters(), self.max_grad_norm) self.policy.optimizer.step()
监控指标
self.logger.record("train/entropy_loss", np.mean(entropy_losses)) self.logger.record("train/policy_gradient_loss", np.mean(pg_losses)) self.logger.record("train/value_loss", np.mean(value_losses)) self.logger.record("train/approx_kl", np.mean(approx_kl_divs)) self.logger.record("train/clip_fraction", np.mean(clip_fractions)) self.logger.record("train/loss", loss.item()) self.logger.record("train/explained_variance", explained_var) if hasattr(self.policy, "log_std"): self.logger.record("train/std", th.exp(self.policy.log_std).mean().item()) self.logger.record("train/n_updates", self._n_updates, exclude="tensorboard") self.logger.record("train/clip_range", clip_range) if self.clip_range_vf is not None: self.logger.record("train/clip_range_vf", clip_range_vf)
DummyVecEnv
序列化的环境封装类,实现了环境的自动reset
BaseAlgorithm
- 构造函数:初始化环境env
- _setup_learn函数:记录过程
- _setup_lr_schedule函数:用来适应learning rate可变的情况
- _update_learning_rate:记录 learning_rate
- 其他:实现了 save 和 load 函数
OnPolicyAlgorithm
继承自BaseAlgorithm,实现了环境中数据的获取collect_rollout,网络的初始化(_setup_model函数),以及训练的整体架构
- 构造函数:初始化
- collect_rollout():从网络中获得当前状态的 action、values 和 log_probs;进行一次 step;连续进行 n_rollout_steps 次,每次的结果存入 roll_buffer;最后使用 GAE 计算优势函数。
- learn():调用 collect_rollouts 与环境交互后更新参数,调用 train() 更新网络。
BasePolicy
Policy 网络通常是如下所示的结构,由一个特征提取器和全连接神经网络构成
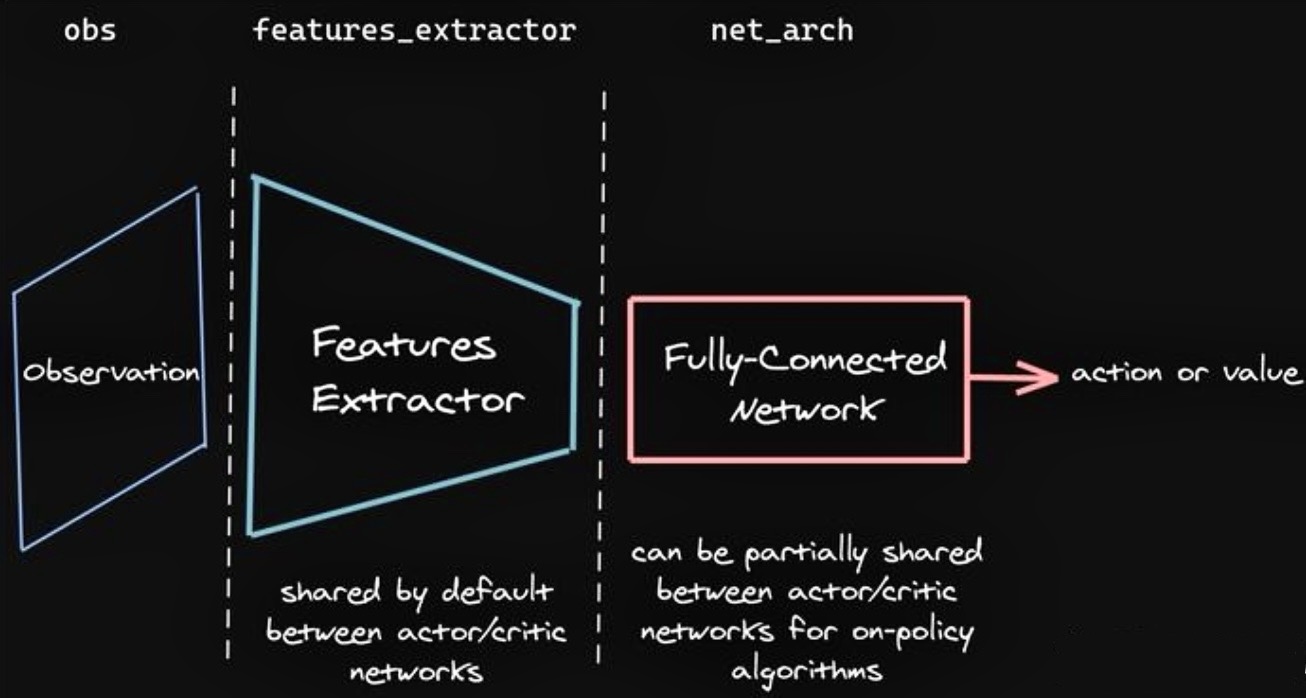
需要实现的虚函数: _predict函数(根据观测返回一个action)
ActorCriticPolicy
定义在 stable_baselines3.common.policies 里,输入状态,输出 value(实数),action(与分布有关),log_prob(实数)
实现具体网络的构造(在构造函数和 _build 函数中),forward 函数(一口气返回value, action, log_prob)和 evaluate_actions(不返回 action,但是会返回分布的熵)
_build_mlp_extractor 函数
需要定义 forward 函数(share_features_extractor 情况下), forward_actor 和 forward_critic 函数(不 share 的情况下)
如果想要定制中间层形状的话,可以传入 net_arch 参数自定义
BaseCallback
用来实时检测训练是否需要继续的类
common/policies.py - 实现特征提取
- 在 Stable Baselines3 的 PPO 中实现自定义特征提取网络:
- 定义自定义特征提取器类:继承
BaseFeaturesExtractor,并实现forward方法 - 配置 PPO 的 policy_kwargs
- 创建 PPO 模型并训练
- 定义自定义特征提取器类:继承
观测输入 (obs)
│
↓
preprocess_obs() # 图像归一化/转置
│
↓
features_extractor() # 自定义特征提取 (如输出256维)
│
↓
mlp_extractor() # 分离 latent_pi (Actor) 和 latent_vf (Critic)
│ # 示例:latent_pi=[256], latent_vf=[128]
├─→ actor_net() → 动作分布
└─→ value_net() → 值预测
BaseModel 基类
功能:模型基类,定义特征提取和预处理流程。
输入参数的 param features_extractor 即为 Network to extract features
特征提取器初始化:
def make_features_extractor(self) -> BaseFeaturesExtractor: return self.features_extractor_class(self.observation_space, **self.features_extractor_kwargs)->符号用于类型注解(type annotations),表示函数或方法的返回类型特征提取:
def extract_features(self, obs: th.Tensor) -> th.Tensor: # 预处理观测数据(如图像归一化) preprocessed_obs = preprocess_obs(obs, self.observation_space, normalize_images=self.normalize_images) # 调用特征提取器 return self.features_extractor(preprocessed_obs)
ActorCriticPolicy 类(核心策略类)
- 功能:
- 从观测数据中提取特征(通过自定义特征提取器)
- 生成动作分布(Actor 网络)
- 计算状态价值(Critic 网络)
- 支持多种动作分布(高斯分布、分类分布等)
- 支持状态依赖探索(gSDE)
- 网络架构定义
def __init__(self, ...): # 特征提取器(如自定义的CustomFeatureExtractor) self.features_extractor = features_extractor_class(...) self.features_dim = self.features_extractor.features_dim # 特征维度(如256)网络构建
def _build(self, lr_schedule): # 创建MLP提取器(分离Actor/Critic网络) self.mlp_extractor = MlpExtractor( self.features_dim, net_arch=self.net_arch, # 例如 pi=[256], vf=[128] activation_fn=self.activation_fn ) # 创建动作分布网络 if Gaussian分布: self.action_net, self.log_std = ... # 均值网络和log标准差 elif 分类分布: self.action_net = ... # 动作logits # 价值网络 self.value_net = nn.Linear(mlp_extractor.latent_dim_vf, 1) # 正交初始化权重 if self.ortho_init: for module in [特征提取器, MLP提取器, action_net, value_net]: module.apply(正交初始化)特征提取与推理
def _get_latent(self, obs): # 特征提取流程 features = self.extract_features(obs) # 自定义特征提取器 latent_pi, latent_vf = self.mlp_extractor(features) # Actor/Critic专用特征 return latent_pi, latent_vf, latent_sdedef forward(self, obs): latent_pi, latent_vf, _ = self._get_latent(obs) values = self.value_net(latent_vf) # 价值预测 distribution = self._get_action_dist_from_latent(latent_pi) # 动作分布 return actions, values, log_prob动作分布生成
def _get_action_dist_from_latent(self, latent_pi): mean_actions = self.action_net(latent_pi) # 通过Actor网络得到动作参数 # 根据分布类型生成最终分布 if 高斯分布: return 高斯分布(mean_actions, self.log_std) elif 分类分布: return 分类分布(logits=mean_actions) # ... 其他分布处理动作评估
def evaluate_actions(self, obs, actions): # 计算给定动作的对数概率和价值 latent_pi, latent_vf, _ = self._get_latent(obs) distribution = self._get_action_dist_from_latent(latent_pi) log_prob = distribution.log_prob(actions) values = self.value_net(latent_vf) return values, log_prob, entropy
- 功能: