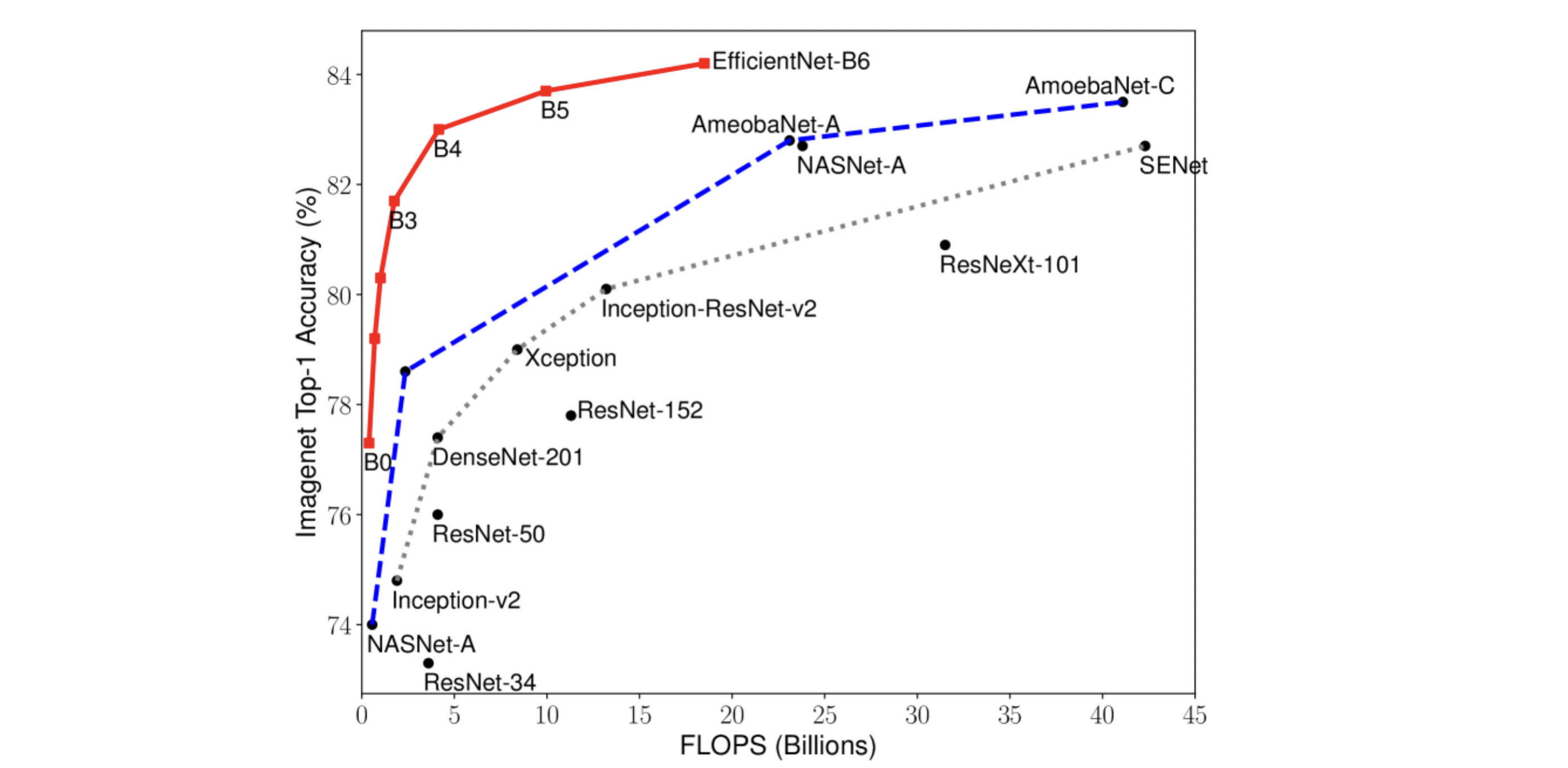
EfficientNet
传统的模型缩放:
任意增加 CNN 的深度或宽度,或使用更大的输入图像分辨率进行训练和评估。
缺点:通常需要长时间的手动调优,并且仍然会经常产生次优的性能。
- 提出了一种新的模型缩放方法和 AutoML 技术,使用使用简单但高效的复合系数,均匀缩放深度/宽度/分辨率的所有维度。
- 使用神经架构搜索来设计一个新的基线网络,并将其扩展以获得一系列模型,称为 EfficientNets。
优点:更小、更快。
复合模型放缩
1. 概述
目的:找到在固定资源约束下,基线网络的不同缩放维度之间的关系。
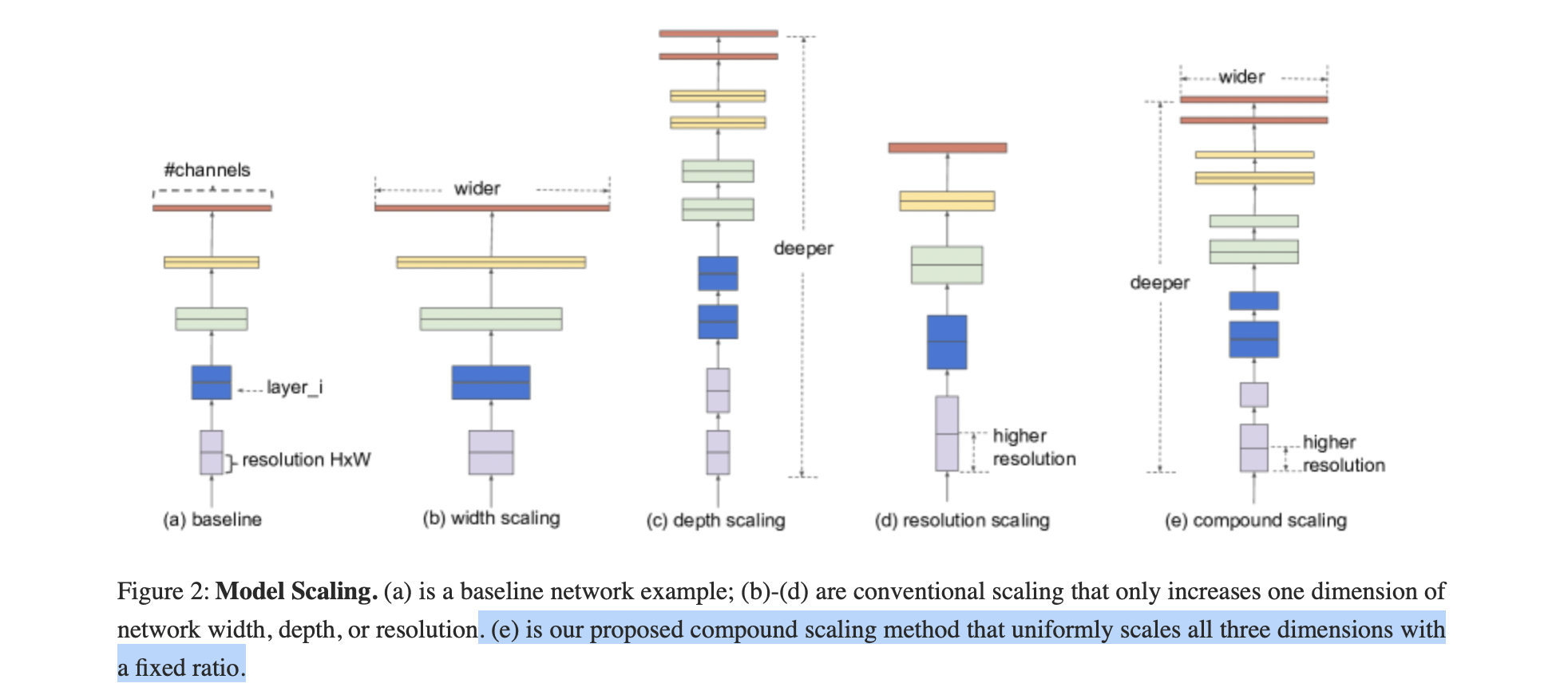
应用这些系数扩大基线网络,达到期望的模型大小或资源要求。
2. 复合模型扩张方法
更大的网络具有更大的宽度、深度或分辨率,往往可以获得更高的精度,但精度增益会迅速饱和,这表明了只对单一维度进行扩张的局限性。
为了追求更好的精度和效率,在ConvNet缩放过程中平衡网络宽度、深度和分辨率的所有维度是至关重要的。
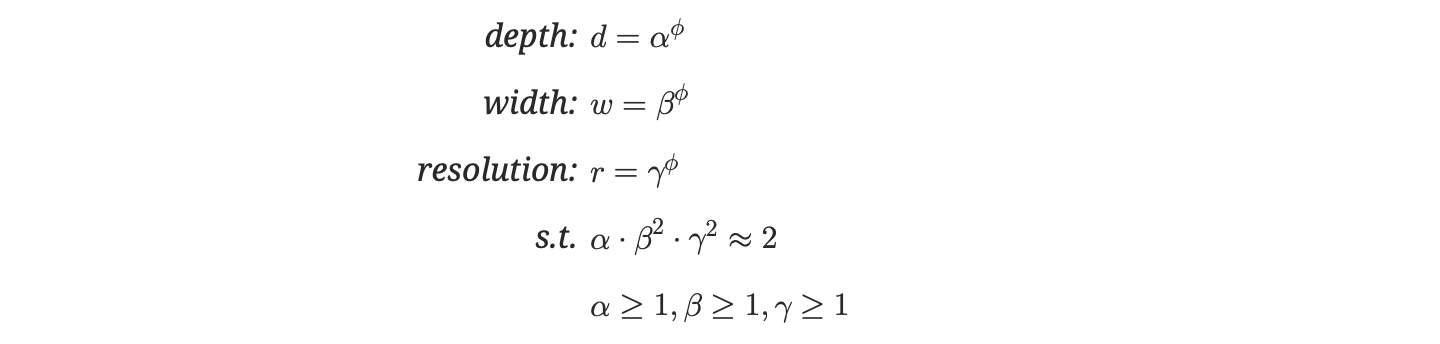
( α,β,γ)是需要求解的一组参数 —— 带约束的最优参数求解。
( α,β,γ) 分别衡量着 depth, width 和 resolution的比重,其中 β,γ在约束上有平方,是因为如果增加宽度或分辨率两倍,其计算量是增加四倍;但是增加深度两倍,其计算量只会增加两倍。
求解方式:
- 固定公式中的φ=1,然后通过网格搜索(grid search)得出最优的α、β、γ,得出最基本的模型EfficientNet-B0.
- 固定α、β、γ的值,使用不同的φ,得到EfficientNet-B1, …, EfficientNet-B7
φ 的大小对应着消耗资源的大小:
- 当φ=1时,得出了一个最小的最优基础模型;
- 增大φ时,相当于对基模型三个维度同时扩展,模型变大,性能也会提升,资源消耗也变大。
3. EfficientNet Architecture
模型扩展的有效性在很大程度上依赖于baseline网络。为了进一步提高性能,作者开发了一个新的基线网络,称为 EfficientNet。
EfficientNet-B0 的网络结构如下:
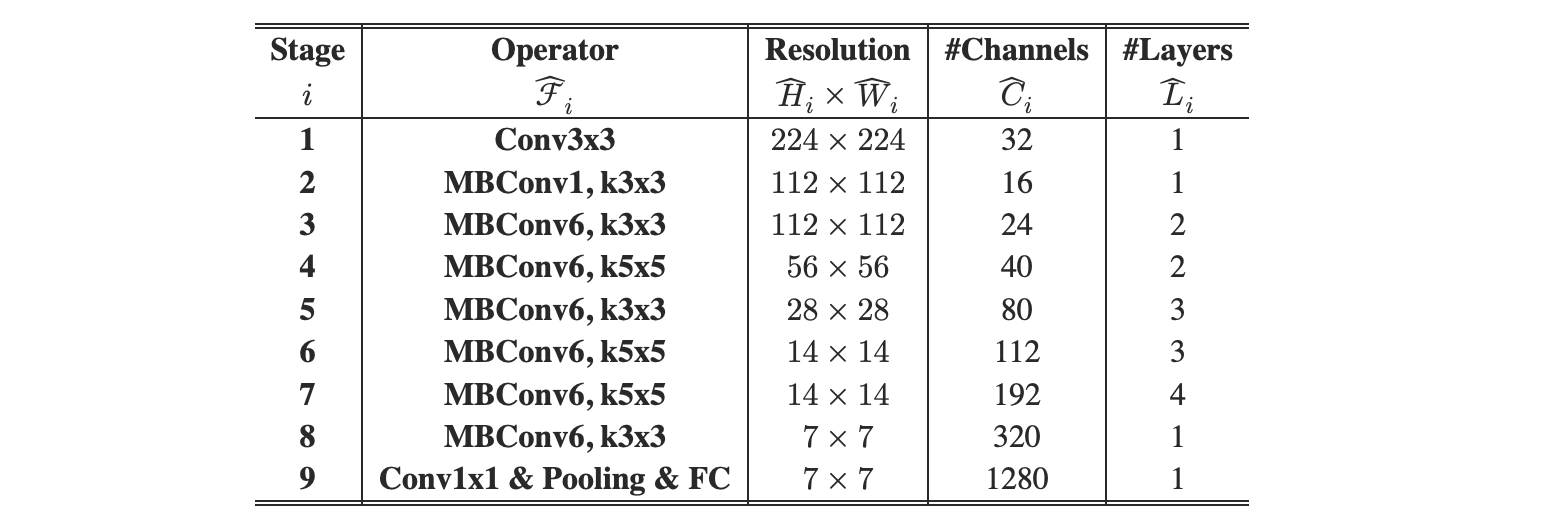
主要组件
组件 作用 Stem 初始卷积( _conv_stem)+BN+Swish激活,快速下采样MBConv Blocks 核心模块(含深度可分离卷积+SE注意力),共7个阶段( _blocks列表)Head 最后的1x1卷积+池化(分类头) MBConv 块结构
输入 → 1x1扩展卷积 → 深度卷积 → SE模块 → 1x1压缩卷积 → 残差连接- 深度可分离卷积:大幅减少计算量
- SE(Squeeze-Excitation):通道注意力机制,增强重要特征
实验结果