「论文阅读」KernelBench
KernelBench 是一个评估 LLMs 在生成高性能 GPU 内核代码上能力的基准测试框架。论文引入了新评估指标 fast_p:衡量生成的 正确、且速度提升超过阈值p 的内核的比例。
Introduction
背景:每个硬件都有不同的规格和指令集,跨平台移植算法是痛点。
论文核心探讨:LM 可以帮助编写正确和优化的内核吗?
KernelBench 的任务:让 LMs 基于给定的 PyTorch 目标模型架构,生成优化的 CUDA 内核;并进行自动评估。
环境要求
自动化 AI 工程师的工作流程。
支持多种 AI 算法、编程语言和硬件平台。
轻松评估 LM 代的性能和功能正确性,并从生成的内核中分析信息。
测试级别
Individual operations::如 AI 运算符、包括矩阵乘法、卷积和损失。
Sequence of operations:评估模型融合多个算子的能力。
端到端架构:Github 上流行 AI 存储库中的架构。
工作流程
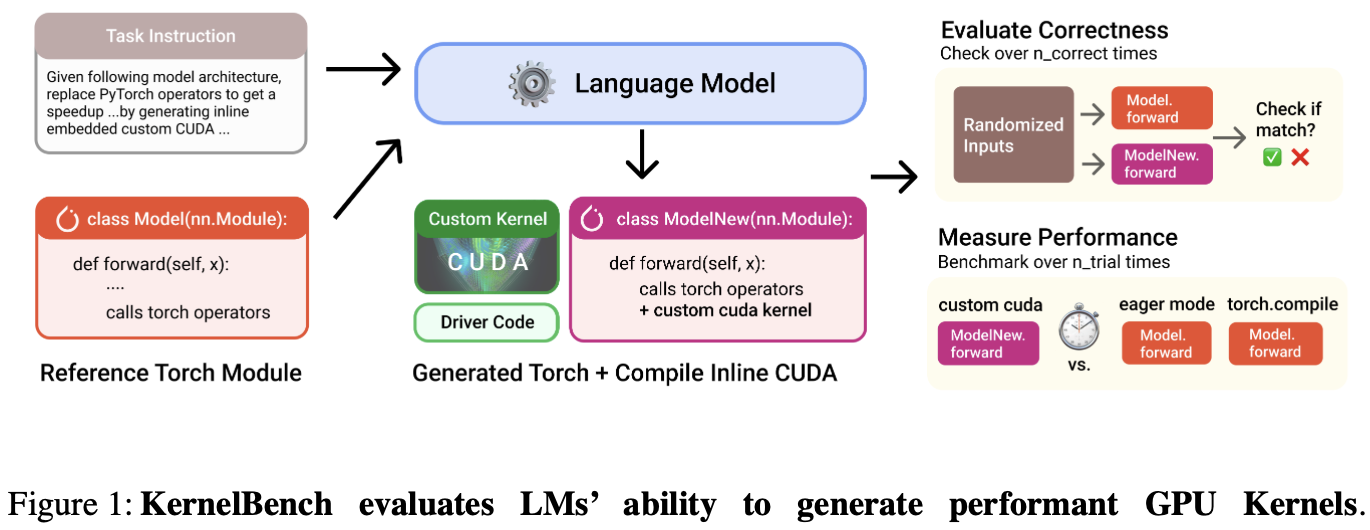
将 PyTorch 参考代码作为输入,并输出代码的优化版本。
LM 使用编译器和 Profiler 反馈进行迭代,以优化性能。
LM 可自由使用编程语言,并决定要优化 PyTorch 代码的哪些部分 以及如何优化。
可以向 LM 提供各种信息,包括特定于硬件的信息、示例内核和编译器/分析器反馈。
结论
- 编写功能正确的内核对模型来说仍然具有挑战性
- 模型可通过优化产生高性能内核
- 利用反馈可减少执行错误,发现更快的解决方案。
KernelBench
1. KernelBench 任务格式
任务输入
给定 AI 工作负载,任务的输入是用 PyTorch 编写的 Model 类。
任务输出
给定输入,LM 输出一个名为 ModelNew 的新类,其中包含自定义优化。如优化后的CUDA内核。
2. 任务选择
任务分为三个级别:
- Level 1(100 个任务):单个原始操作,如矩阵乘法、卷积、激活函数等。
- Level 2(100 个任务):操作序列,如卷积后接 ReLU 和偏置。
- Level 3(50 个任务):完整的机器学习架构,如 AlexNet 和 MiniGPT。
3. 设置评估指标
给定一个任务,KernelBench 随机生成规定形状和精度的输入张量,并收集 PyTorch 模型输出。然后,按如下方式评估 LM 的生成是否正确和快速:
评估方法
将 Model 的输出 与 LM 生成的 ModelNew 输出 进行比较。
- 正确性:每个问题使用五组随机输入,考虑:是否正确、内核输出值是否匹配、输出形状是否匹配,是否遇到运行时错误,是否出现编内核译错误。
- 性能:使用重复试验来考虑时序变化,比较了 Model 和 ModelNew 的壁钟执行时间。
fastp
为了捕获正确性和性能的两个轴,引入了名为 fastp 的新指标:定义为生成的内核在功能正确、且速度提升超过阈值p的任务比例。公式如下:
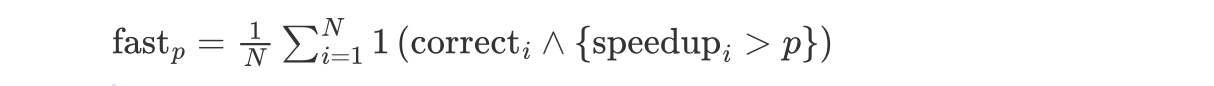
其中,fast$_{0}$表示内核功能正确的比例。
KernelBench 基线评估
1. One-shot 基线
使用一个提示来评估 LM,该提示包含 a PyTorch Model input 和 ModelNew output,并突出显示任务格式 的示例。
例如,可使用一个使用Tensor Cores的混合精度矩阵乘法(GEMM)的CUDA内核的示例。
实验结果:

2. 正确性:误差分析
正确性问题分为:
- 执行失败:CUDA/nvcc/Python 编译时错误、CUDA 内存违规和运行时错误
- 正确性错误(输出张量形状和值不匹配)
推理 LM(o1, R1) 产生的错误解 比其他模型少。所有 LM 正确性都不行。
3. 性能:加速分配
关键:正确的 LM 生成的内核是否优于 PyTorch 基线?

大多数 LM 生成的内核都很慢。基于推理的 LM 在提供加速方面通常优于其他 LM。
4. 不同硬件的性能差异
关键: LM 生成的内核的如何在各种 GPU 类型中泛化?
在不同GPU类型上,模型生成的核表现差异较大(特别是Level 2任务)。当今可用的最佳模型难以生成性能优于基准 PyTorch 速度的正确内核。
此外,LM 很难在给定简单指令的情况下编写跨硬件平台表现良好的内核。
模型能力分析
探索未来模型和 AI 系统的改进机会。
1. 在测试时利用 KernelBench 的环境反馈
KernelBench 提供的环境允许我们收集丰富的信号,包括编译器错误、正确性检查和运行时分析指标,所有这些都可以反馈给 LM 以帮助它解决内核故障。
- 如何利用:评估比较基线
- 每个 KernelBench 任务中,从 LM 生成多个并行样本
- 通过允许 LM 使用执行反馈迭代优化,按顺序为每个 KernelBench 任务生成内核。
1.1 重复采样
重复采样:对于每个任务,通过收集和评估多个 LM 的生成,使 LM 更快、更正确地发现解决方案。
使用 fastp@k进行评估:
从模型的输出分布中随机抽取 k 次,把这 k 个内核分别和 PyTorch 原生实现做性能对比 —— 这 k 个程序中至少有一个程序比 PyTorch Eager 快 p 倍的概率。

随着重复样本 k 数量的增加,DeepSeek-V3 和 Llama 3.1-70B Instruct 在所有 3 个 KernelBench 级别 fast1@k都有所改善。
1.2 迭代式生成优化
多轮生成与反馈:模型首先生成一个代码版本,系统提供以下信息帮助模型改进:
- G (Previous Generation):上一轮生成的代码。
- E (Compiler/Execution Feedback):编译/运行错误信息。
- P (Profiler Output):性能分析数据(如哪些代码段慢,瓶颈在哪里)。
模型基于反馈调整,生成新的优化版本。重复 N 轮,直到代码质量达标。

使用 fast p@N进行评估:
经过 N 轮优化后,模型是否能在至少一轮中生成比 PyTorch Eager 快 p 倍的正确代码。

利用执行反馈有助于减少错误,并随着时间的推移提高整体速度。
此外,通过检查迭代细化轨迹,模型能通过执行反馈 E 更有效地进行自我纠正。
2. 基于硬件知识生成高效内核
模型更擅长通过2.1的示例学习优化技巧,而非直接利用硬件信息。
2.1 硬件感知的上下文示例
在模型的输入中插入展示硬件优化技术的代码示例,引导模型模仿类似优化策略。
论文提供了三个上下文示例:GeLU + 算子融合、矩阵乘 + 分块(Tiling)、Flash-Attention内核。
- 负面影响:
- 模型尝试更激进的优化,失败率上升。
- 生成的代码平均长度增加25%(因包含复杂优化逻辑)。
- 正面影响:
- 在Level 1任务中,o1 应用分块优化提高了一次性基线的速度。
- 在Level 2任务中,模型成功应用共享内存优化,部分案例超越PyTorch Eager。
2.2 指定硬件信息
讨论:在生成高性能计算内核时,明确提供硬件信息是否能帮助 LMs 生成更优代码?
大多数生成的代码未针对特定硬件优化,说明未来模型有改进空间。o1 和 R1 偶尔生成异常高效的代码。
结论
- 提出KernelBench框架
- 评估了一组不同的模型,分析其优势和局限,并讨论改进的机会
未来机会
- 探索高级微调和推理技术的发展,包括智能体工作流。
- 开源更多高质量数据。
- 探索是否能改用高级编程抽象(如 ThunderKittens、CUTLASS、Triton 等)来生成代码,简化生成问题。
- KernelBench 分评估仅限于 GPU,未来的工作可扩展到其他硬件加速器。