Diffusion Model
概述
影像生成模型本质上的共同目标
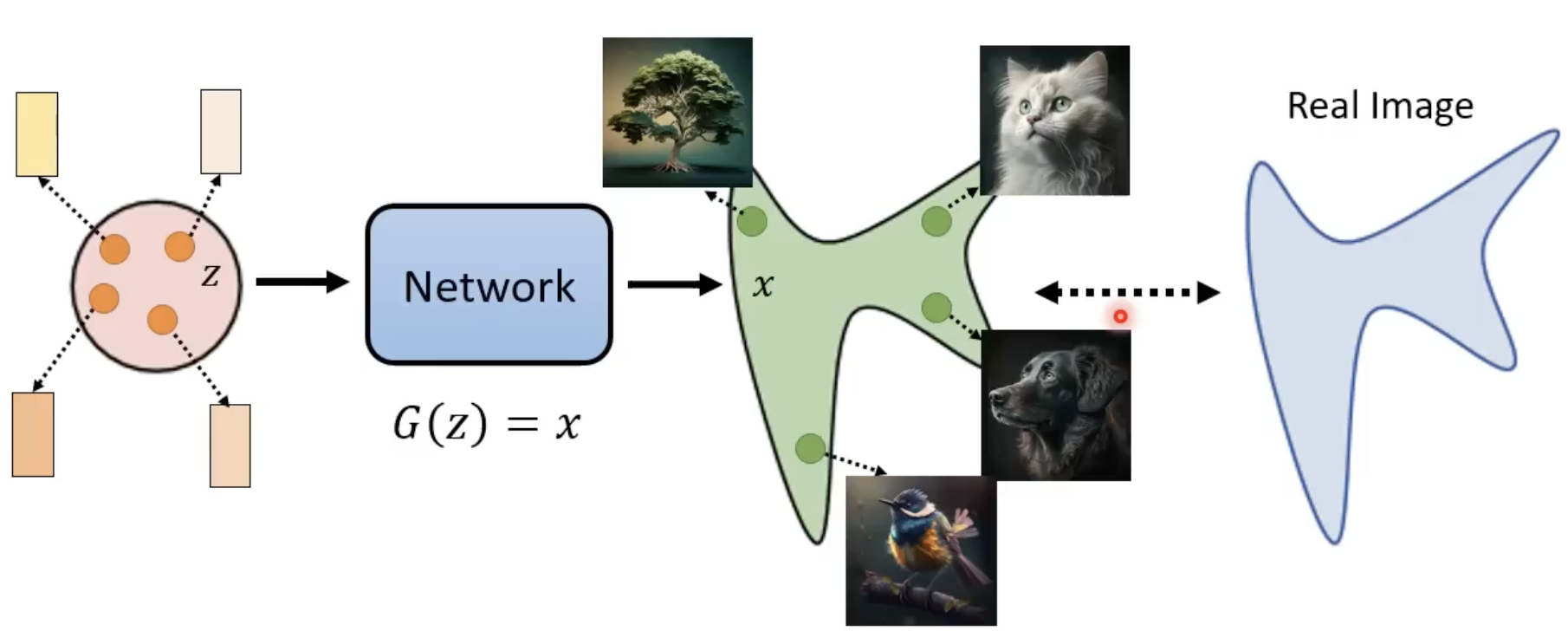
进一步:输入加入了文字表述
目标:产生的图片与真实图片越接近越好
原理
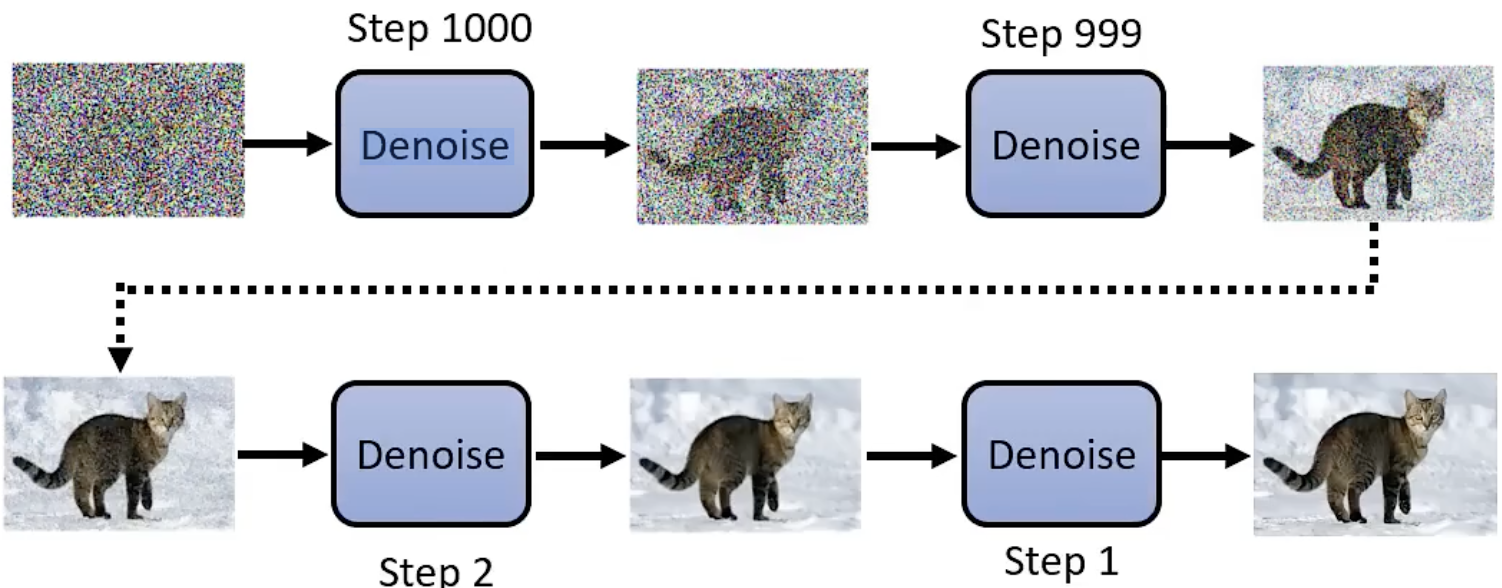
Reverse Process(多次Denoise)
reconstructing meaningful data from noise by iteratively removing noise that was added during the forward process.
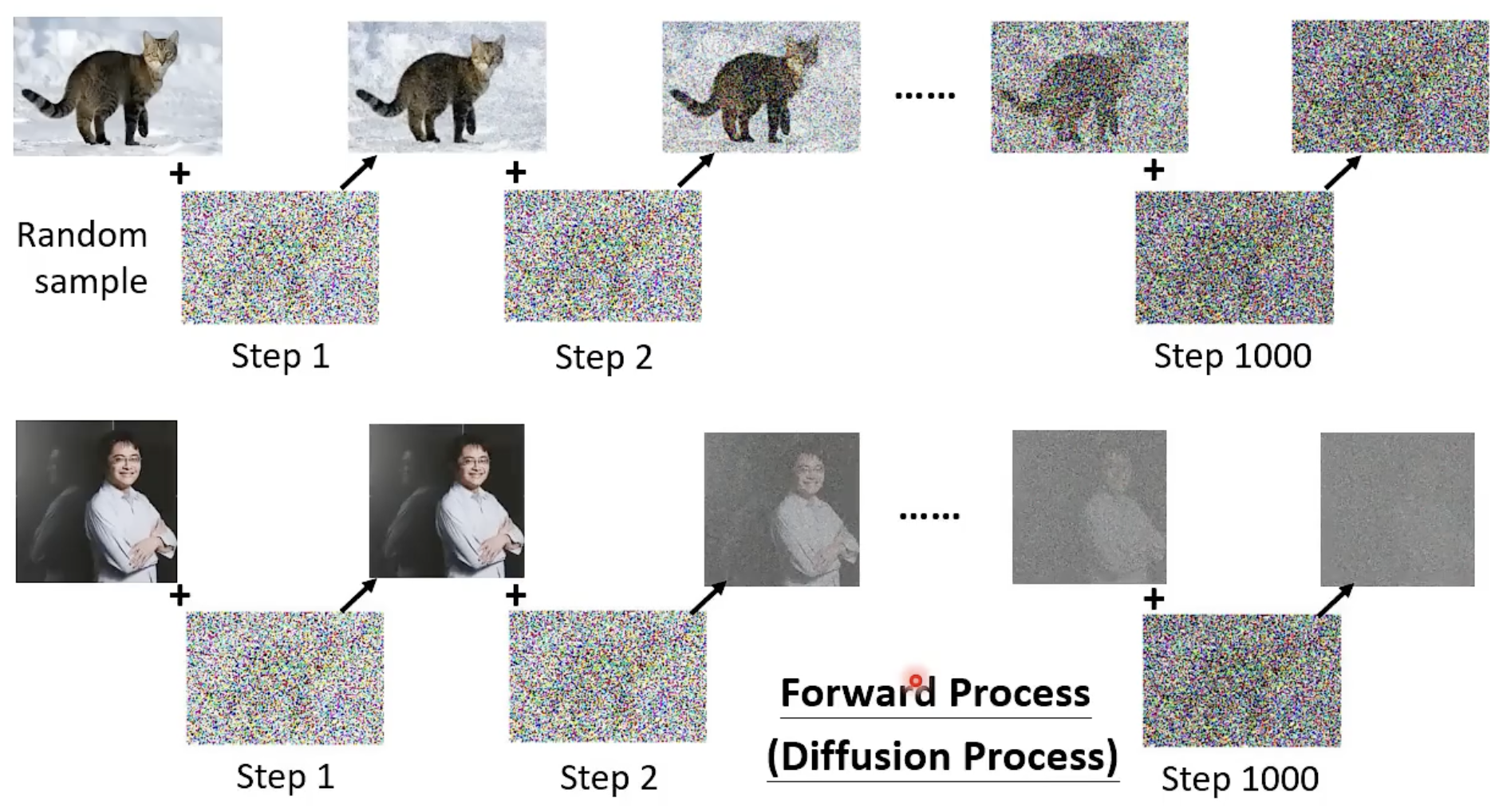
Forward Process:
Gradually adds noise to data over multiple steps until the data becomes pure noise.
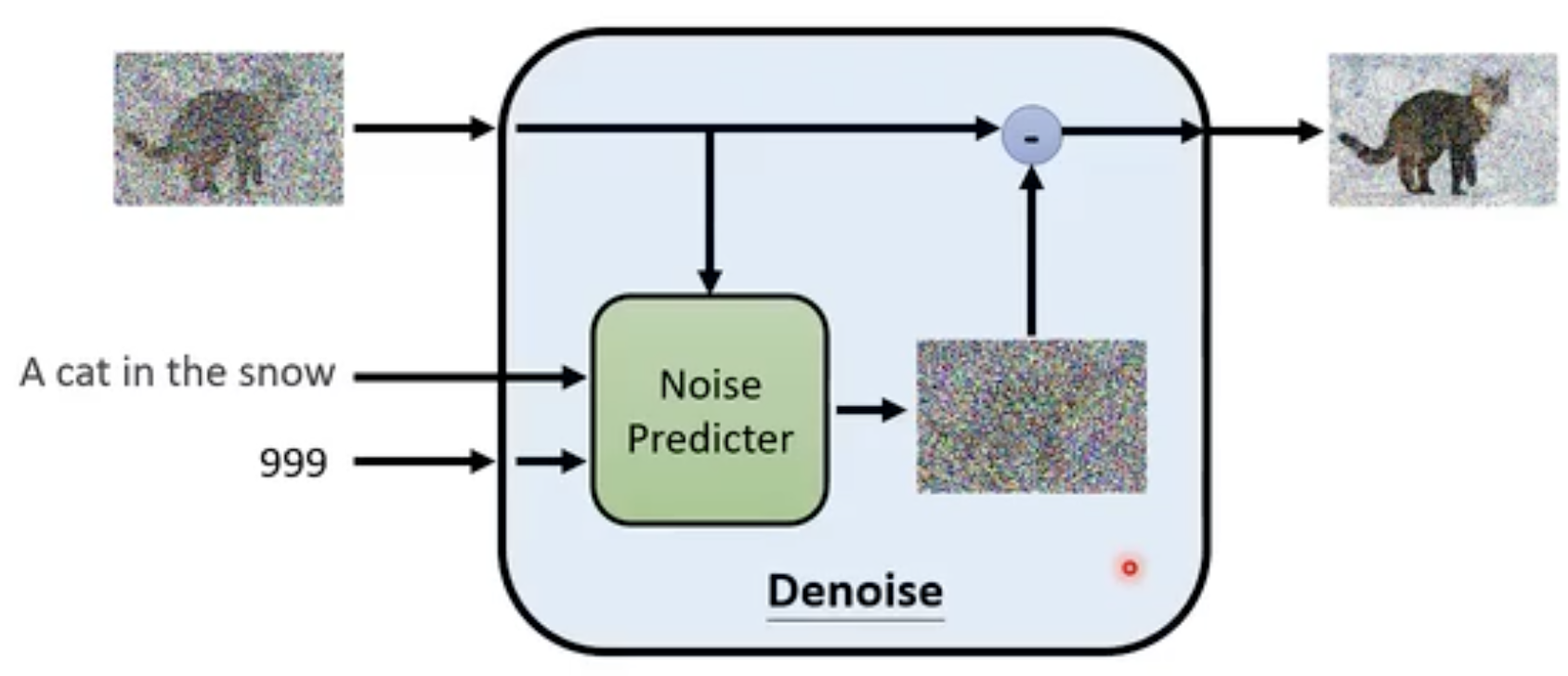
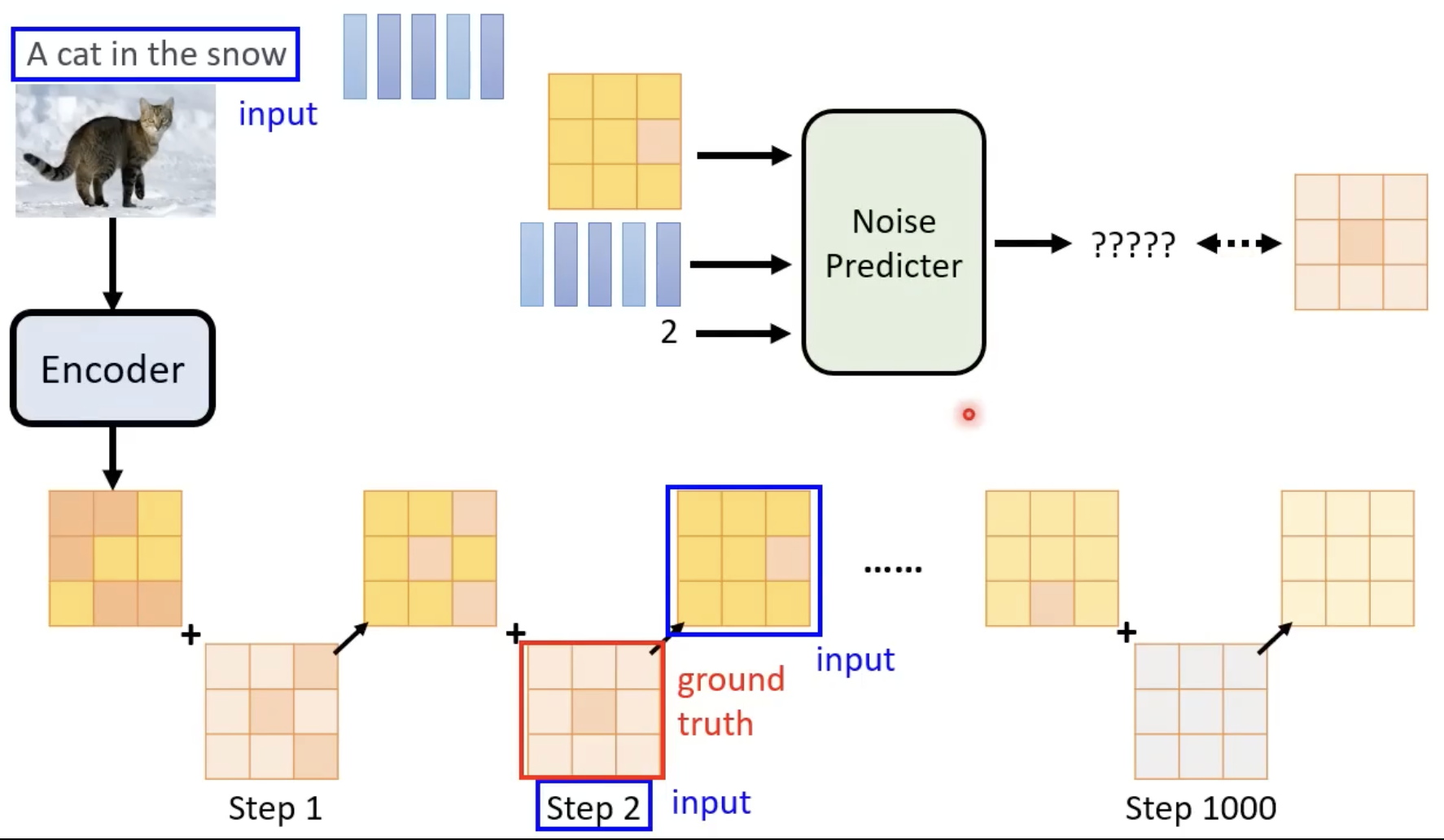
Denoise输入:图片 + 噪音程度

Denoise Model内部
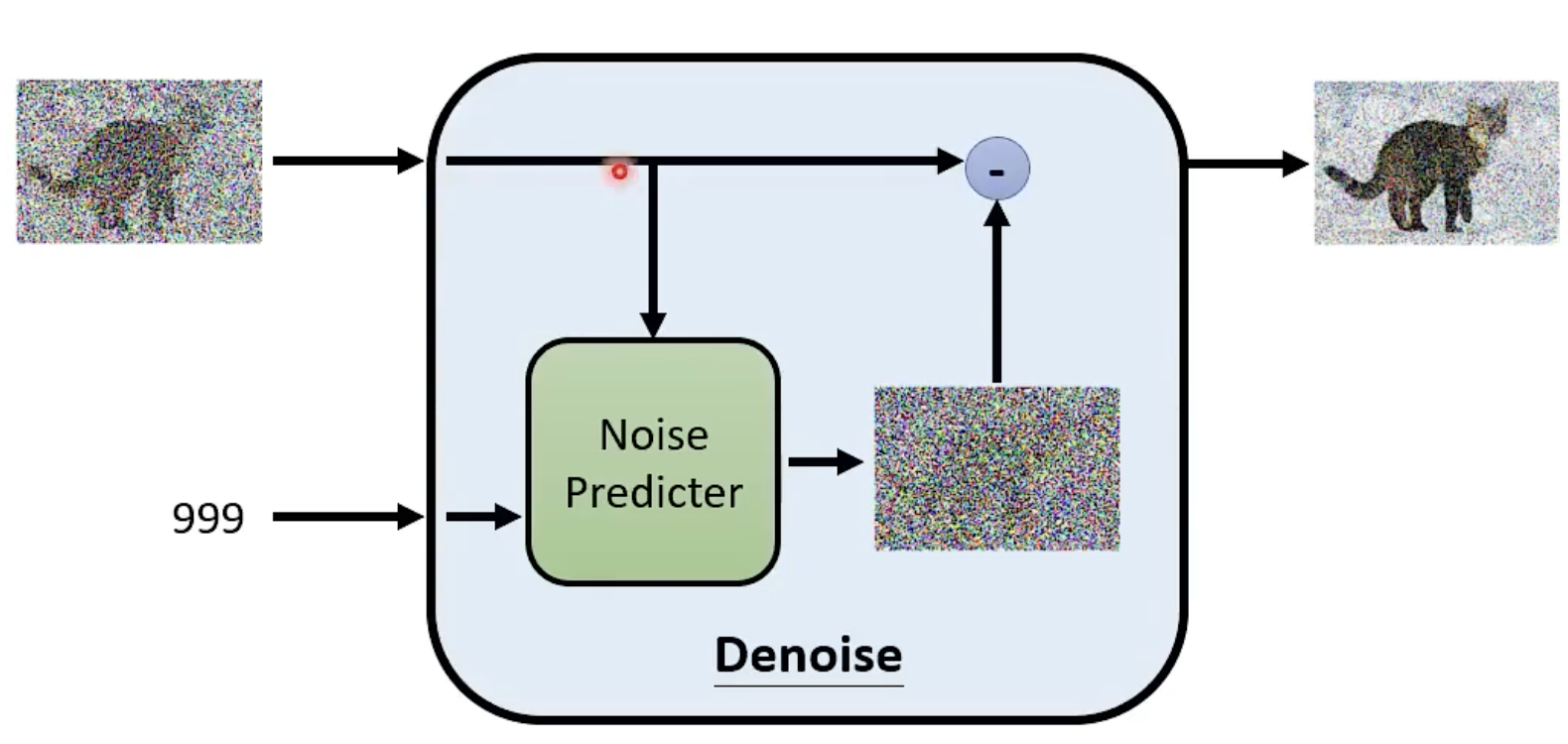
Noise Predicter: 预测noise长什么样
如何训练Noise Predicter?
人为创造(加杂讯/Forward Process)
Text-to-Image
Laion拥有5.85B图片,可进行搜索
输入:图片+噪声程度+文字叙述
算法

训练:

- sample一张clean image
- sample出一个数字
- sample出一个noise
- clean image 和 noise 做加权和得到一个有杂讯的图,然后训练noise predictor(输入有杂讯的图 和 数字;输出目标noise)
产生图:
sample一个全是noise图
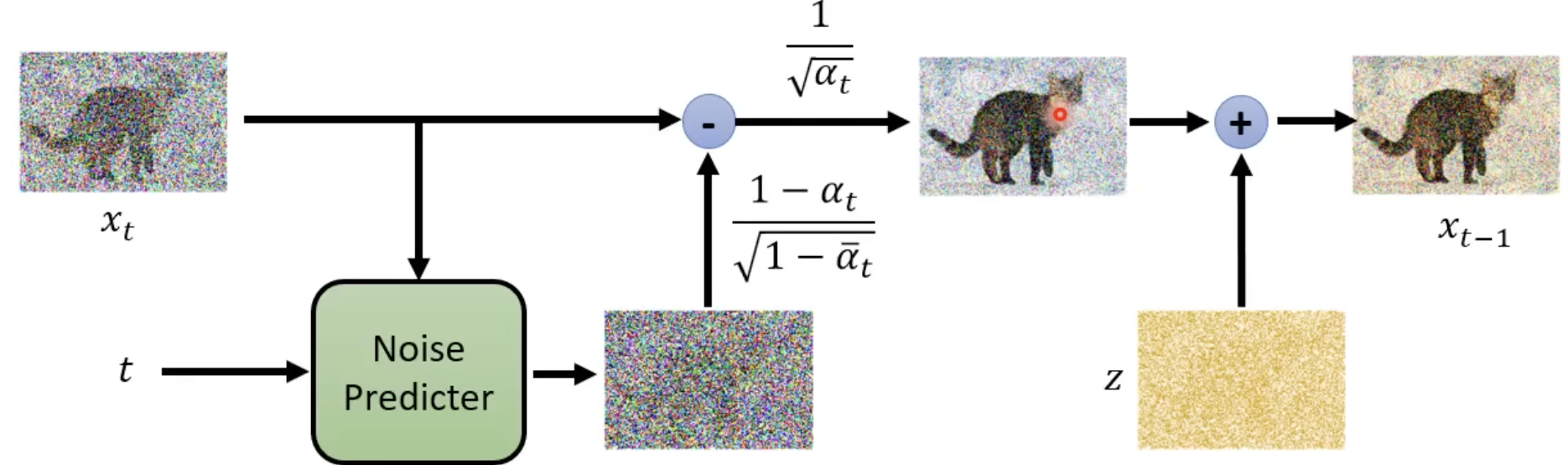
跑T次:
sample另一个noise图
生成x_t(见公式)
Stable Diffusion
框架组成:
- Text Encoder:输入为文字,输出为向量
text encoder对结果的影响很大
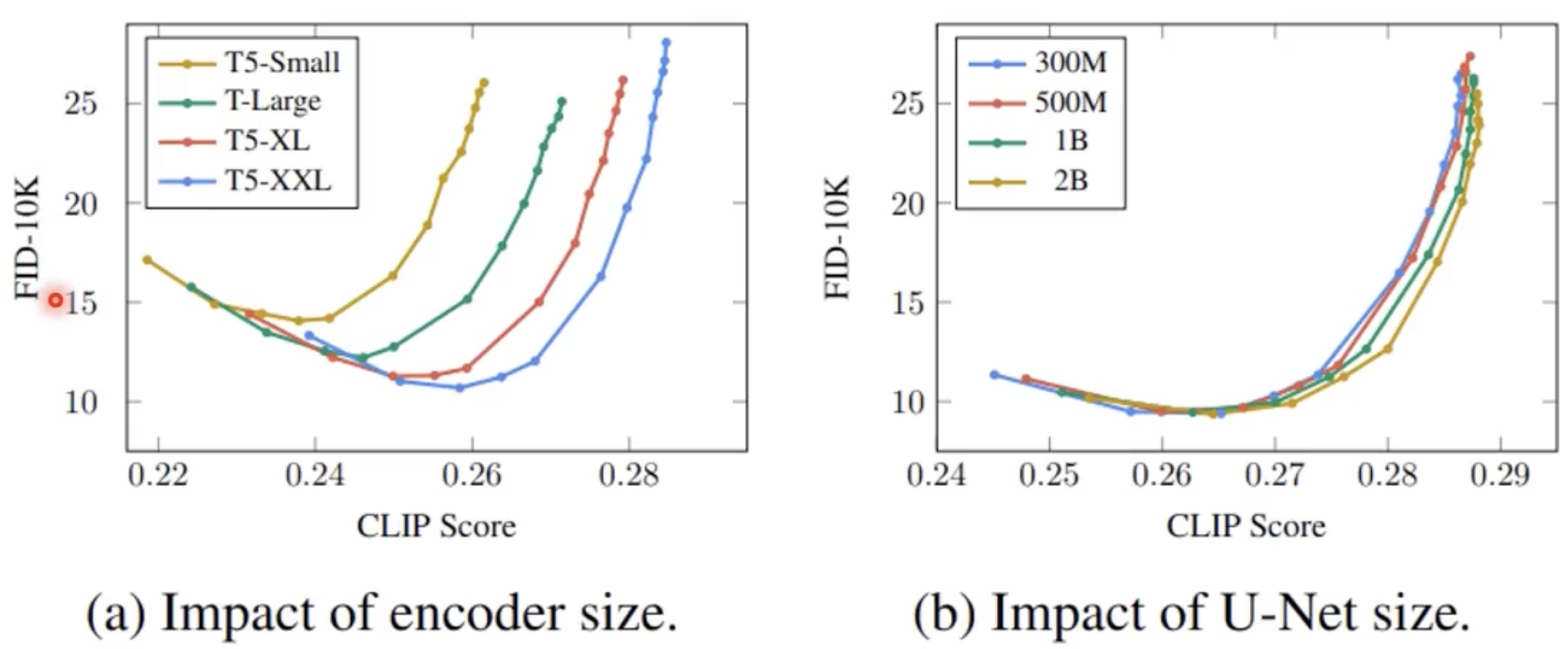
读的越多效果越好,不同大小的diffusion model影响不大。
Deneration Model:输入杂讯和向量,输出中间产物(图片压缩结果)
sample出noise,加在中间产物上:
得到中间产物后,再次Denoise:
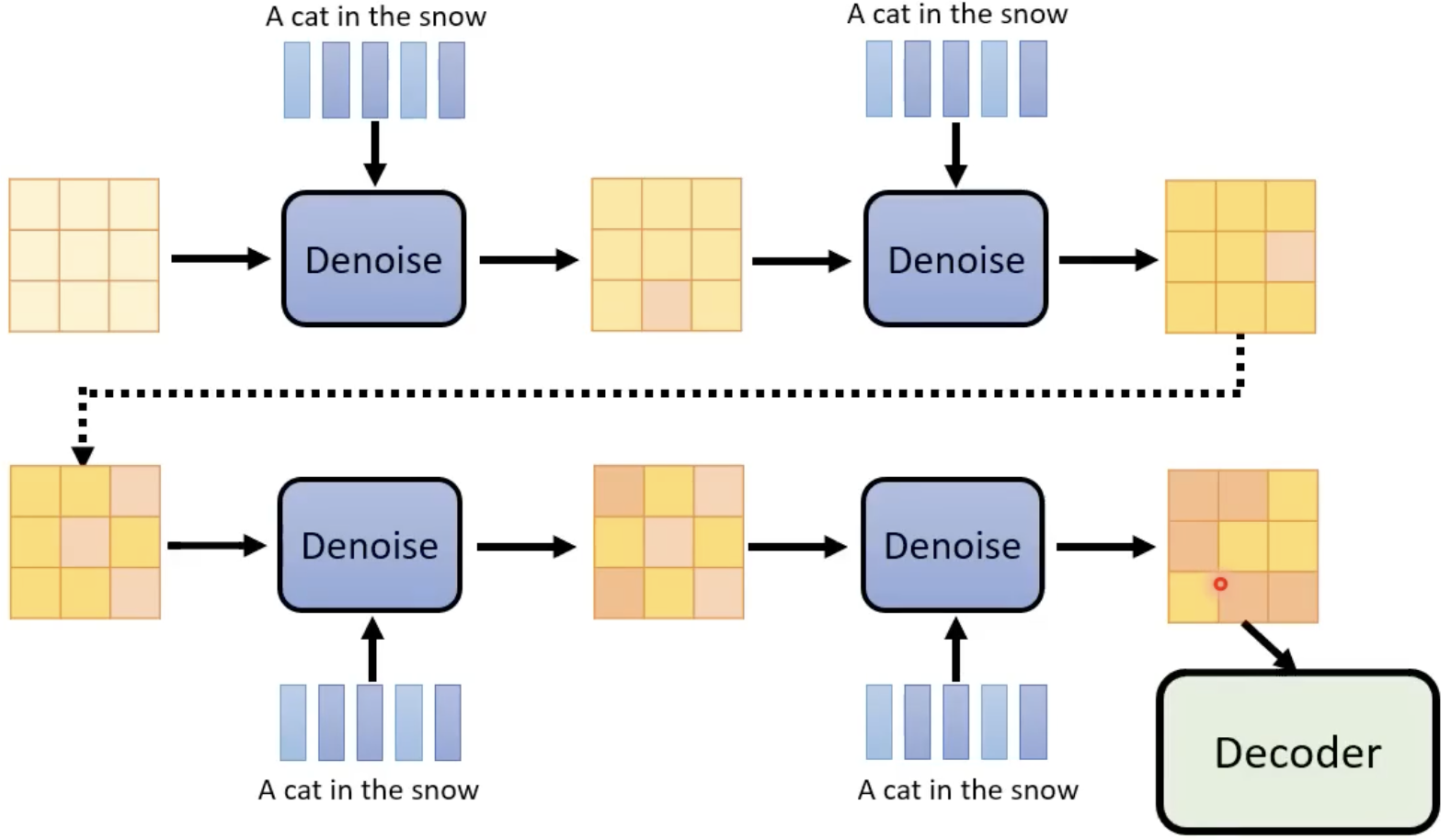
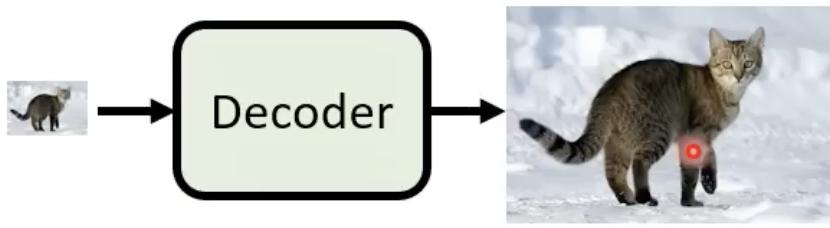
Decoder:将中间产物还原回原来的图片
Decoder的训练可以不需要labelled data
训练过程:
若中间产物是小图
把收集到的所有的图片缩小,小图变大图
若中间产物是Latent Representation
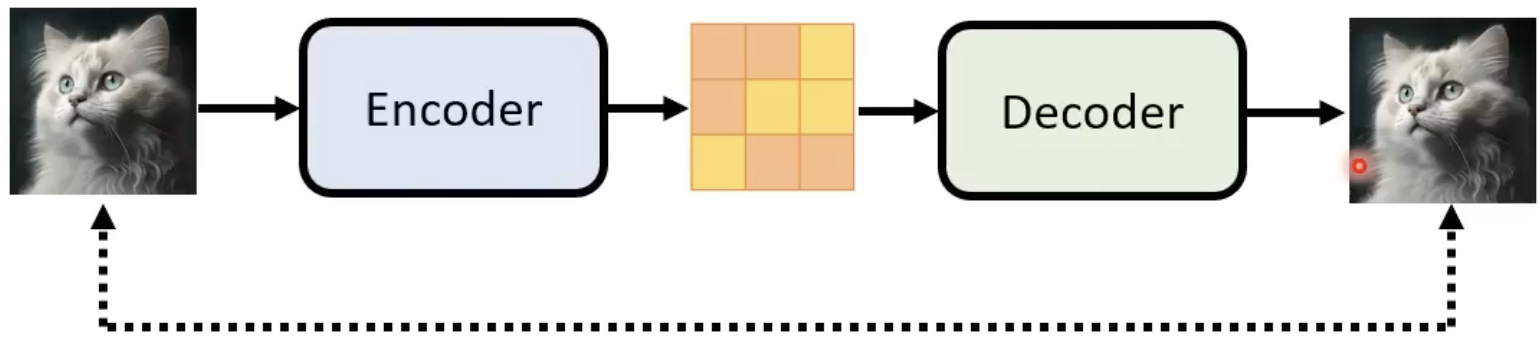
训练一个Auto-encoder,使输入与输出越接近越好。最后,再将Decoder拿出来用即可。
通常,3个Model分开训练,最后组合在一起
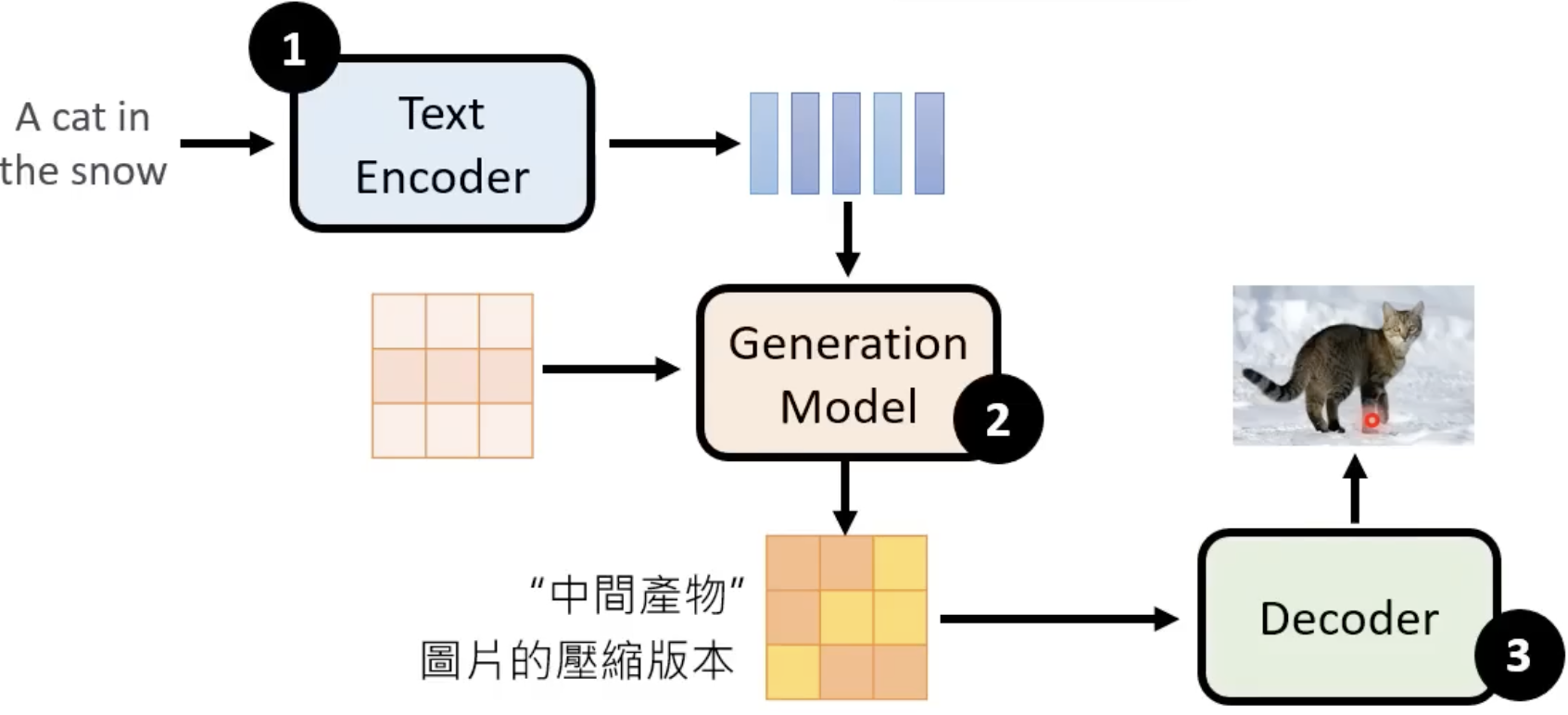
经典结构:
Stable Diffusion
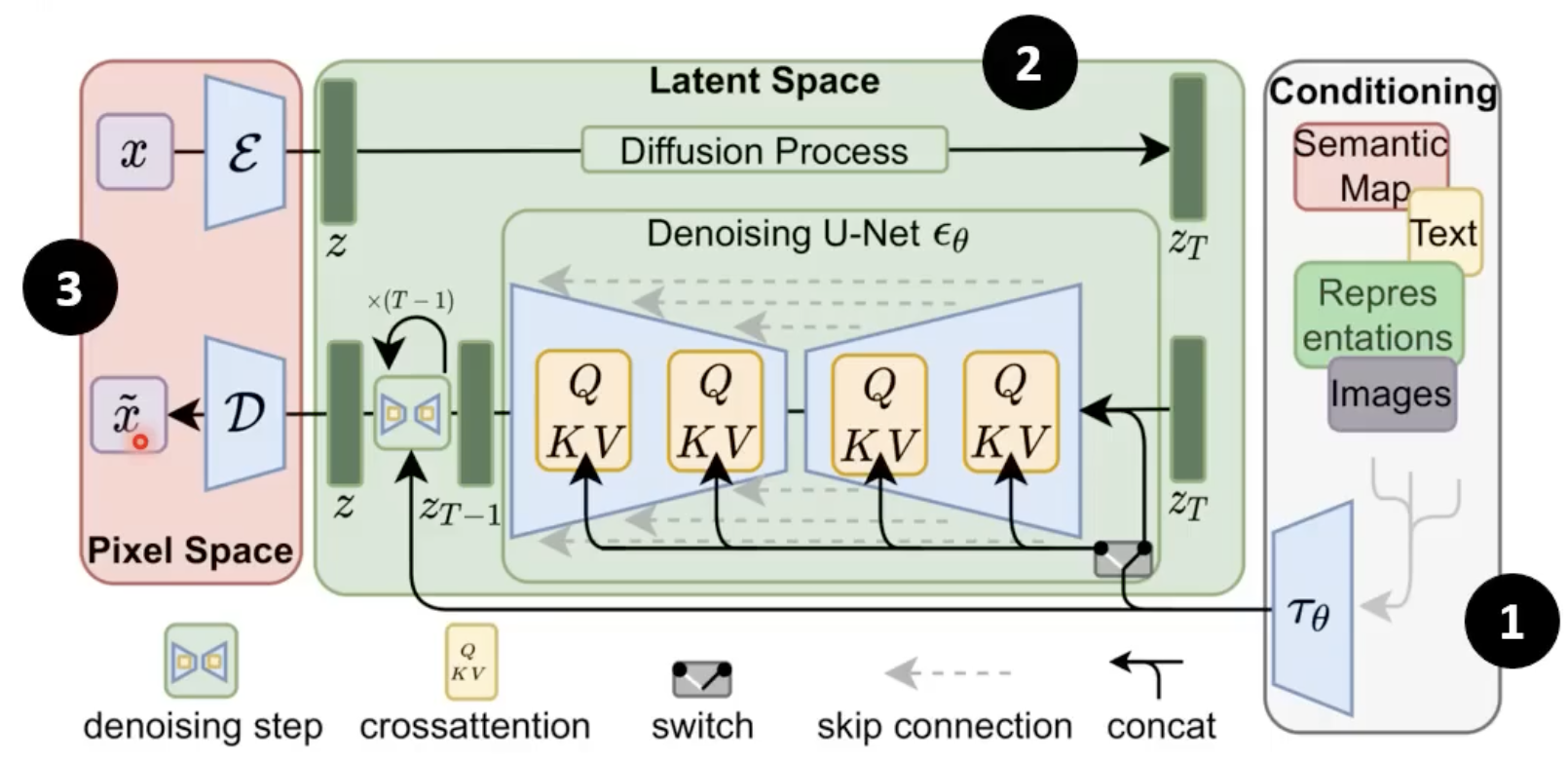
- encoder:处理输入文字等
- diffusion model
- decoder:还原
DALL-E系列:
- encoder
- autogressive model 和 diffusion model
- decoder
Imagen:
- encoder
- diffudion model:生成人类可看懂的中间结果
- decoder
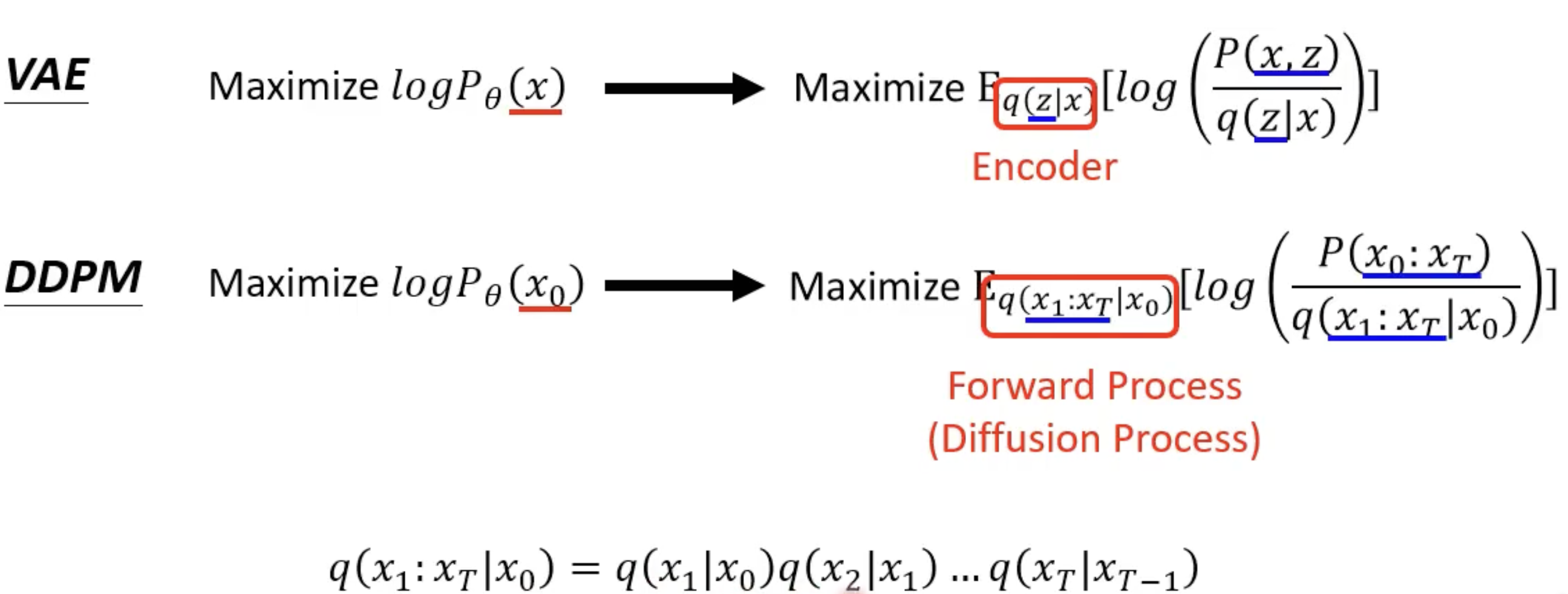
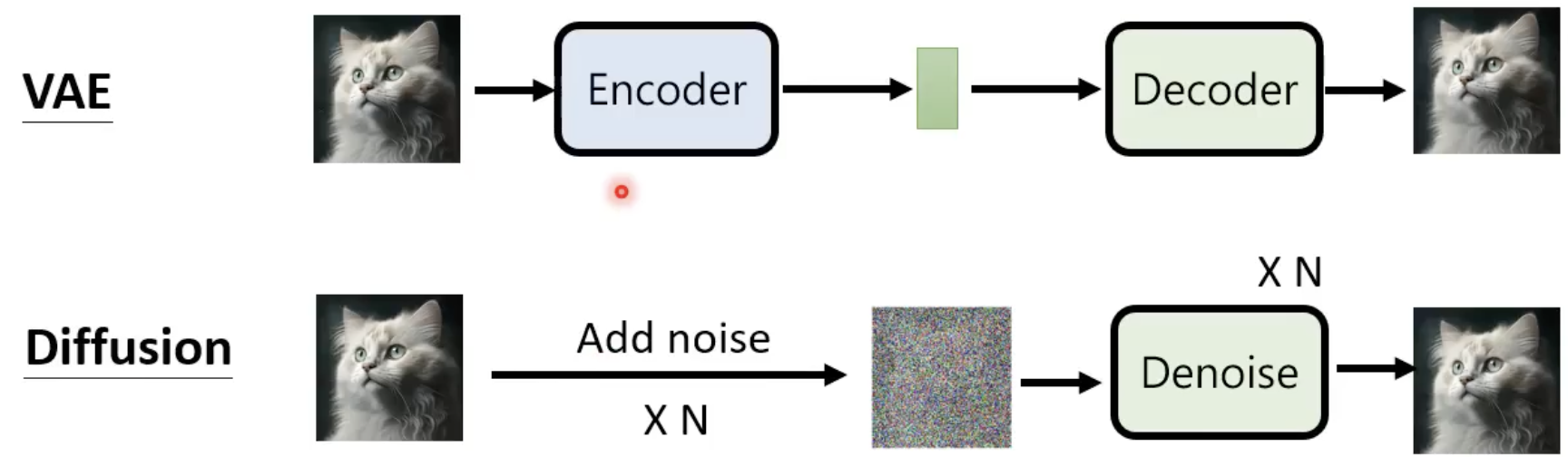
v.s VAE
评估指标
KL 散度
度量两个概率分布之间的差异程度
Fréchet Inception Distance(FID)
评估影响生成模型的好坏。
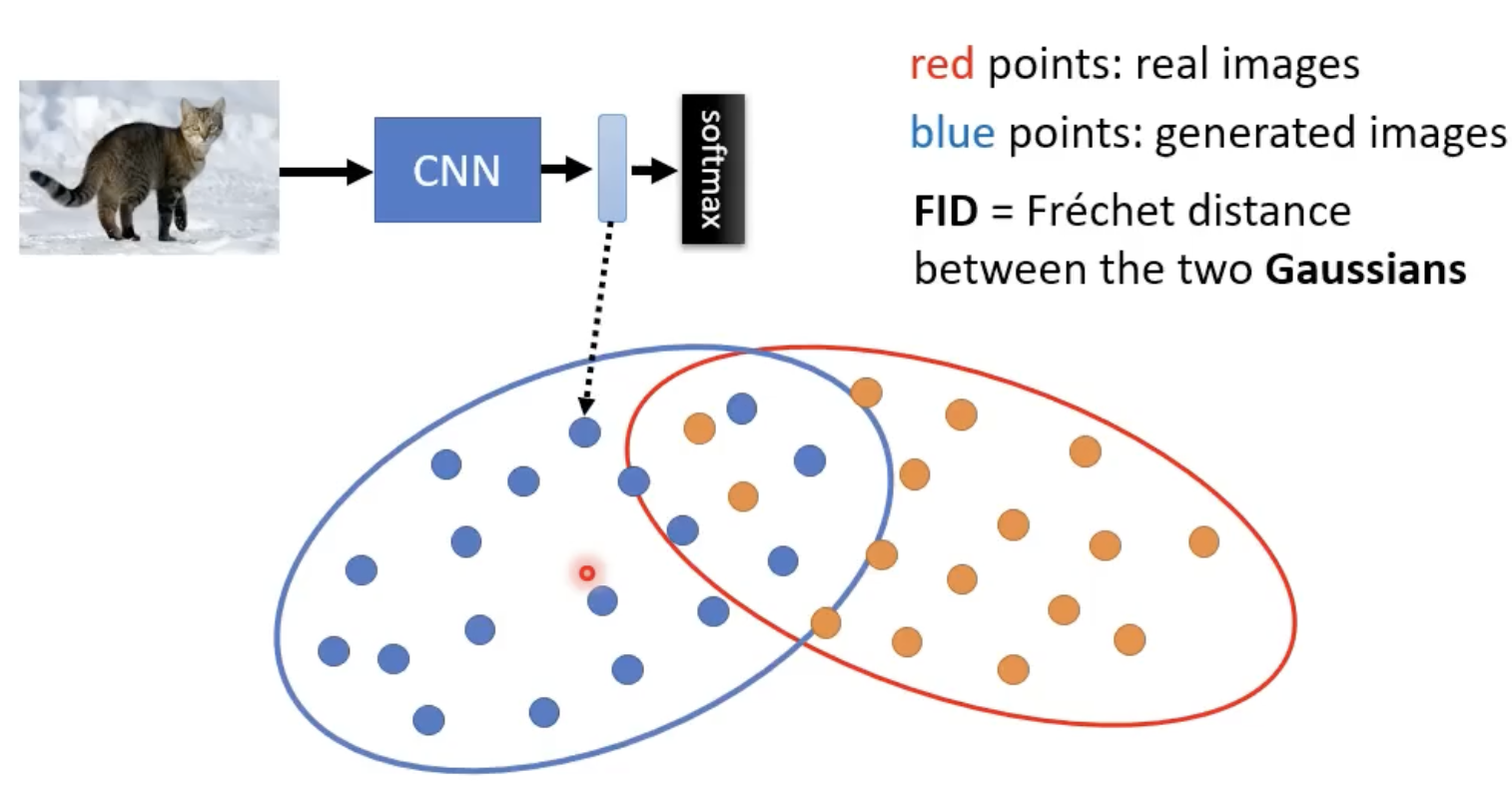
现有一个pre-train好的分类CNN Model,然后将图片扔入网络,得到生成图片。计算两组生成和真实图片之间的Fréchet distance。距离越小越好。
缺点:想要生成大量images。
Contrastive Language-Image Pre-Training
(CLIP)
是用400 million image-text pairs训练出来的模型。
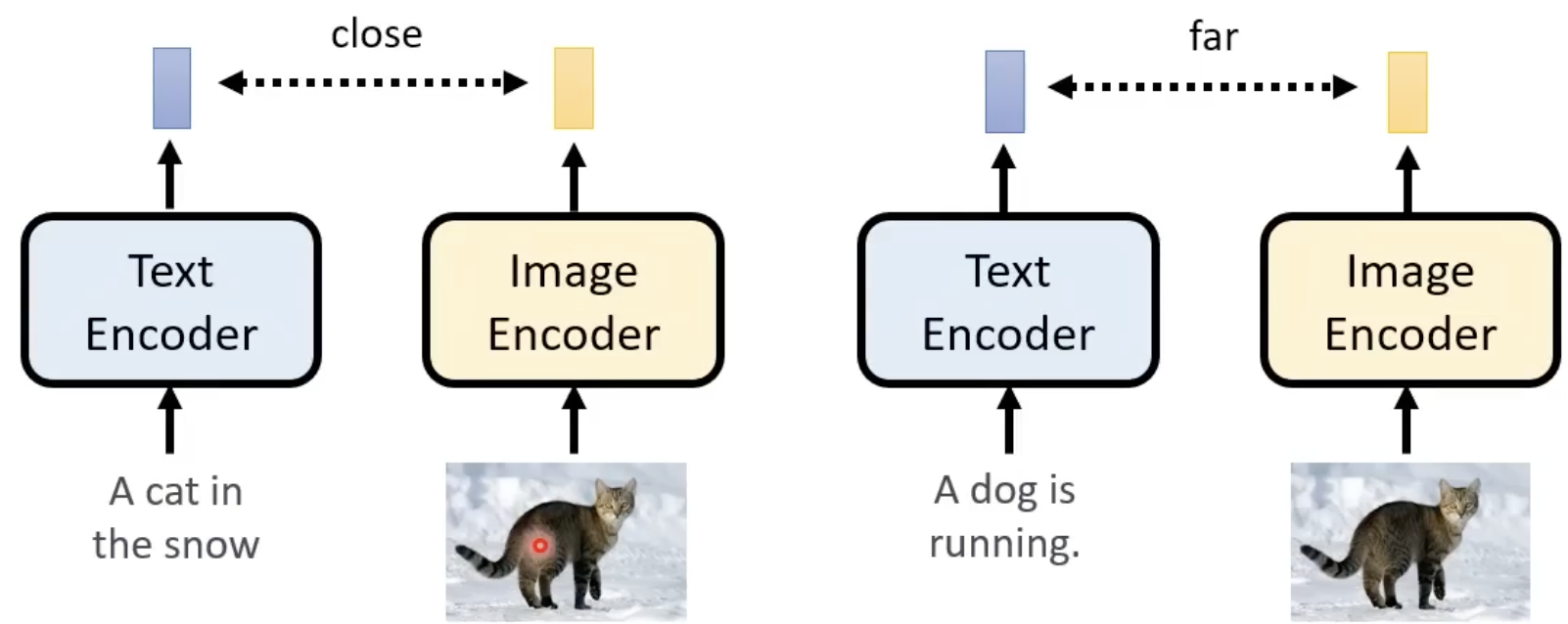
- 计算产生的图片、输入的文字丢进CLIP,计算CLIP输出向量之间的距离。