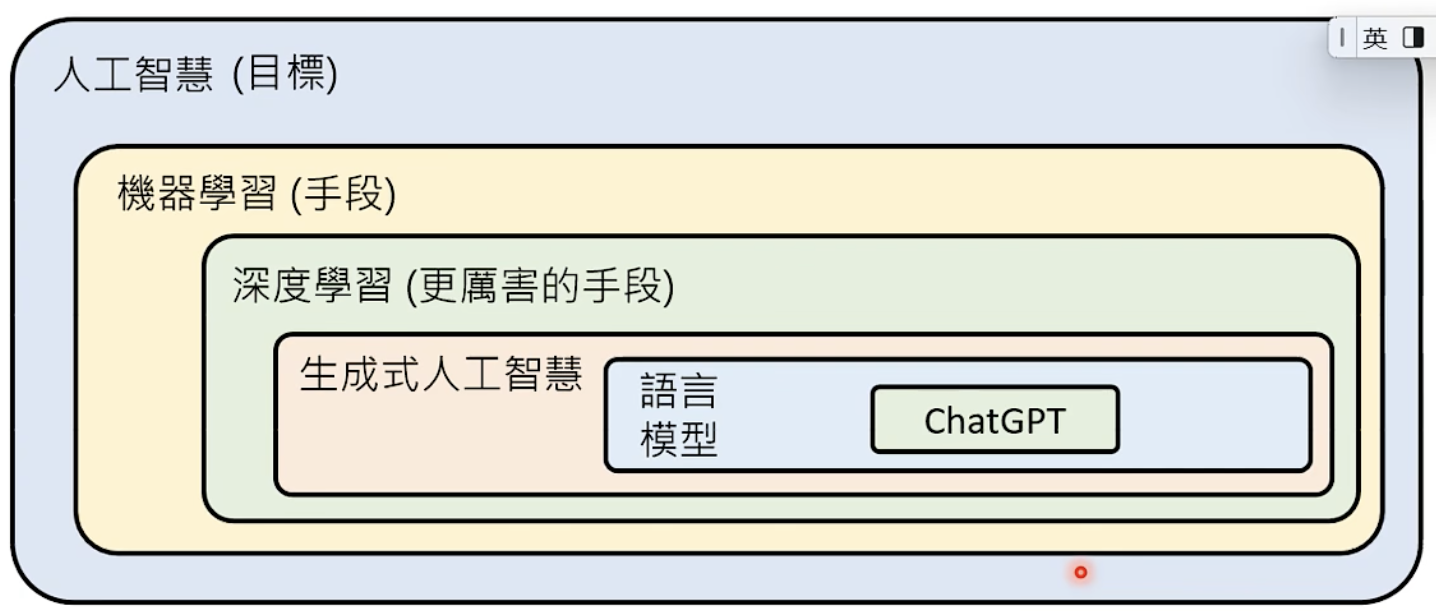
Generative AI
ChatGPT
G:generative
P:pre-trained
T:transformer
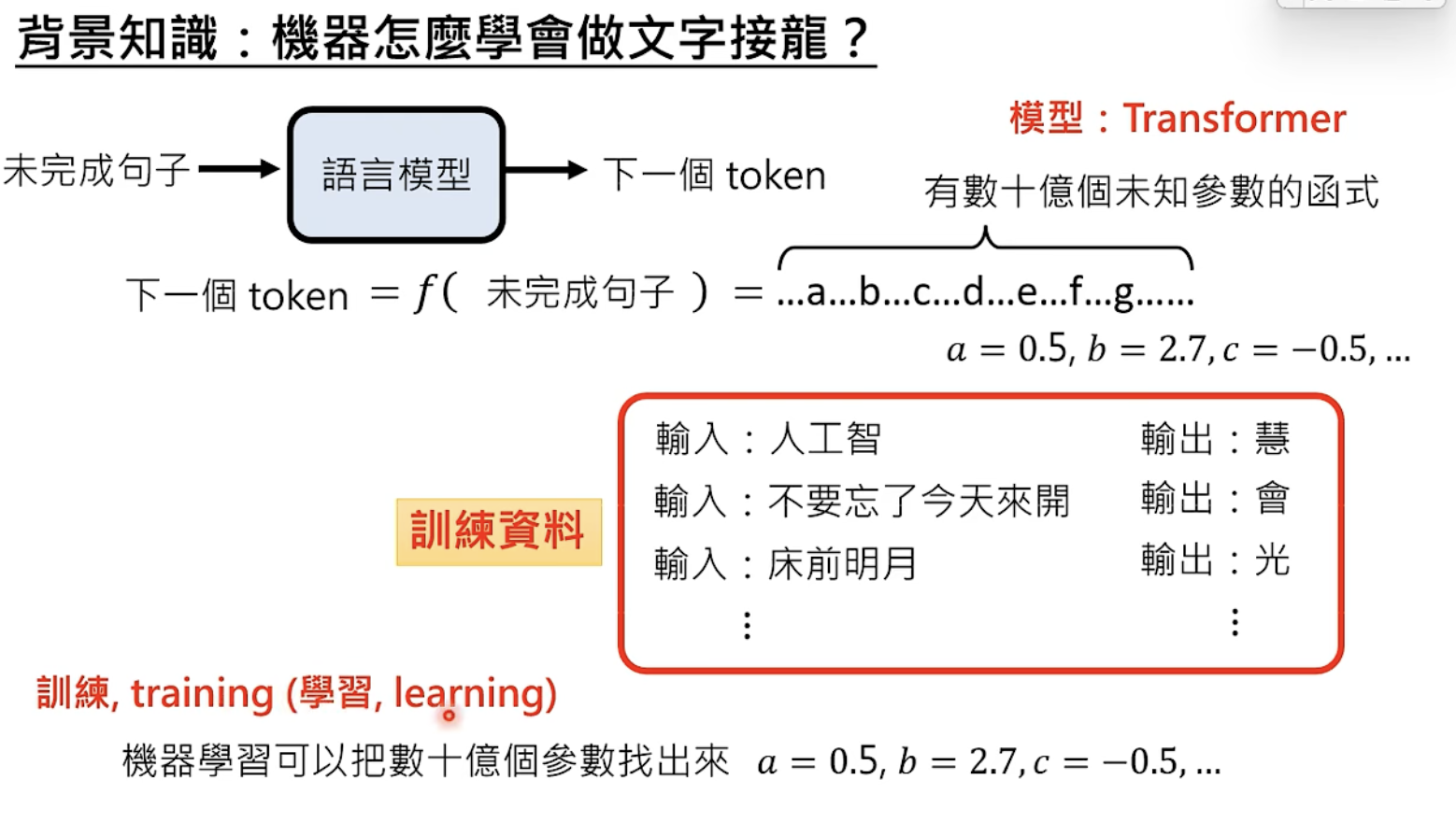
ChatGPT 真正做的事:文字接龙
Autoregressive Generation:逐个生成
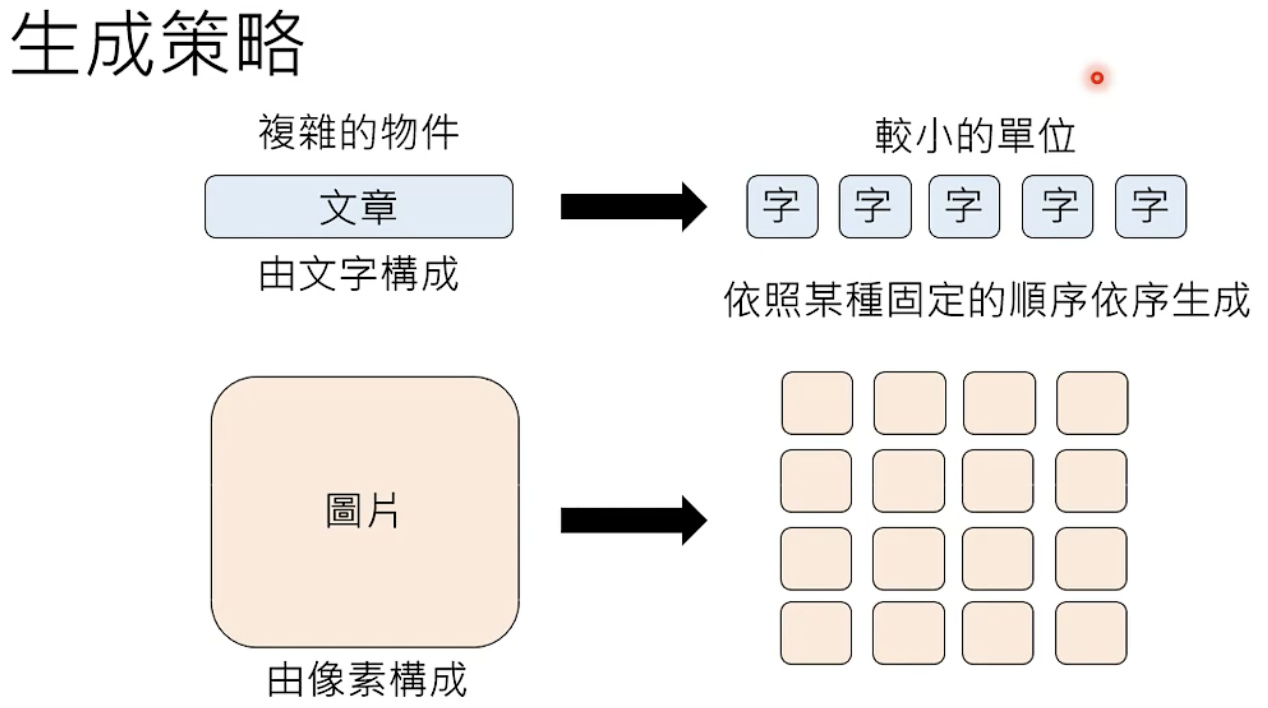
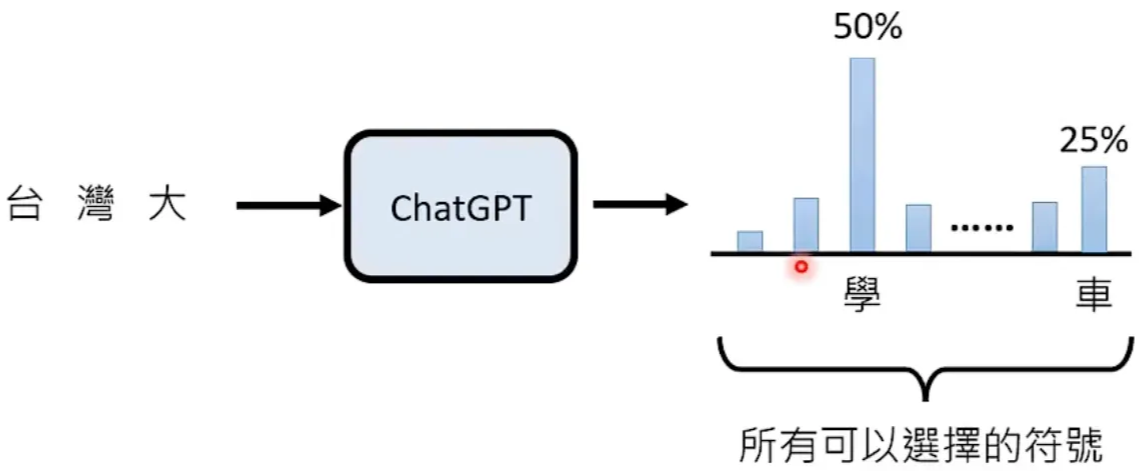
token
文字接龙时可以选择的符号

每次回答都随机(掷骰子)

进化关键:自督导式学习(预训练) ➡️ 督导式学习(微调) ➡️ 强化学习
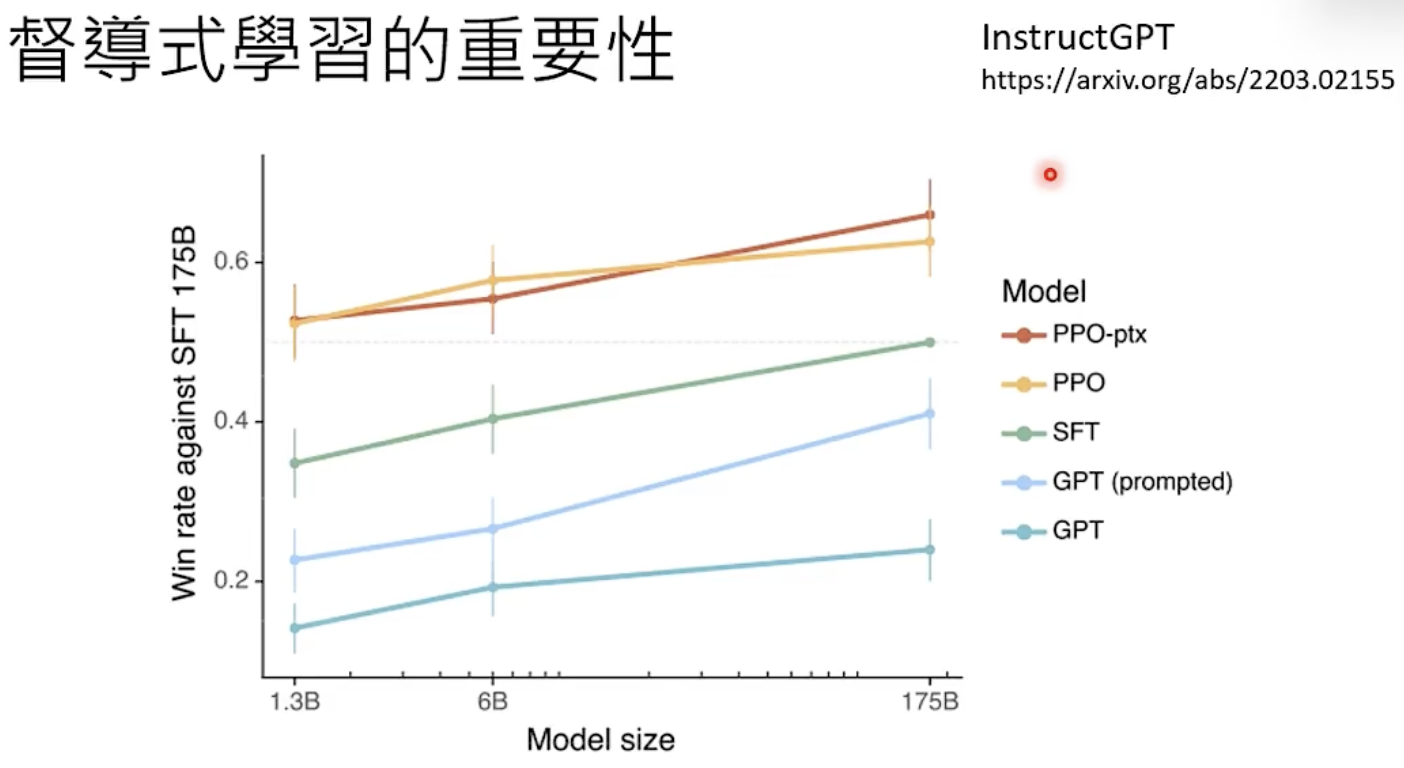
有预训练,督导式学习不用大量资料。
强化学习提供回馈。督导式学习提供完整资料,强化学习给反馈(如两次答案,有没有比上次更好)
【注】:模型要有一定程度的能力才适合进入强化学习。
Alignment(对齐):督导式学习 + 强化学习
强化学习
学习reward model
reward model:模仿人类的偏好
用reward model进行学习
模型只需要向reward model学习
GPT-4: 可以看图+引导
如何激发gpt的能力?
把需求说清楚;提供咨询;提供范例;鼓励gpt想一想;训练generator;上传资料;使用其它工具;大任务拆解成小任务;gpt会反省…
可以做什么?
- prompt engineering
- 训练自己的模型(如调整LLaMA参数),困难
大型语言模型训练过程
自我学习阶段
调整超参数
训练成果,但测试失败:找到多样数据
找到合适的初始参数:随机/ 先验知识
先验知识:爬网络资料+资料清理(训练资料品质分类器/除重)
人类指导阶段