微调
大模型预训练
1 从零开始的预训练
2 在已有开源模型基础上针对特定任务进行训练
LoRa
通过化简权重矩阵,实现高效微调

将loraA与loraB相乘得到一个lora权重矩阵,将lora权重矩阵加在原始权重矩阵上,就得到了对原始网络的更新。
训练参数量减少,但微调效果基本不变。
两个重要参数:

Lora 的优点:
- 大大节省微调大模型的参数量
- 效果和全量微调差不多。
- 微调完的Lora模型,权重可以Merge回原来的权重,不会改变模型结构,推理时不增加额外计算量。
- 你可以通过改变r参数,最高情况等同于全量微调。
大模型微调:SFT Trainer
SFT:Supervised Fine-Tuning
1 Chat Tempate
在预训练基础上,更好回答人类的问题。
- 网络结构:基本相同
- loss函数:基本相同
- 训练数据:不同
微调时,格式需要与原厂一致效果更好。
输入整个对话,对整个对话文本进行学习,对每个输出token计算loss。
2 Completions only
输入整个对话,对整个对话文本进行学习,只对回答部分进行loss计算。
用一个loss mask来实现,query部分不需要计算loss。
3 NEFTune:Noisy Embeddings Finetuning
图像领域的数据增强:通过旋转等操作生成更多样本。
对文本数据的增强:给每个token的embeding随机加上一些噪声,让原有token变成其他相近的token。如,漂亮变成了美丽。
大模型 + 强化学习

训练reward模型
训练需要的数据:用户偏好数据

reward模型:当前大模型的老师,能力要强于或差不多的当前的大模型。
预训练时训练大模型的能力极限,强化学习使其能力逼近极限。
将问答拼接在一起,分词后作为输入。输出字典维度和最后一个token的得分。
loss函数
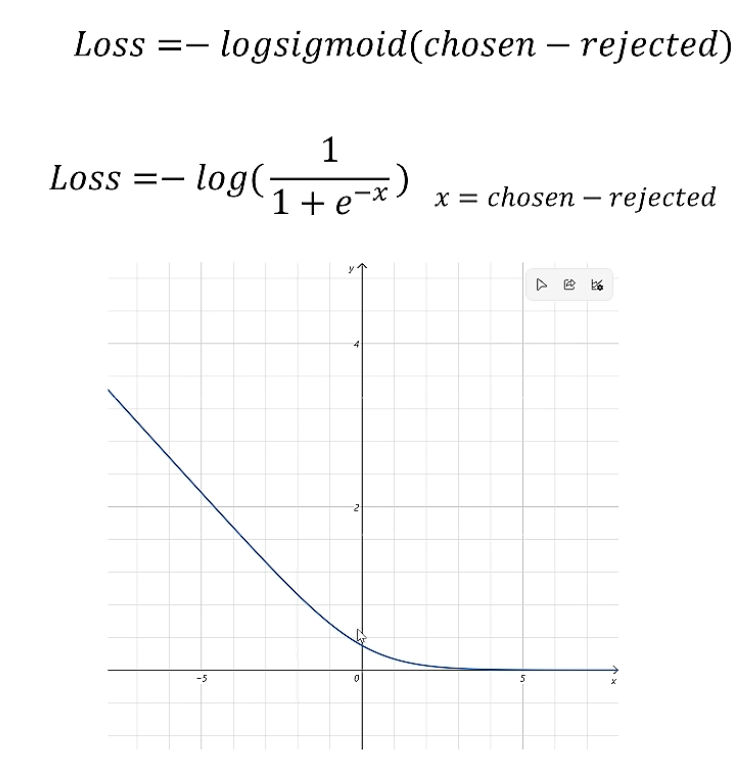
训练PPO
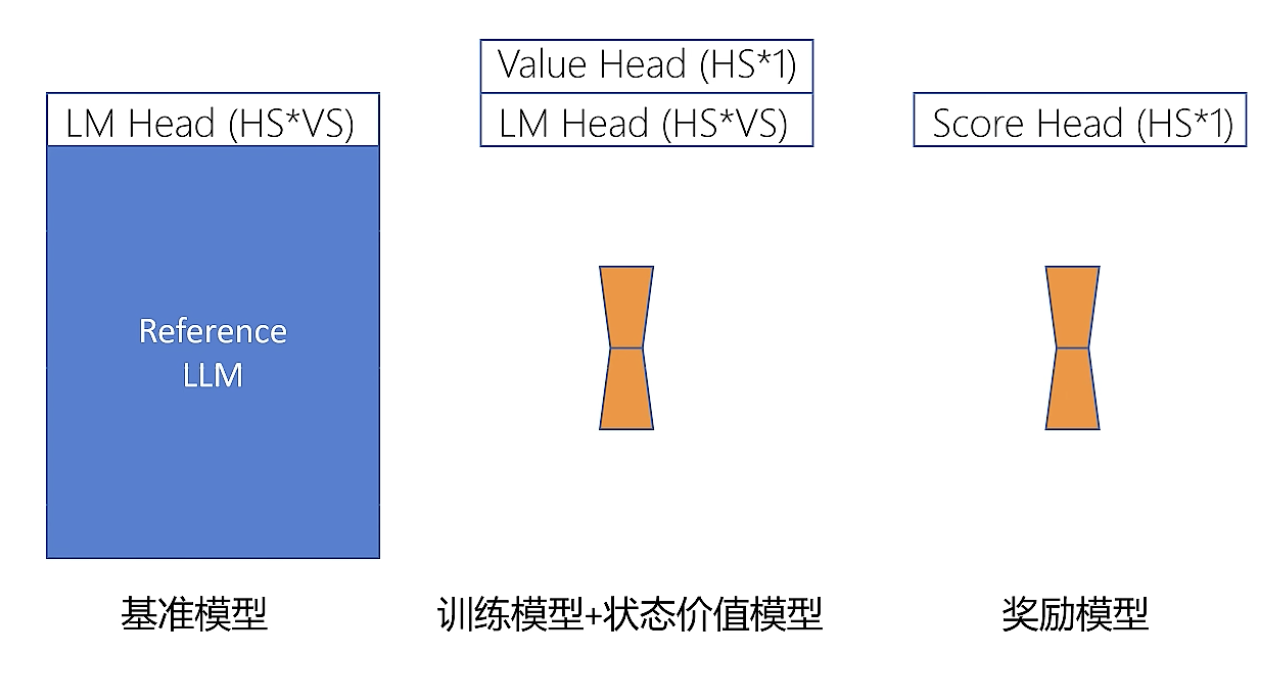
需要四个模型:

- 基准模型:前面输出的概率分布不能和基准模型相差太大。
- 训练模型:PPO的训练目标是优化训练模型
- 奖励模型:对一个问答序列进行评分
- 状态价值模型:对每个状态评估价值
可以将训练模型和状态价值模型合并。训练+状态价值模型 和 奖励模型 可以使用lora进行精简训练。
奖励模型是针对完整输出,给出一个得分。
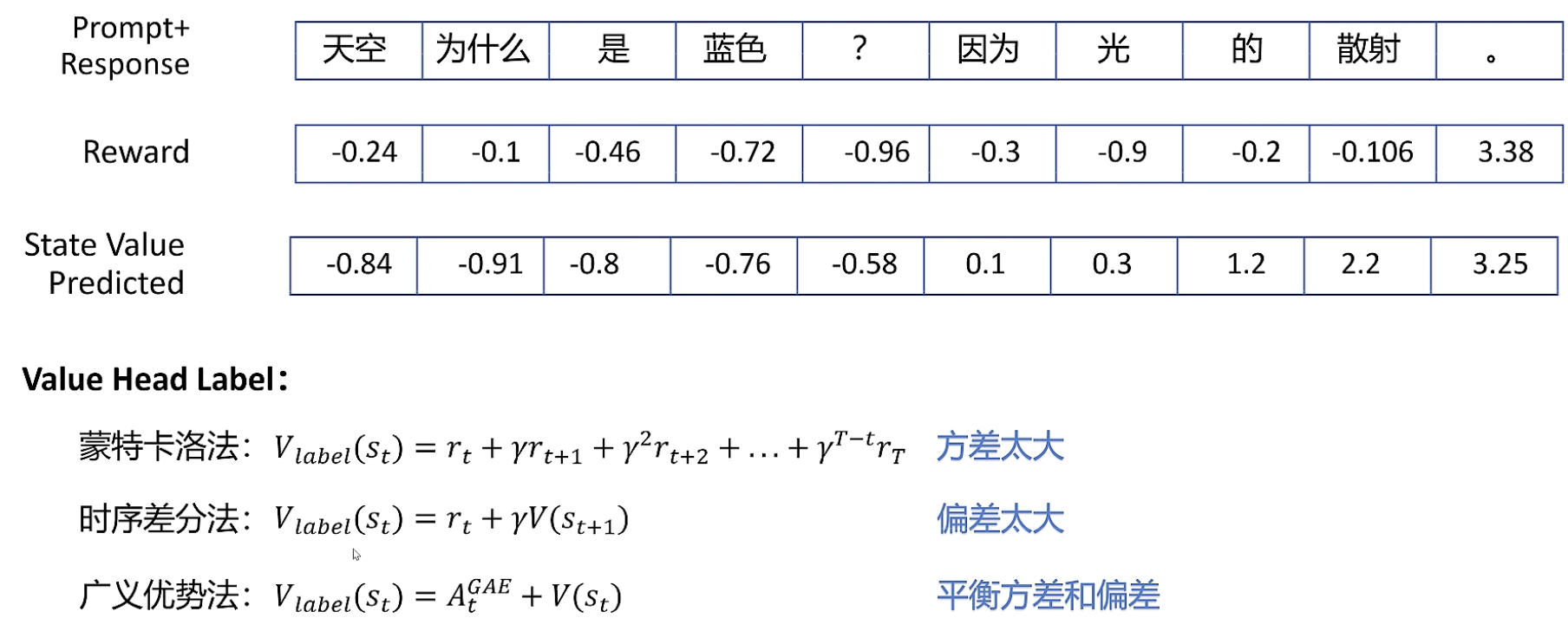
GAE优势函数的计算

状态价值的loss
PPO的loss
相比于之前,需要有所改进
