语义分割
语义分割将图片中的每个像素分类到对应的类别。
应用:
背景虚化、路面分割、实例分割(会关注具体是哪个个体,如 Mask R-CNN)、全景分割(还要对背景进行分割,如 Panoptic FPN)
常见模型
语义分割任务常见的数据集格式
- PASCAL VOC:PNG图片 + 每个像素的类别信息(每个像素都对应一个颜色)
- MS COCO:每个目标都记录了一个多边形坐标,将所有的点连一起,即可得到边缘信息(还可以用于实例分析)
- 语义分割得到的具体形式:单通道图片,加上调色板 mask 蒙版后可以上色(palette),方便可视化。每个像素数值对应类别索引。
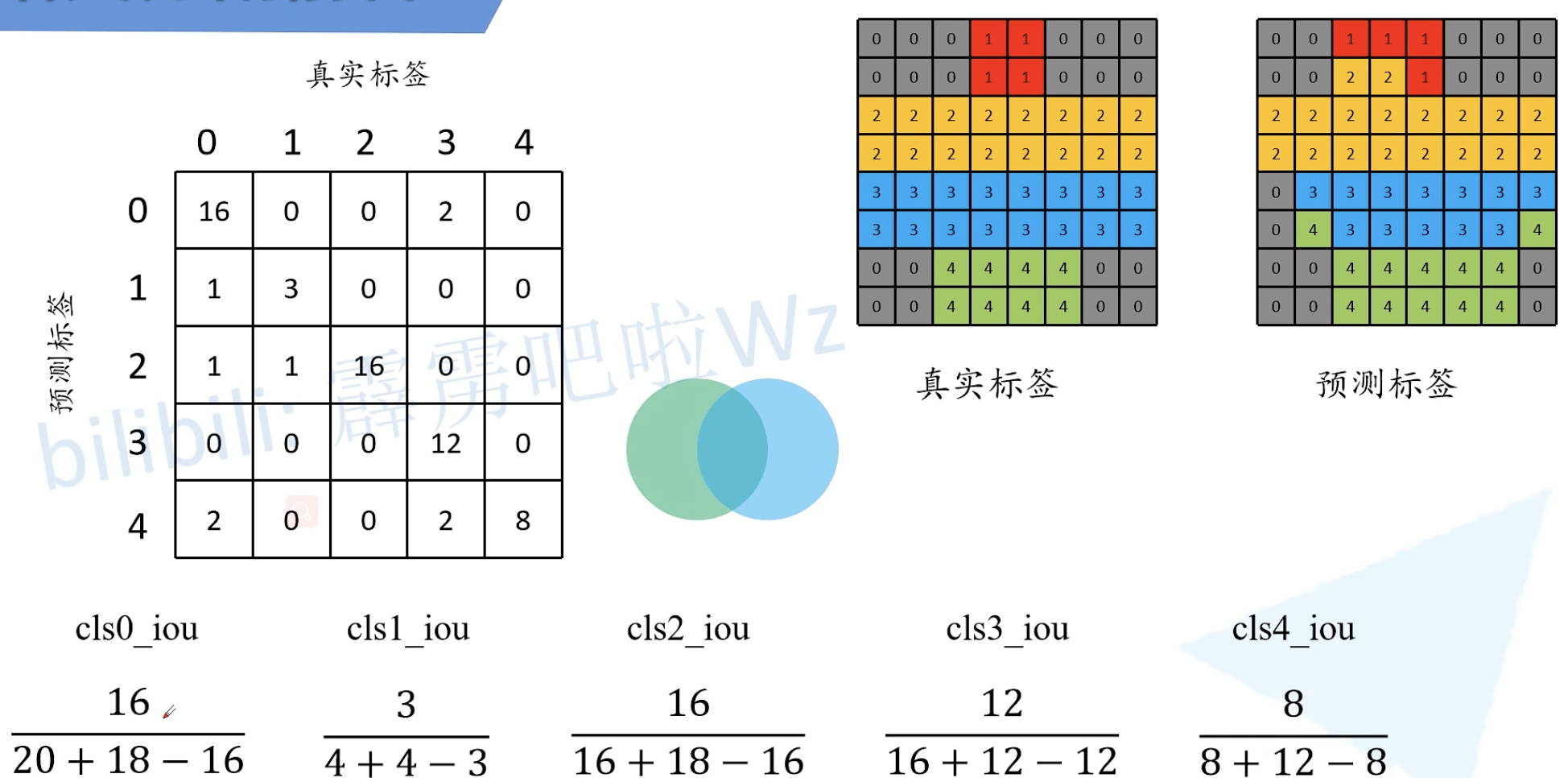
语义分割任务常见的评价指标
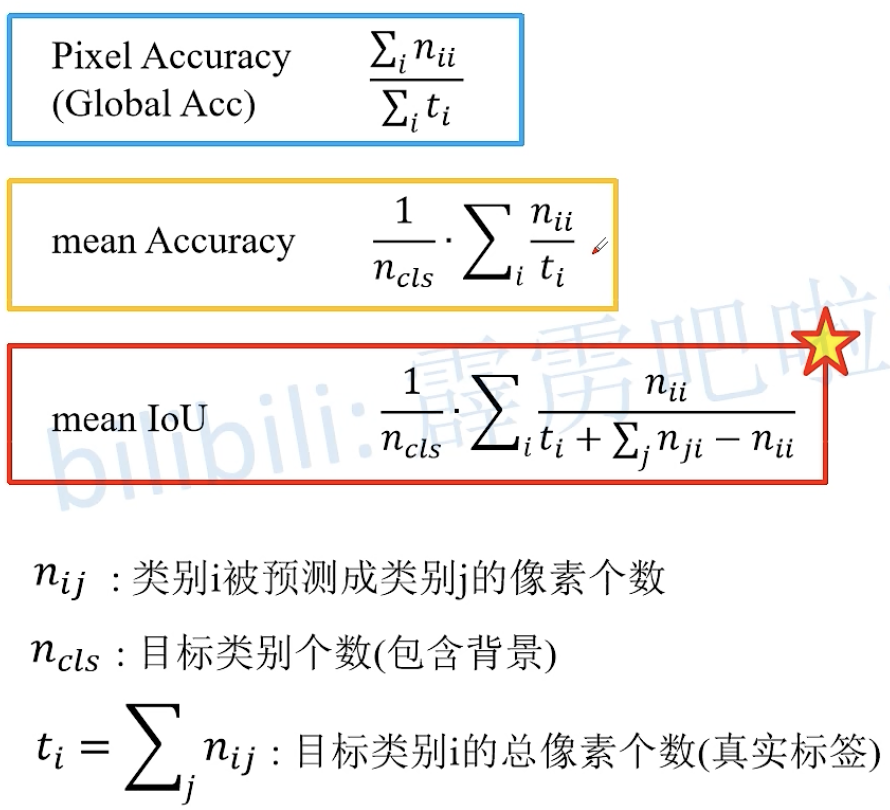
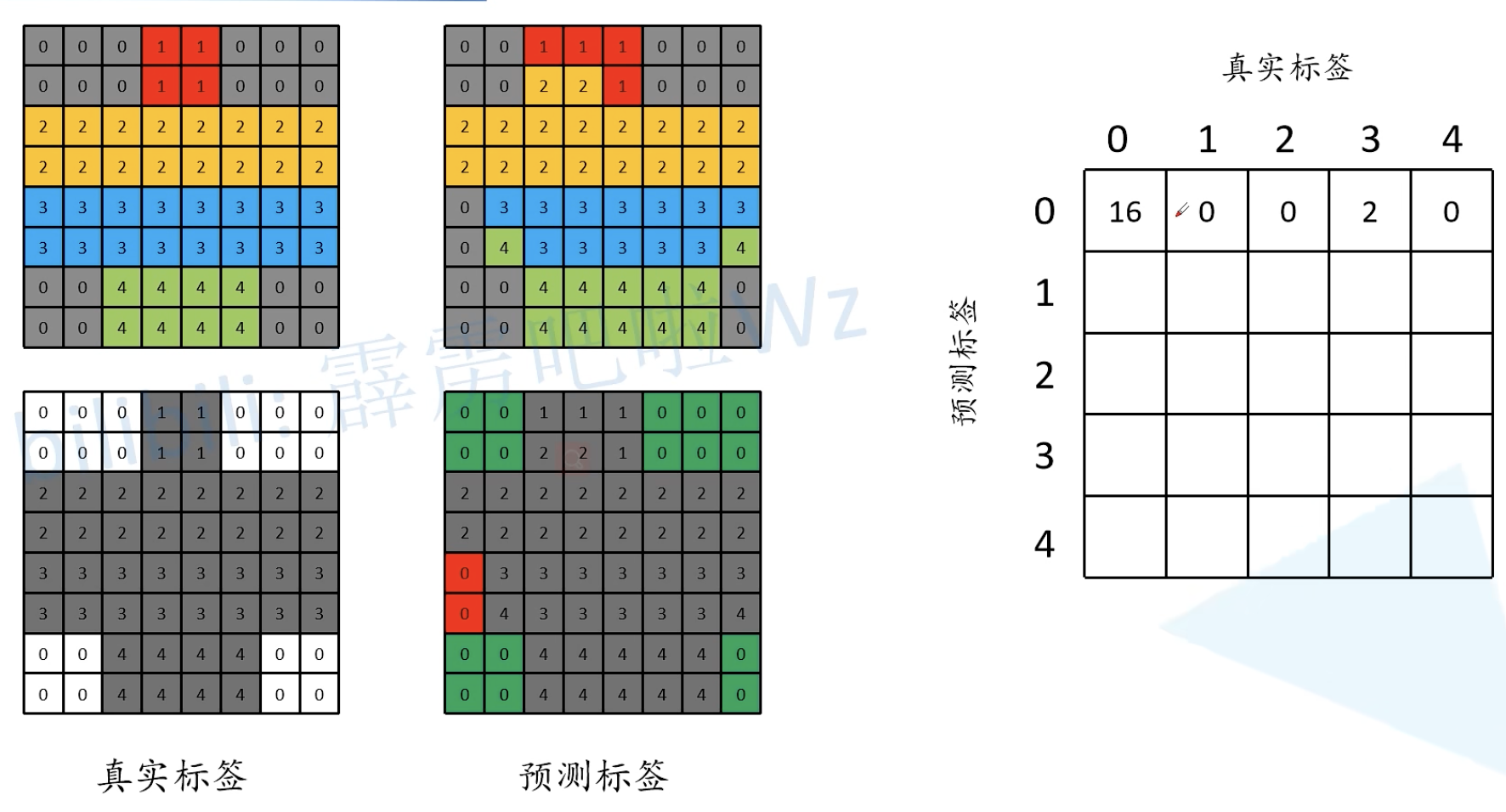
IoU:两个目标的面积交集比并集。
语义分割标注工具
Labelme:https://github.com/wkentaro/labelme
参考博文:https://blog.csdn.net/qq_37541097/article/details/120162702
ElSeg:https://github.com/PaddlePaddle/PaddleSeg
参考博文:https://blog.csdn.net/qq_37541097/article/details/120154543
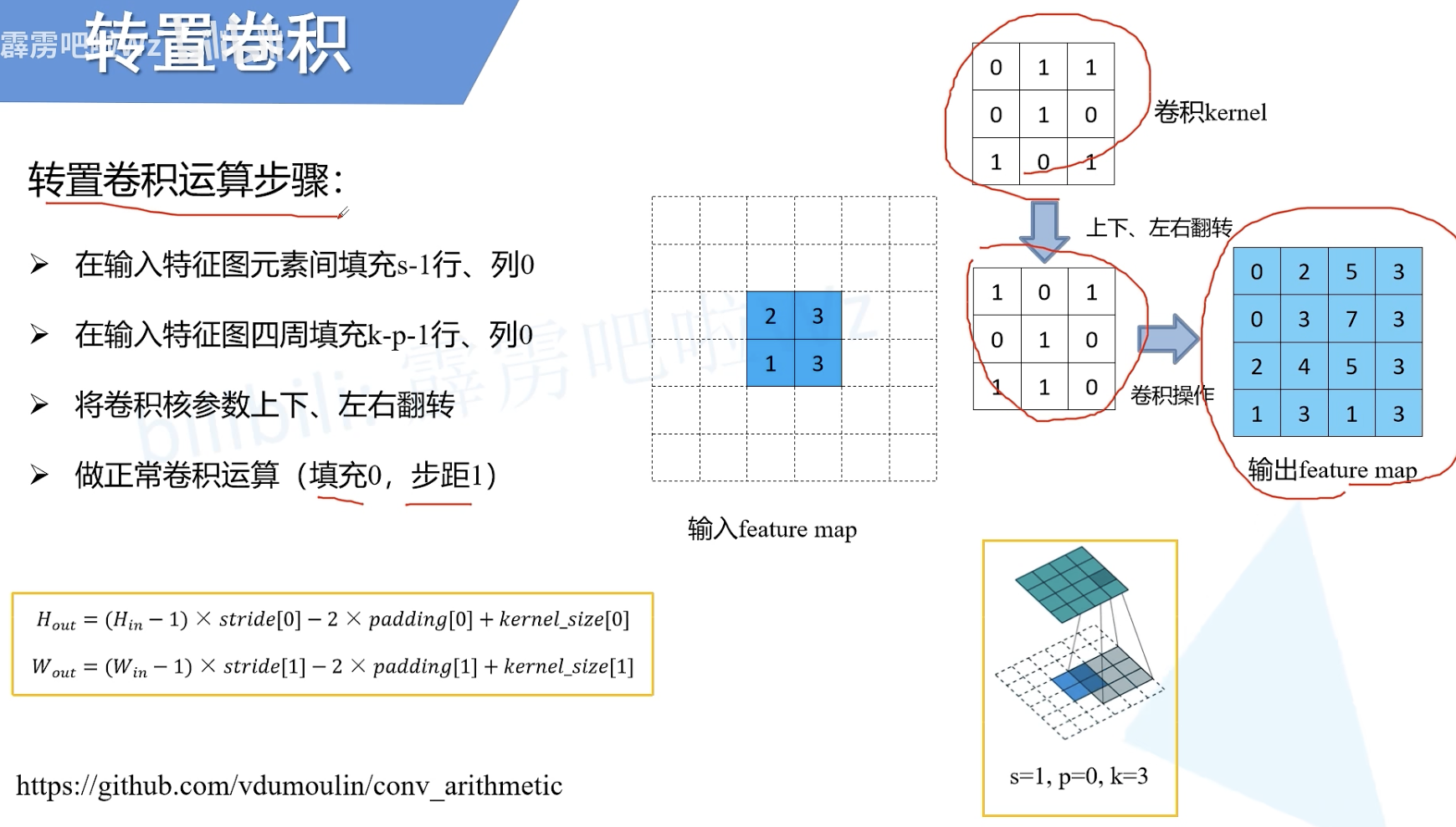
1. 转置卷积(Transposed Convolution)
A guide to convolution arithmetic for deep learning
又称:fractionally-strided convolution, deconvolution
作用:upsampling上采样,输出变大
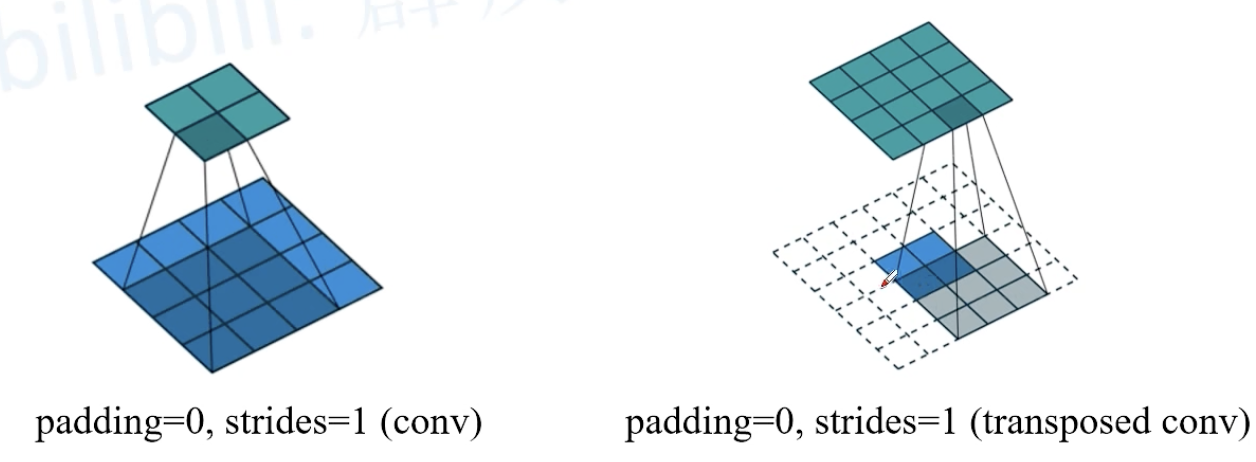
【注】转置卷积不是卷积的逆运算,转置卷积也是卷积
转置卷积运算步骤
s:stride 步长
k:kernel_size 卷积核大小
p:padding 填充
Hout:输出的高
Wout:输出的宽

例如
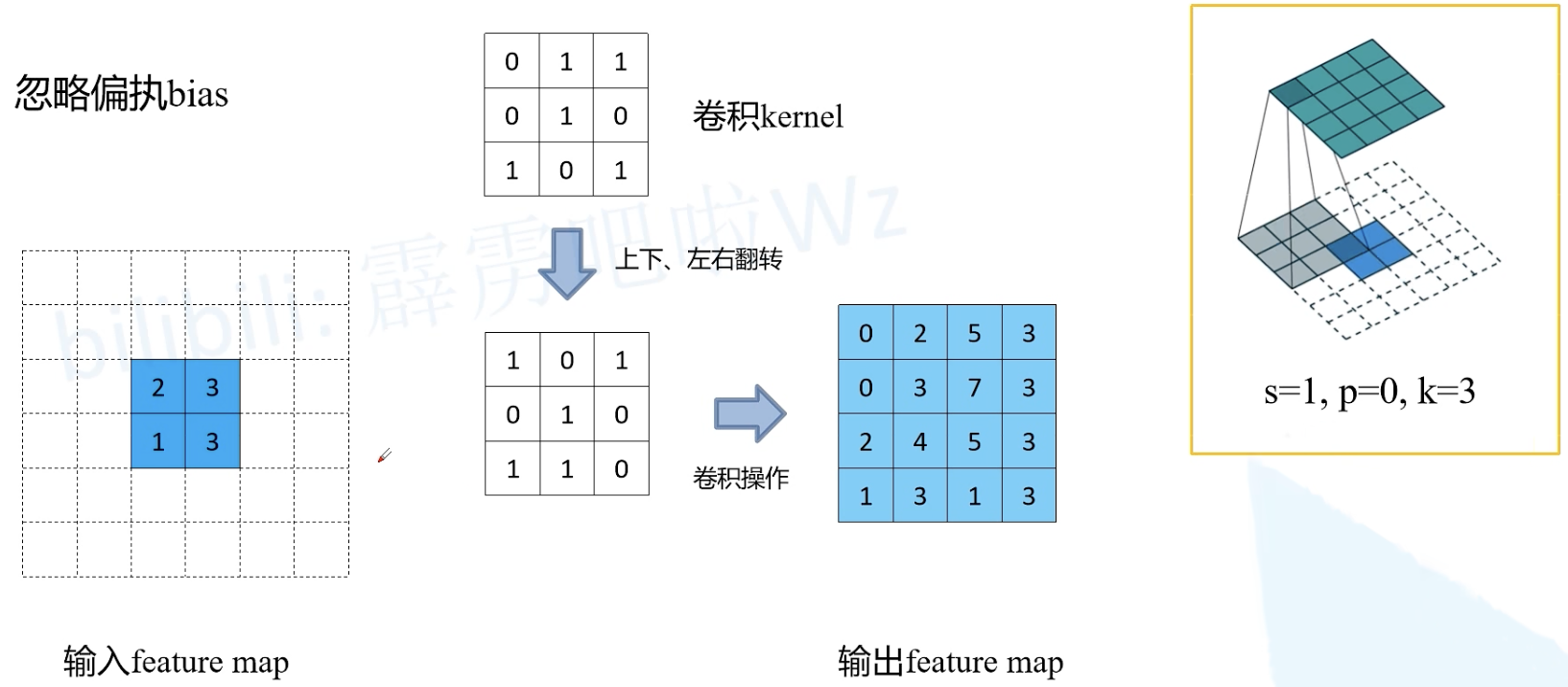

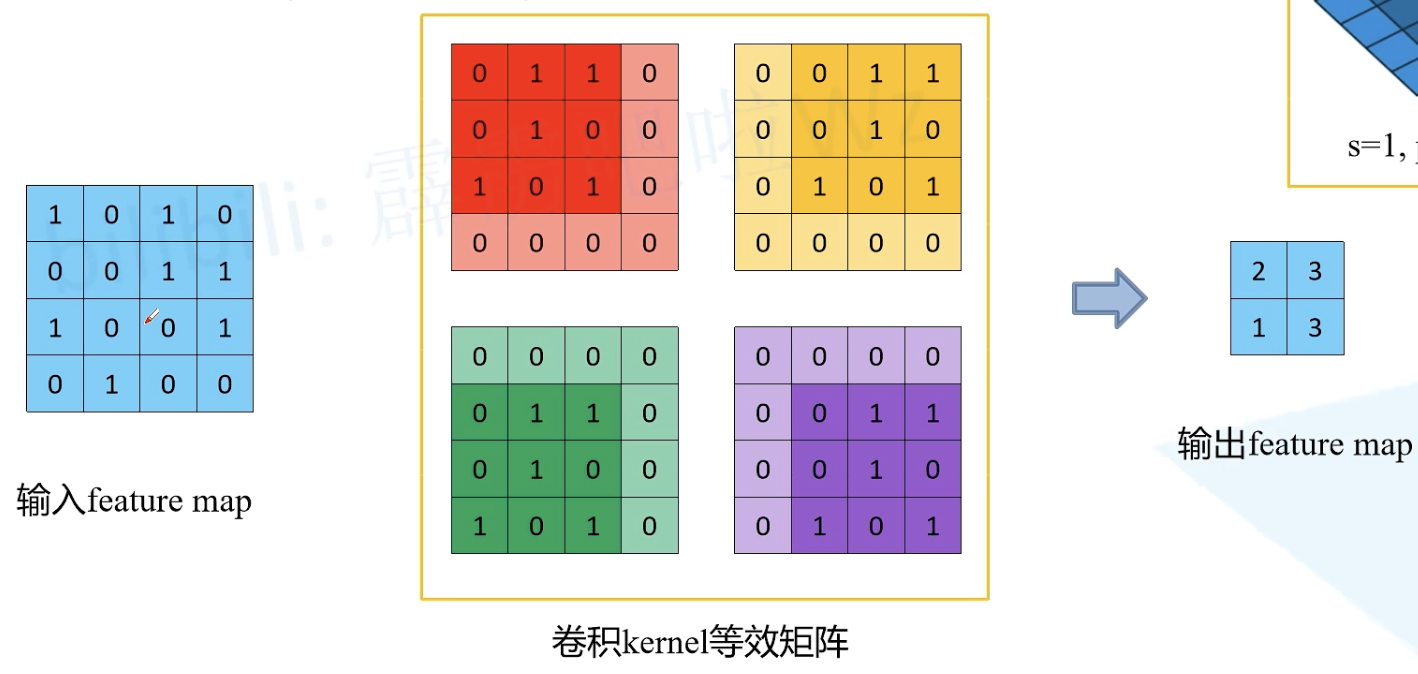
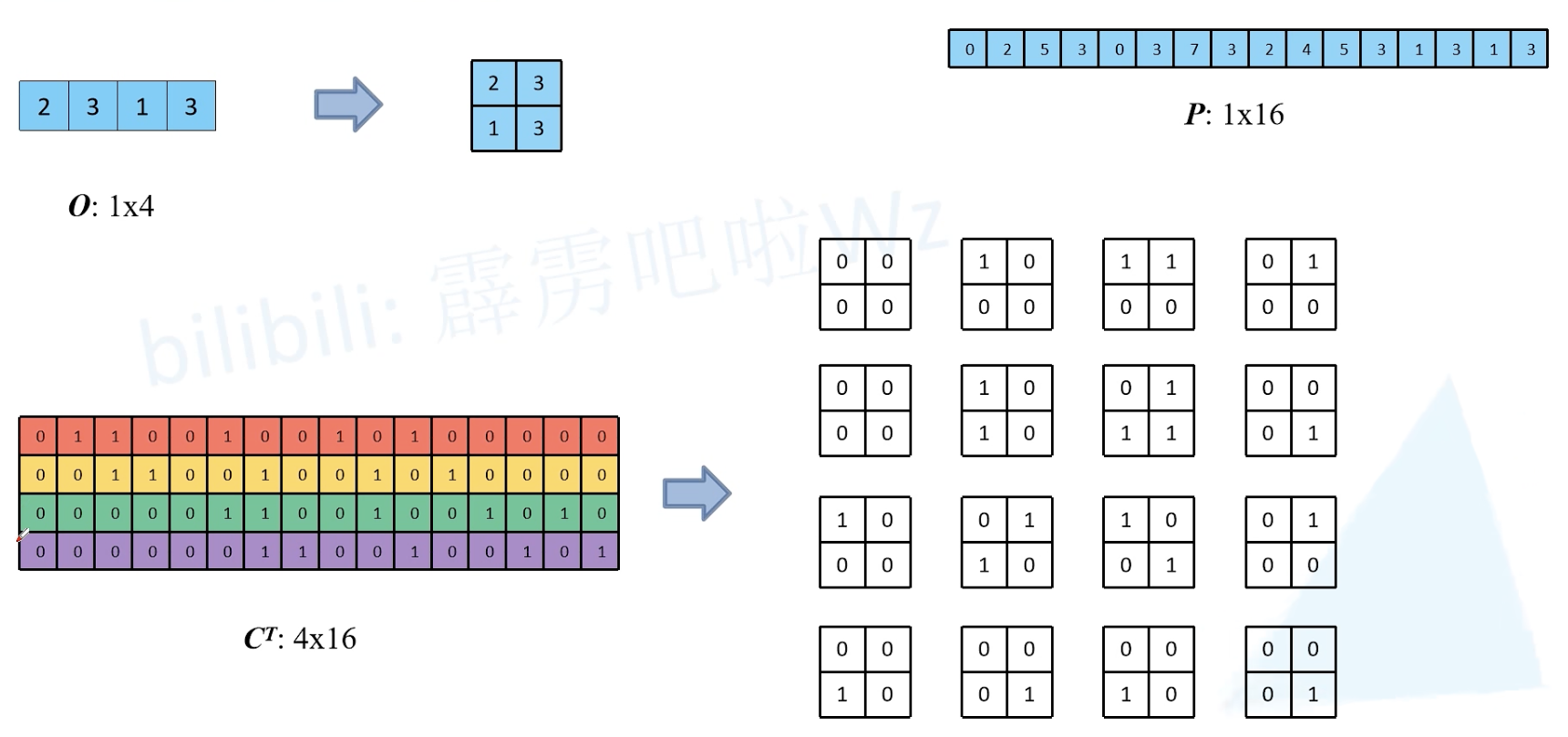
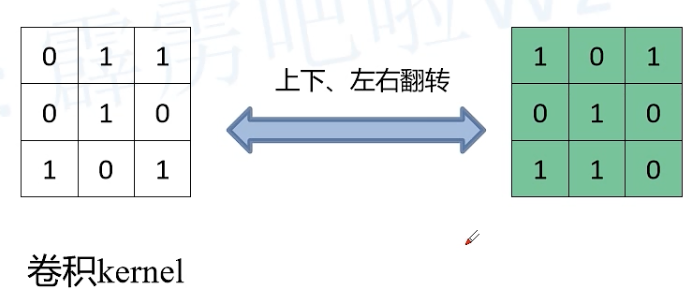
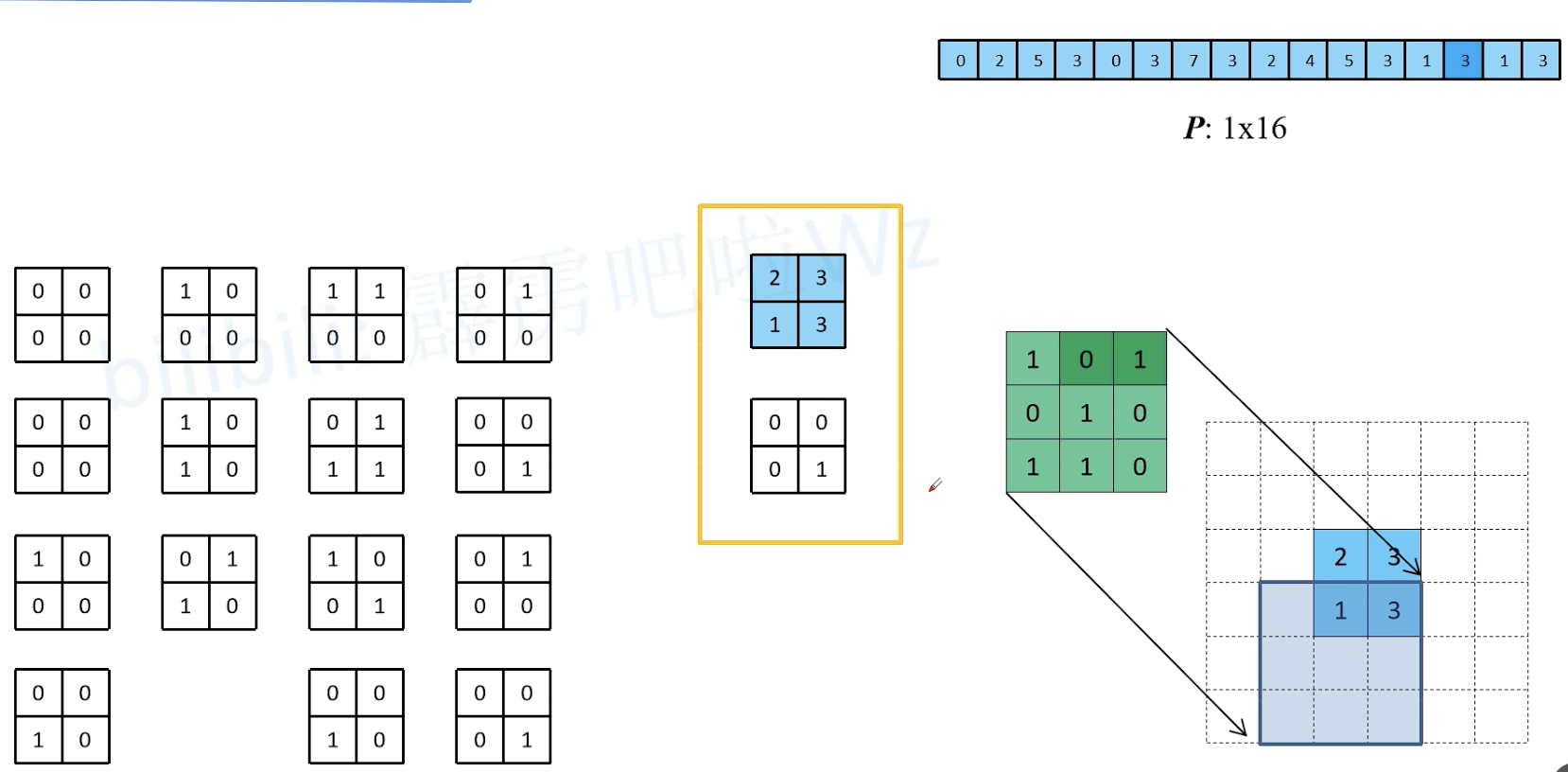
一种高效的卷积计算方式:kernel 等效矩阵
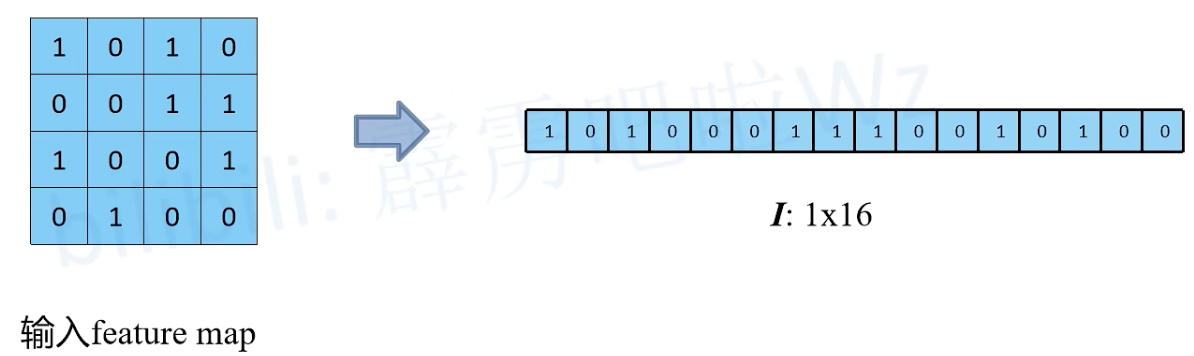
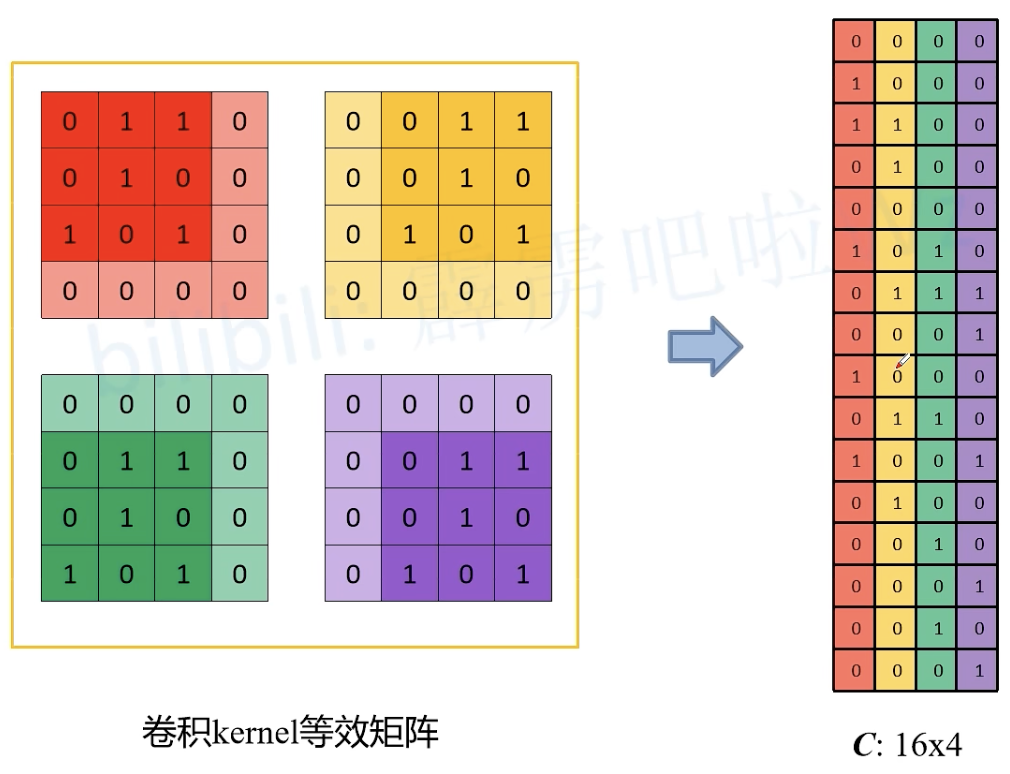
上采样
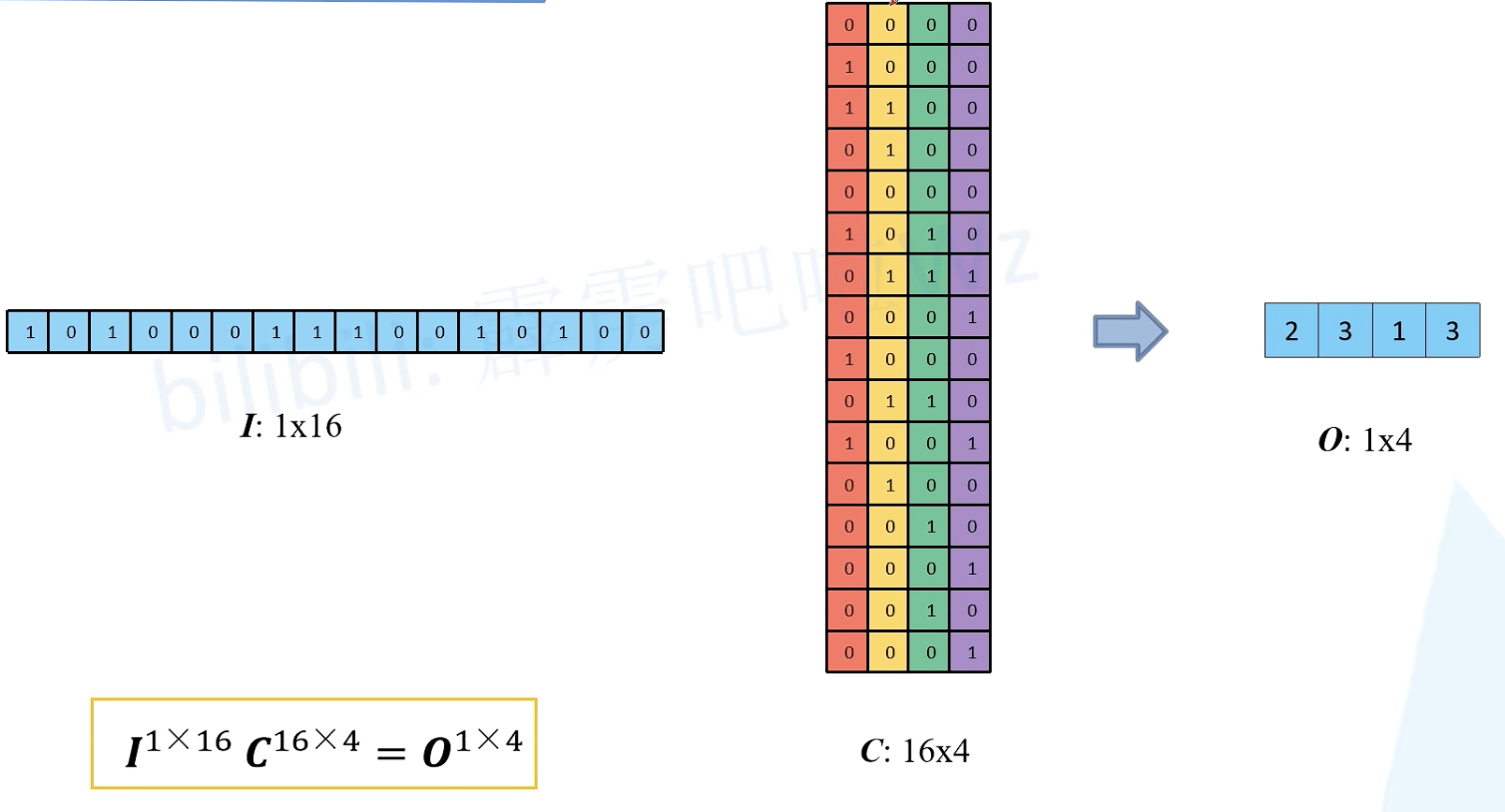
如何得到原始输入矩阵 I ?
C 秩小于 n,没有逆矩阵。O 无法直接乘 C 的逆矩阵还原得到 I。
如何得到与原始输入矩阵大小相同的矩阵 P ?
O 直接乘 C 的转置即可。
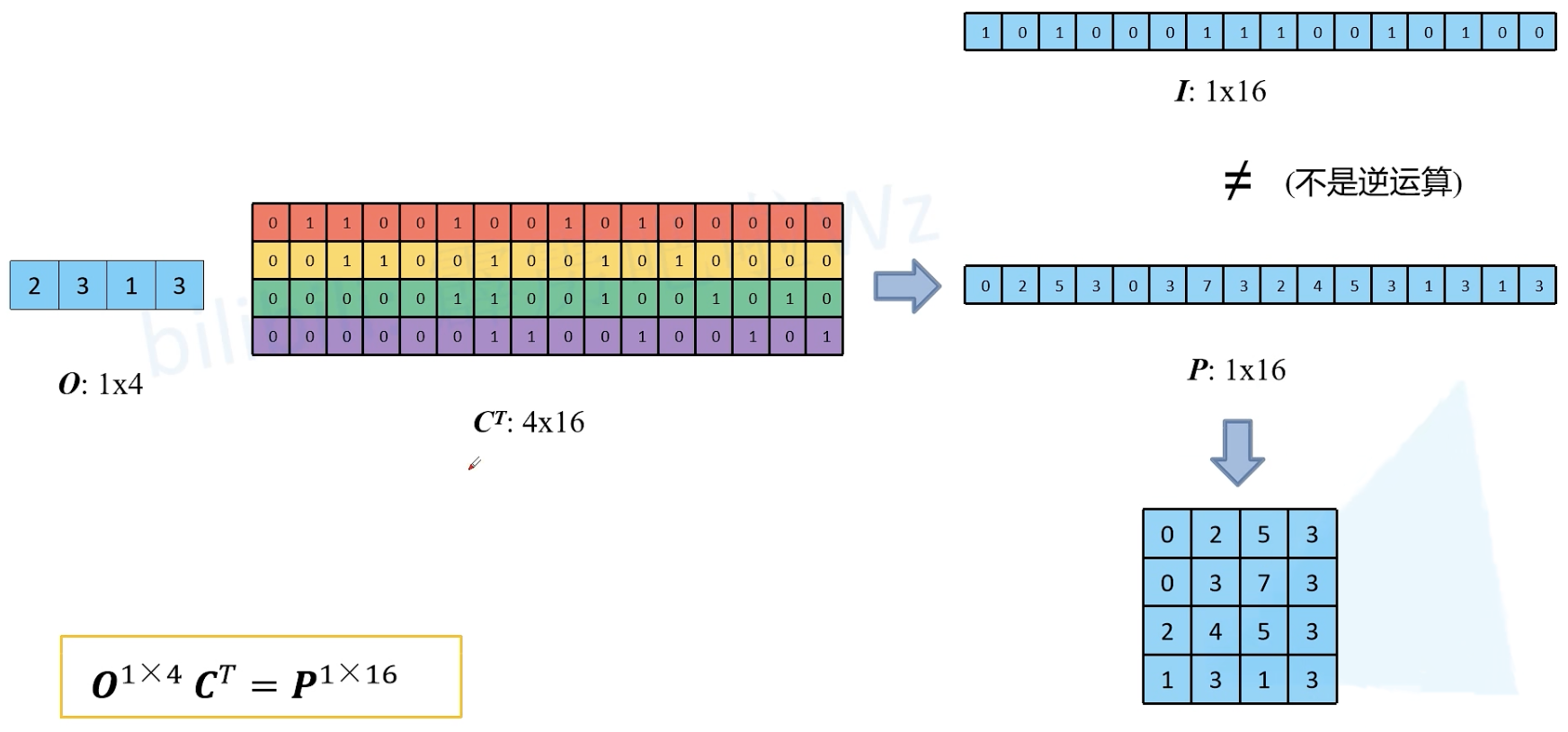
引入转置卷积
用卷积矩阵居然就可以达到同样效果了!
总结
- 转置卷积的作用:上采样
- 转置卷积不是逆运算
- 转置卷积也是一种卷积
2. 膨胀卷积(Dilated convolution)
又称:空洞卷积(Atrous convolution)
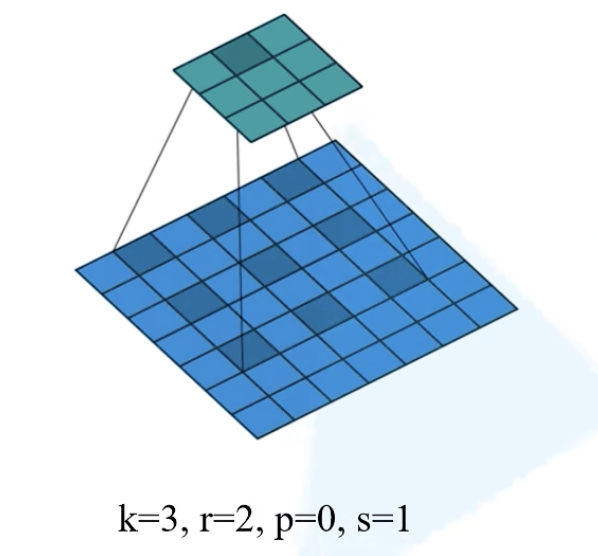
膨胀因子 r:元素之间的距离
- 作用:
- 增大感受野(即输出feature map上某个元素受输入图像上影响的区域);
- 保持原输入特征图 W、H
gridding effect 问题
没有运用到所有的像素值,只利用了一部分,会丢失一部分的信息
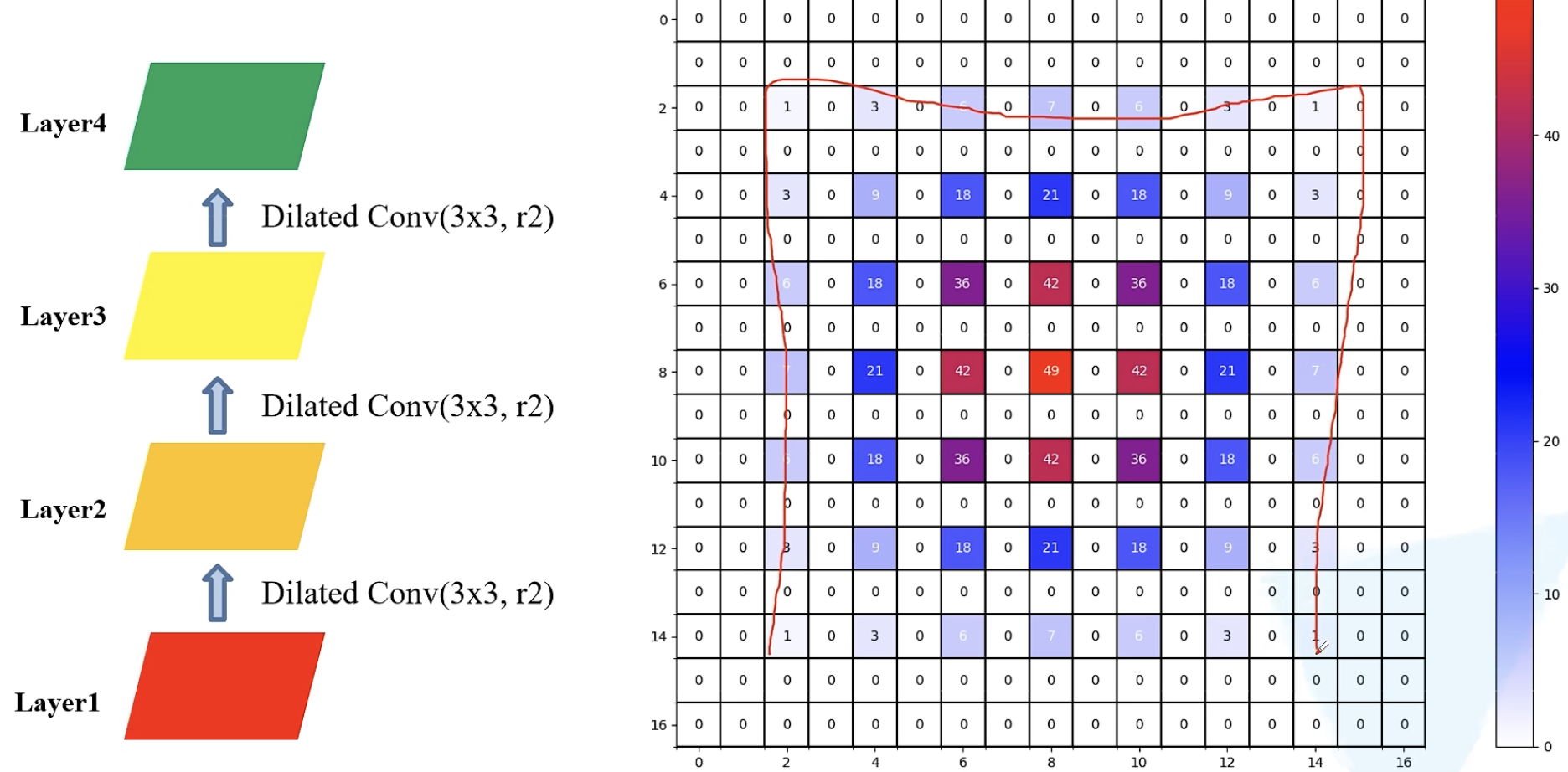
解决方法:使用不同的膨胀系数;在同样参数的情况下,感受野范围更大,且用到的像素连续。
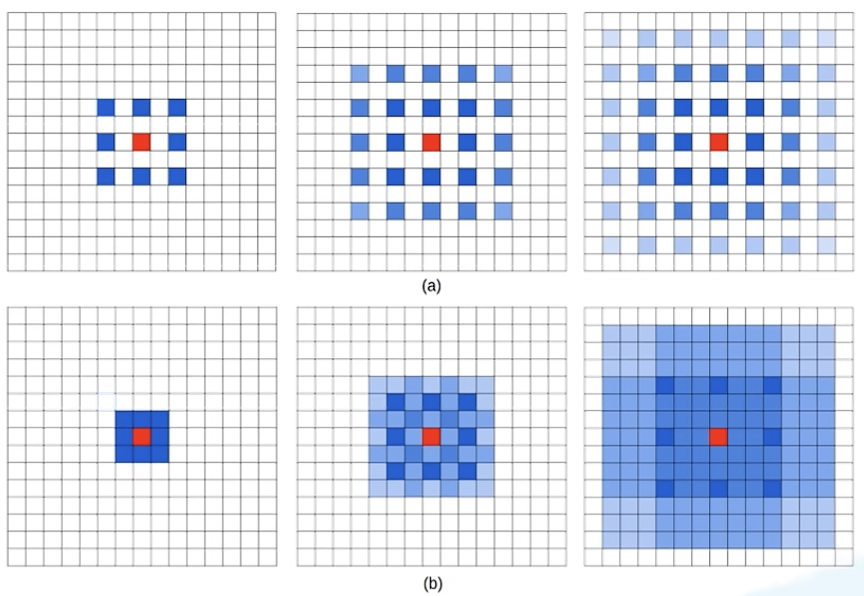
如何设置膨胀系数 (dilation rates)
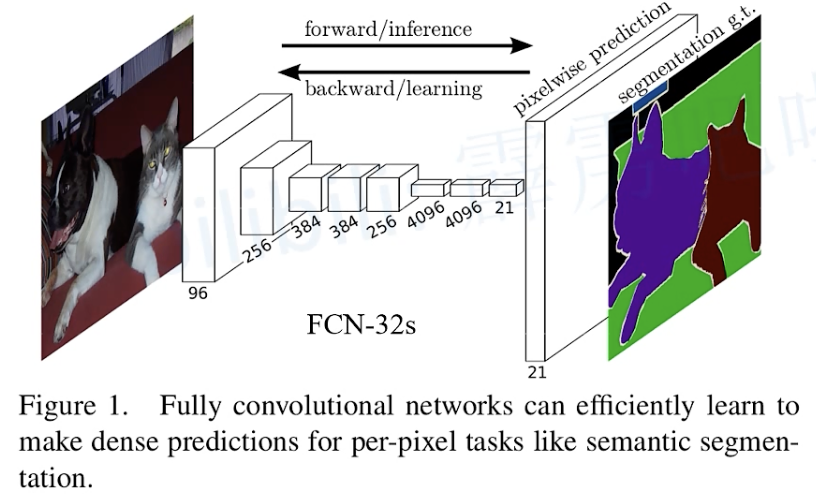
3. Fully Convolutional Networks
首个端到端的针对像素级预测的全卷积网络。
4. DeepLab
1. DeepLab V1
论文地址:https://arxiv.org/abs/1412.7062
博文推荐:https://blog.csdn.net/qq_37541097/article/details/121692445
- 语义分割任务中存在的问题
- 下采样导致图像分辨率降低
- 空间不敏感/空间不变性
- 解决方式
- 空洞卷积/ 膨胀卷积/ 扩张卷积
- fully-connected CRF (Conditional Random Field)
- DeepLab V1 网络优势
- 速度更快,论文中说是因为采用了膨胀卷积的原因,但 fully-connected CRFs 很耗时
- 准确率更高,相比之前最好的网络提升了7.2个点
- 模型结构简单,主要由 DCNNs 和 CRFs 联级构成
2. DeepLab V2
3. DeepLab V3
5. skip connection
初衷:解决gradient vanished
由于 gradient 通常是小于 1 的数值,当层数很多的时候,gradient 就会变得越来越小。(使用链式法则时,我们必须在向后移动时保持将项与误差梯度相乘。然而,在长长的乘法链中,如果我们将许多小于 1 的事物相乘,那么得到的梯度将非常小)最终,出现 gradient vanish 的问题 —— 当 gradient 无限接近于0,网络就没有办法更新学习了。
除了梯度消失之外,我们通常使用它们还有另一个原因。对于大量的任务(例如语义分割、光流估计等),有一些信息是在初始层中捕获的,我们希望允许后面的层也从中学习。在前面的层中,学习到的特征对应于从输入中提取的较低语义信息。如果我们没有使用 skip 连接,该信息就会变得过于抽象。
思路
在深度网络的中间层额外加入浅层的 input,使得 gradient 的“路径”不再那么长。类似提供一个复合路径,在原来的“长路径”的基础上,现在额外添加一个“捷径”。
skip connection 在本质上是额外提供一个计算 gradient 的捷径。
实现方式
addition
来源于 ResNet
使用残差块 residual block(RB):把 residual block 里的网络看做一个函数 F(x) ,在 addition 的部分 (+x) 为求 gradient 提供了一条捷径 。
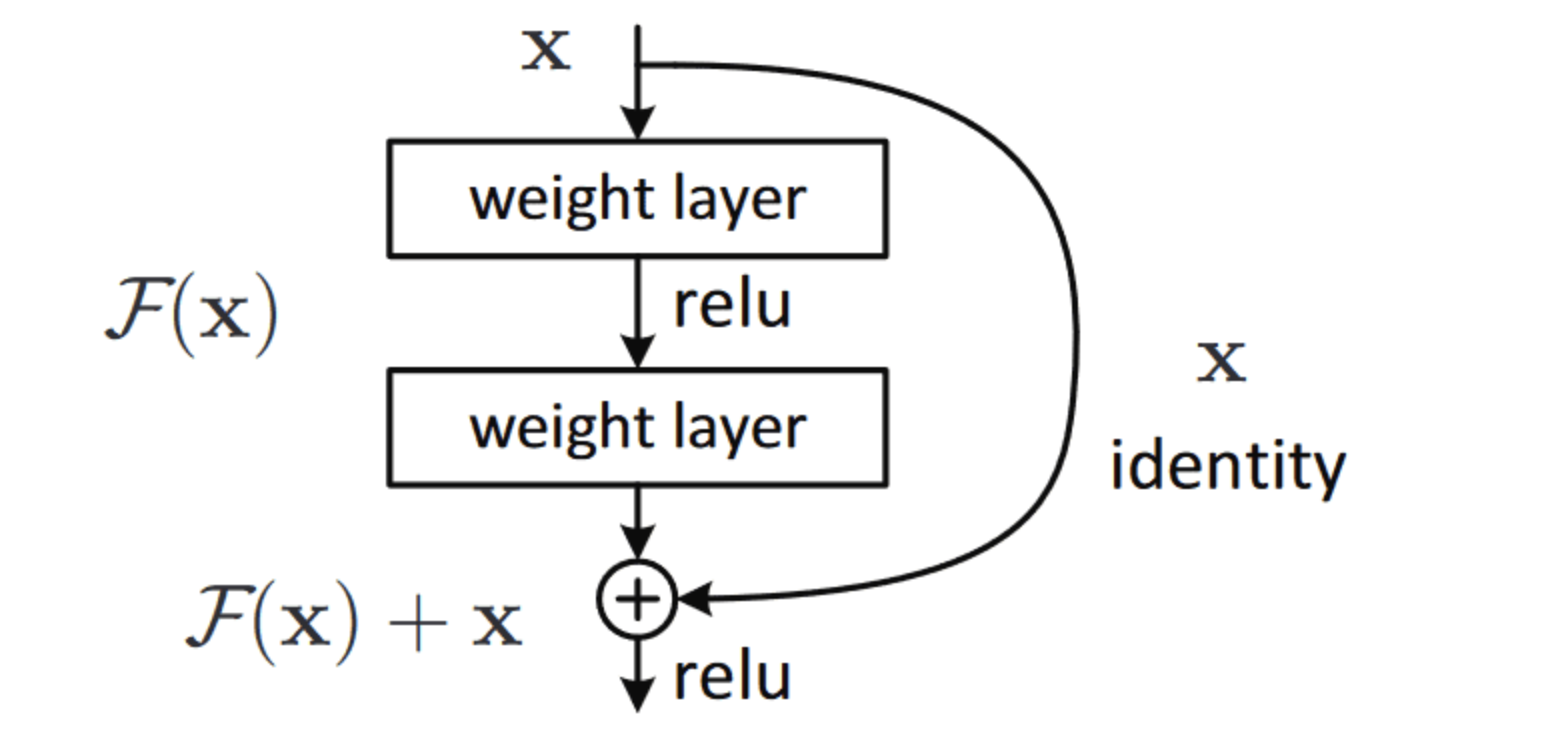
计算其偏导数
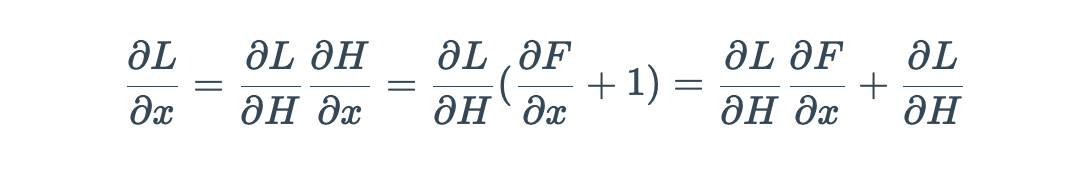
concatenation
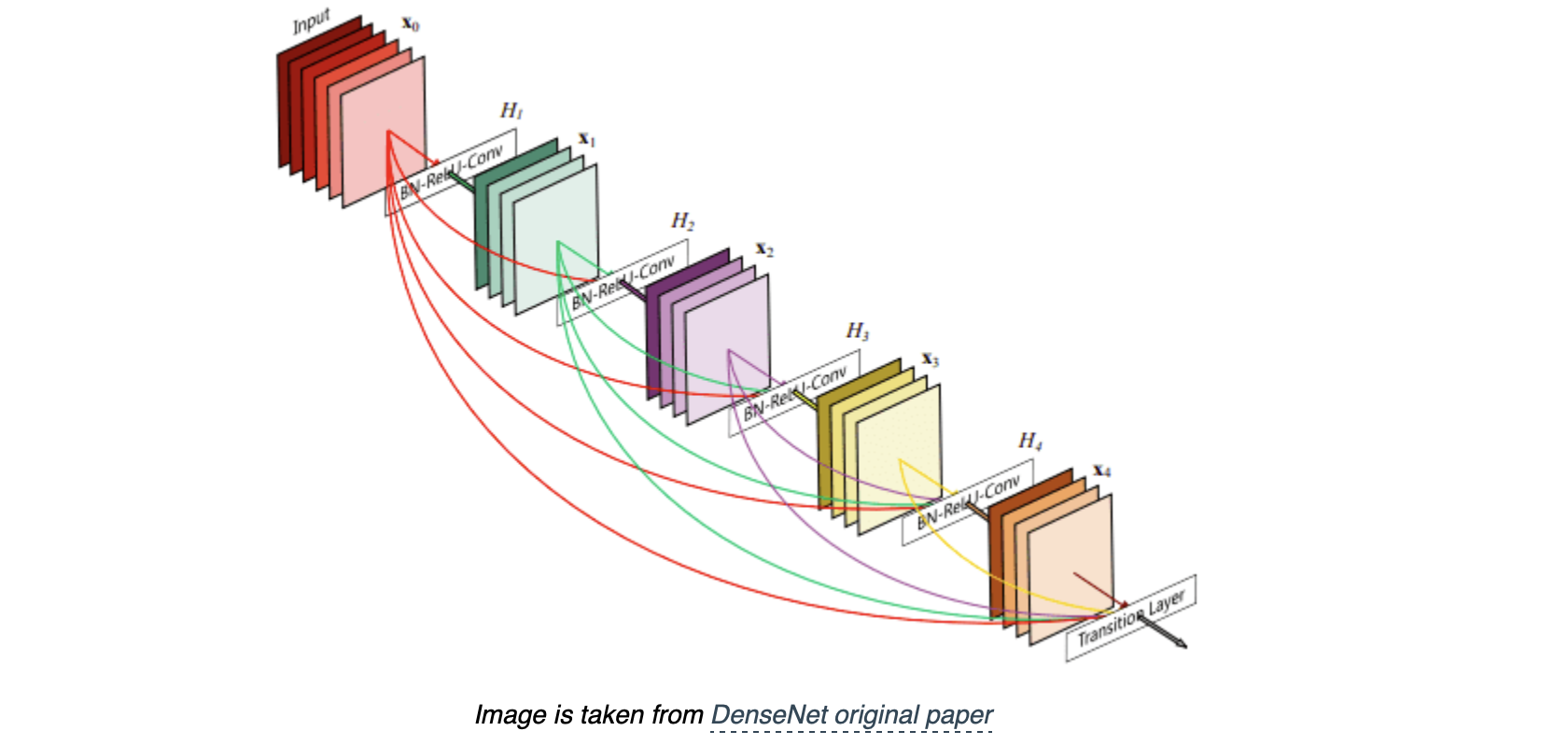
来源于 DenseNetconcatenation
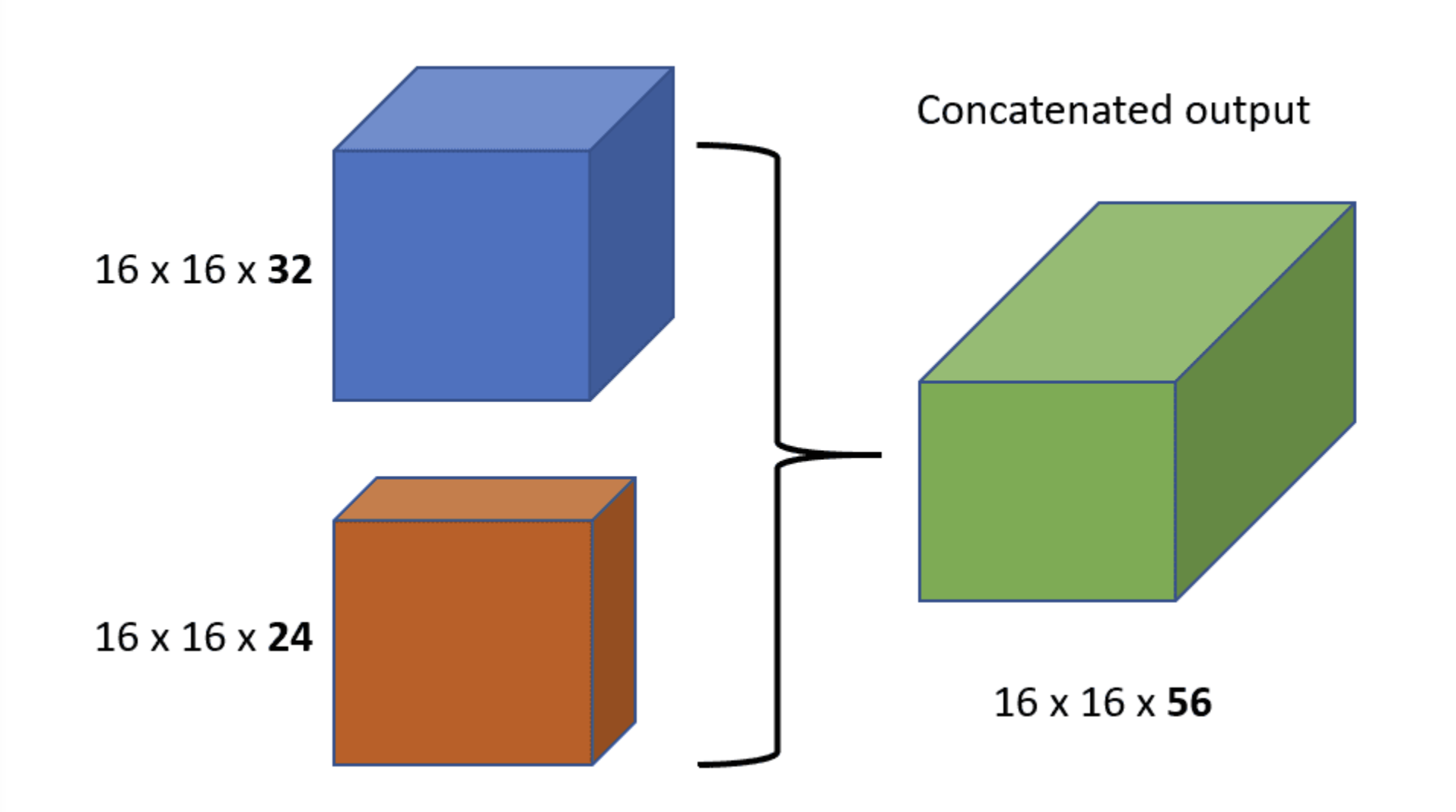
在一个 Dense Block 中,较浅层的输入会 concatenated 在一起输入下一次层网络。一层层递推,越往后的层,获得 concatenated 的信息就越多。
可以多很多条“捷径”,浅层的输入直接有通道通往 block 的输出层。这样做也可以很大程度上降低网络 vanishing gradient 的问题。
分类
short skip:用一个很短的路径,例如ResNet。
全局信息 (图像的形状和其他统计信息) 解析 what,而局部信息解析 where (图像块中的小细节)。
long skip:一般出现在 Encoder-Decoder 这种“对称的”网络框架中,例如 U-Net。
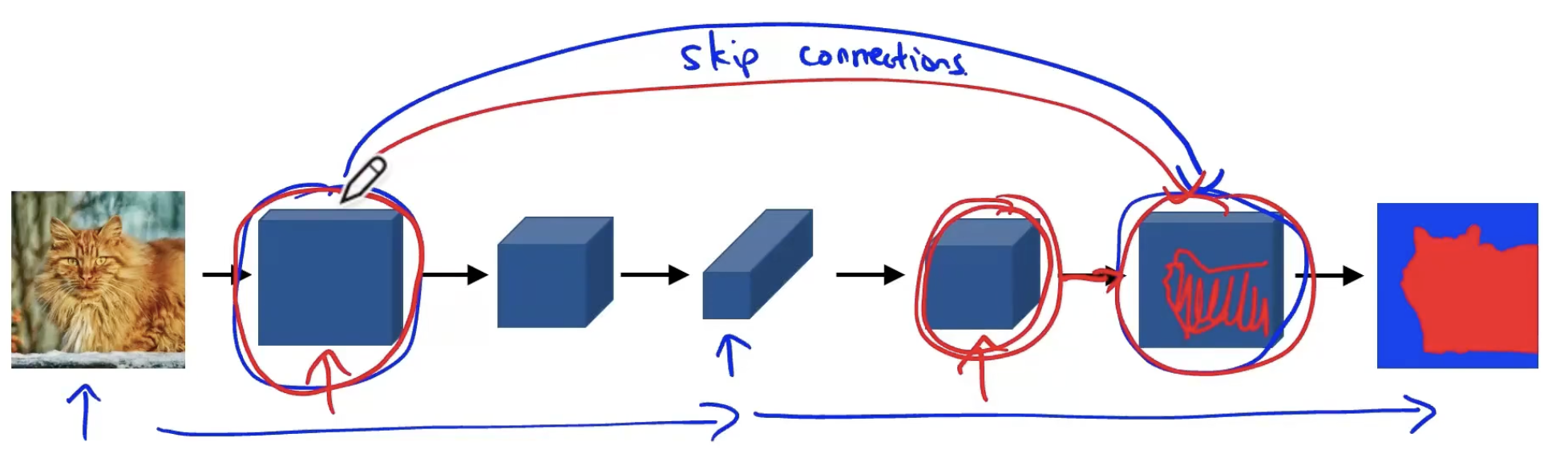
6. U-Net
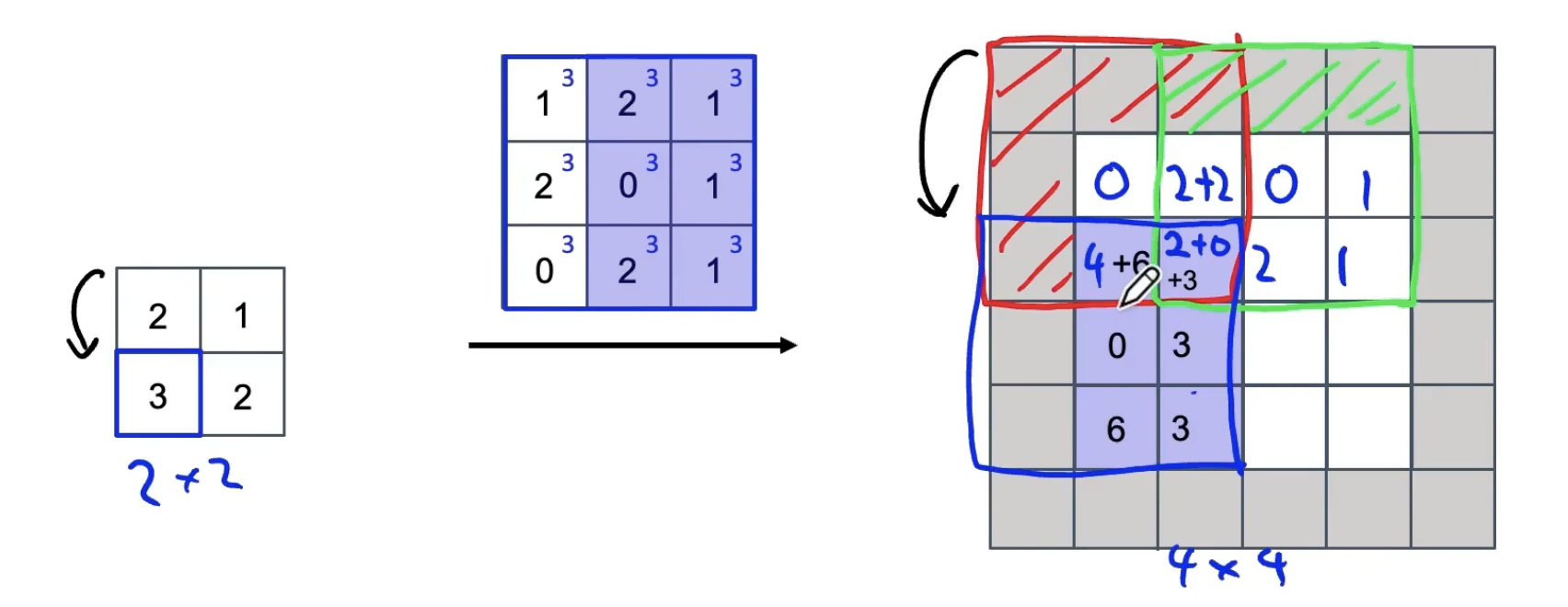
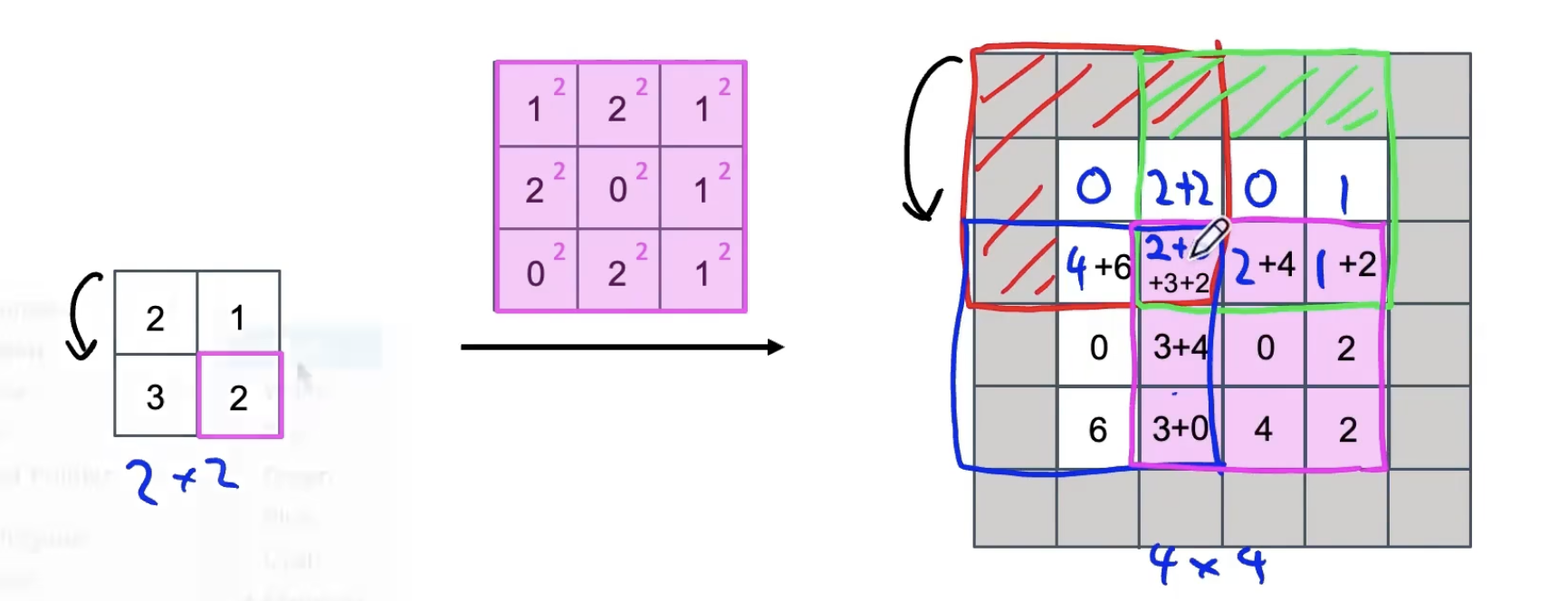
1. 关键部件:反卷积
卷积:将过滤器放在输入上,然后将其相乘再相加。
反卷积:将过滤器放在输出上,然后将其相乘再相加。
例如:
filter: 3*3;padding p = 1;stride s = 2
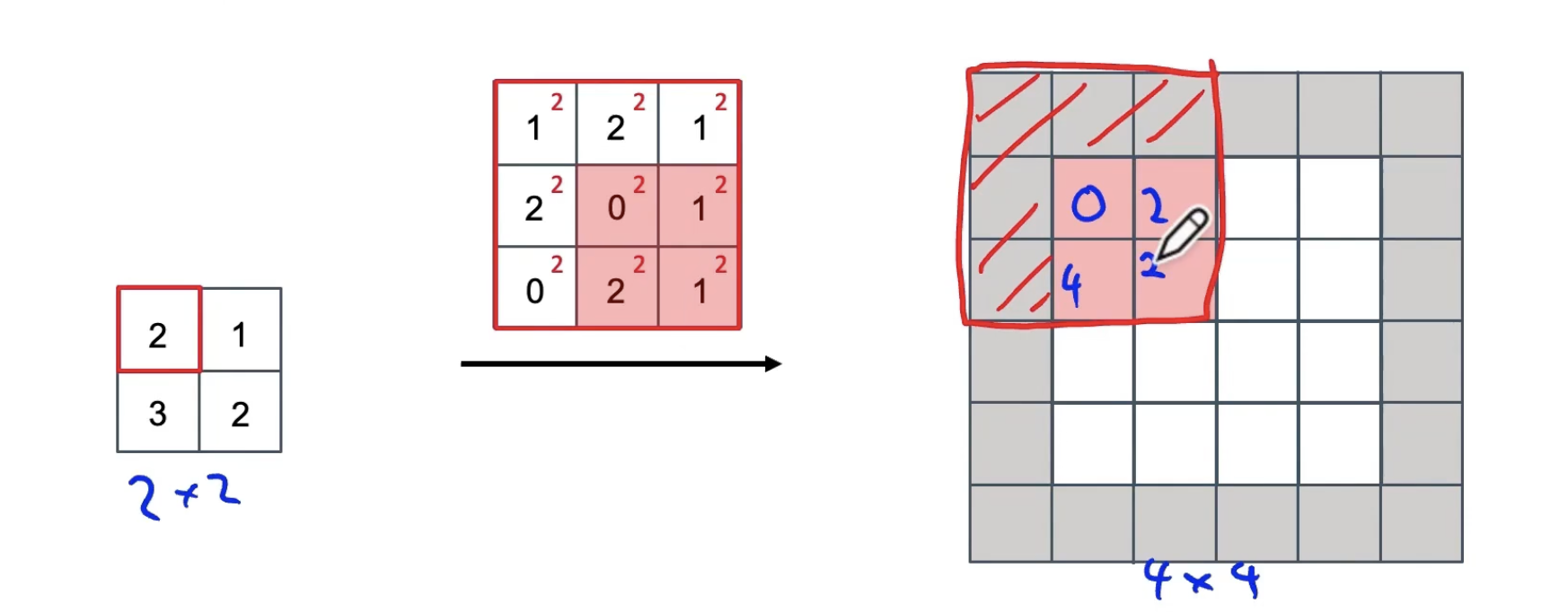
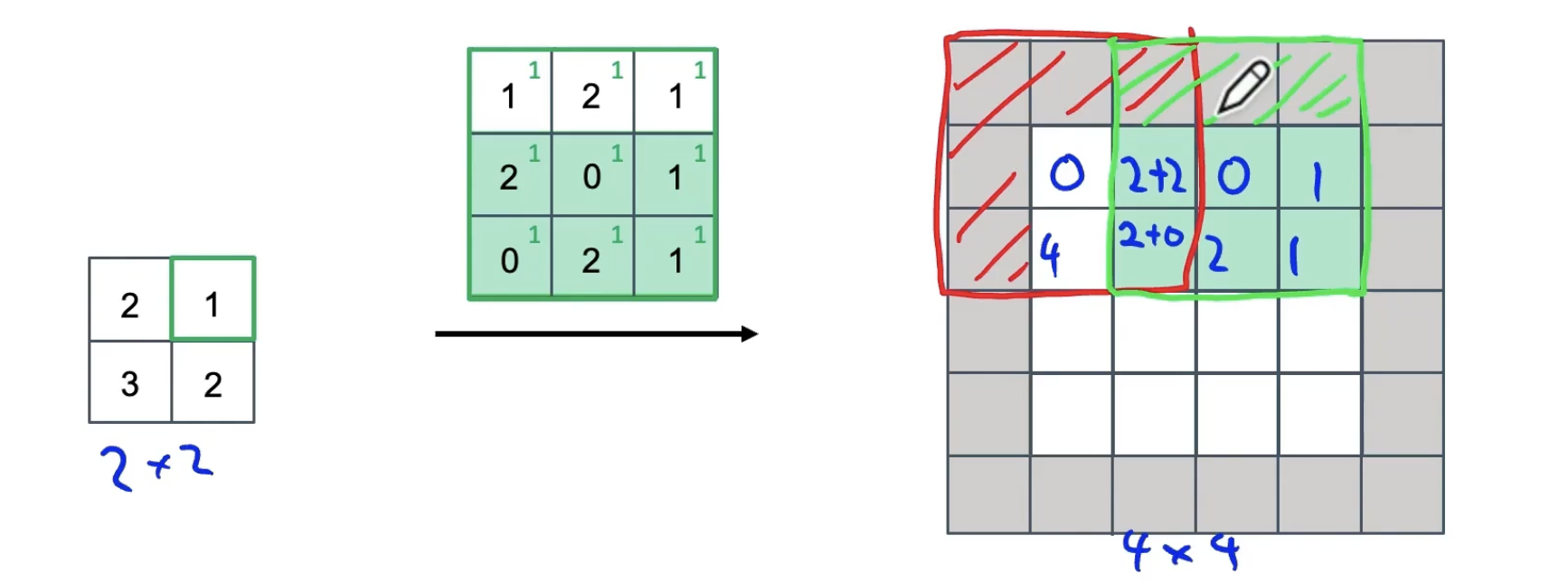
重叠处的值进行相加。
2. 网络架构
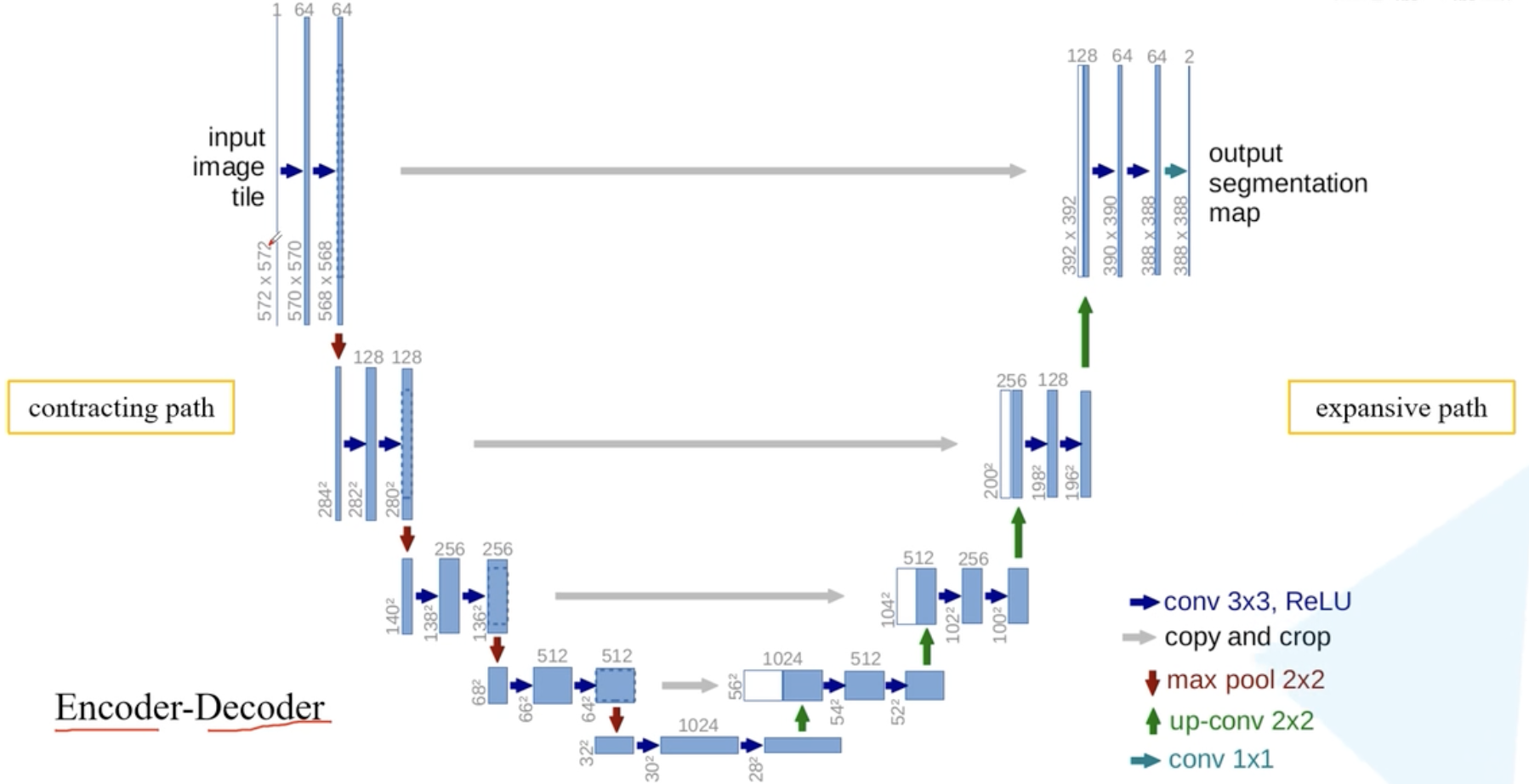
蓝/白色框表示 feature map;
蓝色箭头表示 3x3 卷积,用于特征提取;
灰色箭头表示 skip-connection,用于特征融合;
copy and crop中的copy指concatenate,而crop是为了让两者的长宽一致。在 skip-connection 时要注意 feature map 的维度。红色箭头表示池化 pooling,用于降低维度;
绿色箭头表示上采样 upsample,用于恢复维度;
青色箭头表示 1x1 卷积,用于输出结果。
skip-connection
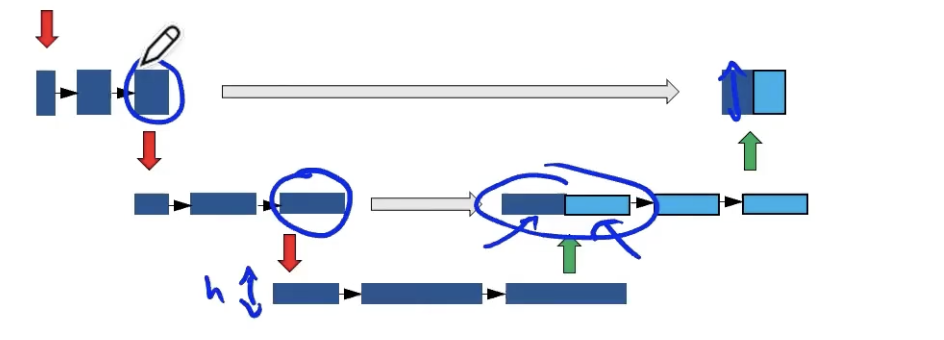
即将左边部分复制到右边。最终,输入与输出的维度一模一样。
Encoder
该过程由卷积操作和下采样操作组成。其中,在 skip-connection 时要注意 feature map 的维度。
Decoder
feature map 经过 Decoder 恢复原始分辨率,该过程由卷积、 upsampling 与 skip-connection 组成。
- Upsampling 上采样常用的方式有两种:
- 反卷积
- 插值
- Upsampling 上采样常用的方式有两种: