BERT
名字来源:美国的一个动画片芝麻街里的主人公
论文:https://arxiv.org/abs/1810.04805
NLP 里的迁移学习
在 bert 之前:使用预训练好的模型来抽取词、句子的特征
- 如用 word2vec 或 语言模型(当作embedding层)
- 不更新预训练好的模型
- 缺点
- 需要构建新的网络来抓取新任务需要的信息
- Word2vec 忽略了时序信息,语言模型只看了一个方向
bert 的动机
基于微调的 NLP 模型
前面的层不用动,改最后一层的 output layer 即可
预训练的模型抽取了足够多的信息,新的任务只需要增加一个简单的输出层
BERT 架构
本质:一个砍掉解码器、只有编码器的 transformer
bert 的工作:证明了效果非常好
两个版本:
Base: #blocks=12, hidden size=768, #heads=12, #parameters=110M
Large: #blocks=24, hidden size=1024, #heads=1, #parameter=340M
在大规模数据上训练>3B词
创新
1. 对输入的修改
v.s Transformer:
- 原句子进 encoder,目标进 decoder;
bert
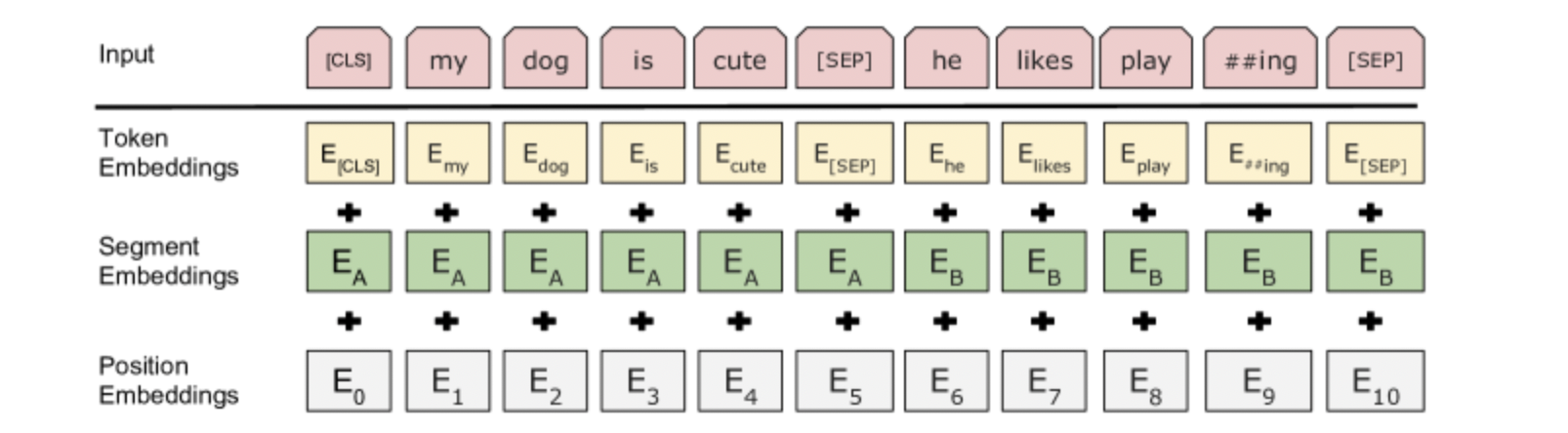
- 每个样本是一个句子对
- 加入额外的片段嵌入,区分句子不同的部分
- 位置编码可学习(transformer是手动设计)
2. 预训练任务1:带掩码的语言模型
- Transfomer 的编码器是双向,但标准语言模型要求单向
- BERT:
- 带掩码的语言模型:每次随机(15%概率)将一些词元换成 ,去预测这些词
- 因为微调任务中不出现
- 80% 概率下,将选中的词元变成
- 10% 概率下换成一个随机词元
- 10% 概率下保持原有的词元
3. 预训练任务2:下一个句子预测
预测一个句子中的两个句子是不是相邻的
- 训练样本中:
- 50% 概率选择相邻句子对: this movie is great i like it
- 50% 概率选择随机句子对: this movie is great hello world
- 将 对应的输出放到一个全连接层来预测,预测两个句子是否相邻
总结
- BERT 针对微调设计,使用时改输出/输入层即可
- 基于 Transformer 的编码器做了如下修改:
- 模型更大,训练数据更多
- 输入句子对,片段嵌入,可学习的位置编码
- 训练时使用两个任务:
- 带掩码的语言模型
- 下一个句子预测