GraphRAG
特点
- 基于图的检索:GraphRAG 引入知识图谱来捕捉实体、关系及其他重要元数据。
- 层次聚类:GraphRAG 使用 Leiden 技术进行层次聚类,将实体及其关系进行组织。
- 多模式查询:支持多种查询模式。
- 全局搜索:利用社区总结来进行全局性推理。
- 局部搜索:通过扩展相关实体的邻居和关联概念来进行具体实体的推理。
- DRIFT 搜索:结合局部搜索和社区信息,提供更准确和相关的答案。
- 图机器学习:集成图机器学习技术,并提供来自结构化和非结构化数据的深度洞察。
- Prompt 调优:提供调优工具,帮助根据特定数据和需求调整查询提示,提高结果质量。
工作流程
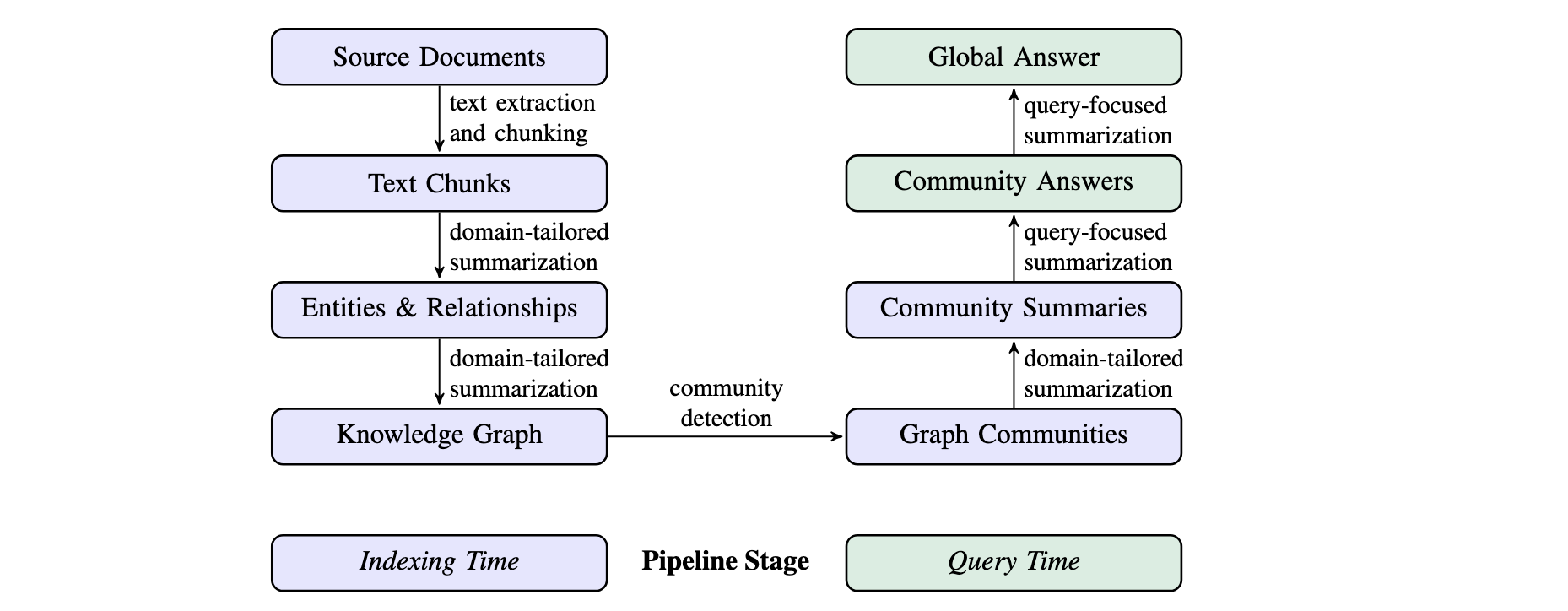
1 索引 (Indexing) 过程
将原始文档转化为知识图谱
实体提取
文本单元切分:将输入文本分割成固定大小的 TextUnits,每个块拥有唯一的ID。
实体和关系提取:使用 LLM 分析每一个 TextUnits ,根据预设的 Prompt 提取出其中的实体(Entities)和关系(Relationships)。
默认情况下:实体类型包括地理位置(Geo)、人物(Person)、事件(Event)和组织(Organization)。
去重与描述总结:系统尝试对提取出的信息进行去重(对同名同类型实体、具有相同源节点和目标节点的关系 进行分组)。然后,再次调用 LLM 将一个实体或关系在所有文本块中的简短描述汇总,生成一个更全面详细的最终描述。
图构建:使用
NetworkX库将所有实体和关系表示为图的节点(Nodes)和边(Edges),并计算节点的度(degree)等结构化信息。可使用 Neo4j 对生成的图谱进行可视化。
图分区与社区报告
图分区:使用 Leiden算法(一种层级聚类算法)将图划分为多个社区。
社区是一组内部连接比外部连接更紧密的节点集合。Leiden算法的层级特性使得社区可以有不同的粒度,level 越高,社区的主题越具体。
生成社区报告:系统为每个社区调用 LLM 生成一份详细的报告,概述其主要事件或主题。LLM的上下文包含了该社区内的所有实体、关系和声明。
缩减上下文:
层级替换:用子社区的报告来替代其内部的实体和关系等原始文本,优先替换包含实体最多的子社区
裁剪:如果替换后仍然过长,则根据节点度等指标移除最不重要的实体和关系
生成嵌入向量 (
generate_embeddings):系统为所有文本单元、实体描述和社区报告(包含标题、摘要、报告全文和评级)创建 Embeddings 用于语义搜索。
2 查询 (Querying) 过程
利用构建好的图谱来回答用户问题
局部搜索:
适用于具体、明确的问题
检索相关实体:系统将用户查询嵌入为向量,并与知识库中所有实体的描述向量进行语义相似度计算,找出最相似的 N 个实体。这N个实体被称为候选实体。
构建候选集:系统会围绕候选实体进行扩展,构建四个候选集:
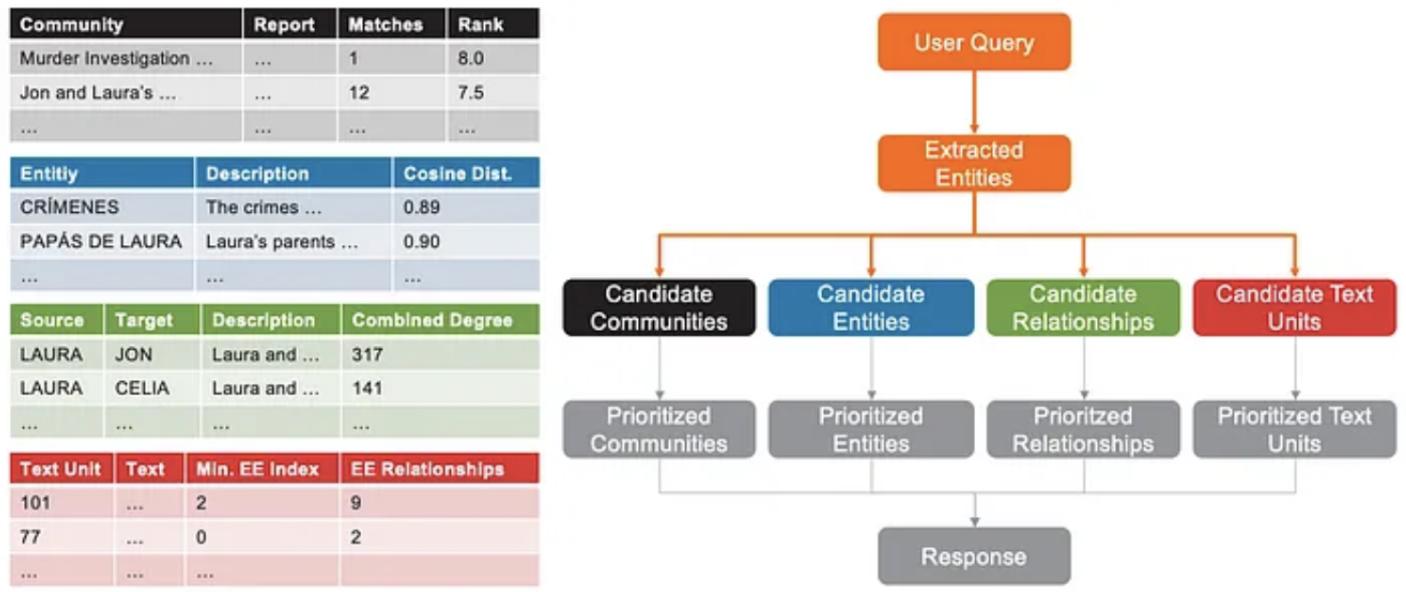
- 候选社区:所有包含至少一个候选实体的社区
- 候选实体:检索出的最相似的 N 个实体
- 候选关系:所有以候选实体为源节点或目标节点的边
- 候选文本单元:所有包含至少一个候选实体的原始文本块
上下文排序与筛选:由于LLM的上下文窗口有限,必须对候选集进行排序,以确保最重要的信息被优先送入模型。排序规则:
- 社区排序:按社区内候选实体出现的文本单元数量(
matches)降序排列,若相同则按社区重要性(rank)排序 - 关系排序:网络内关系优先于网络外关系。网络内关系按组合度(
combined_degree,源和目标节点度之和)排序;网络外关系则按其连接到网络内实体的数量排序 - 文本单元排序:首先按照其关联的候选实体的语义相似度顺序排序,其次按关联的关系数量排序
- 社区排序:按社区内候选实体出现的文本单元数量(
生成最终答案:将经过排序和筛选后的社区报告、实体描述、关系描述和文本单元拼接成一个完整的上下文,并将其与用户问题一起提交给LLM,生成最终的详细回答
全局搜索:
适用于宽泛、总结性的主题问题。
- 社区加权与分批:系统首先计算每个社区的出现权重(
occurrence_weight),该权重反映了社区相关实体在整个文档中的普遍程度。然后,所有社区被打乱顺序并分成多个批次(batch),以减少偏差 - 生成中间回答 (Map阶段):对于每个社区批次,LLM会以该批次的社区报告为上下文,生成多个对用户问题的回答,并为每个回答打分(0-10分),以评估其相关性
- 排序与汇总:所有生成的中间回答会根据分数进行全局排序,分数过低的回答被舍弃
- 生成最终答案 (Reduce阶段):最后,系统将所有高质量的中间回答文本拼接成一个新的上下文,再次提交给LLM,要求其基于这些信息生成一个全面、连贯的最终答案
- 社区加权与分批:系统首先计算每个社区的出现权重(
Prompt 调优
可进行 Prompt 调优,确保模型可以根据给定的特定数据和查询需求进行优化,提供更准确和相关的答案。
QuickStart
数据集:./ragtest/input
初始化工作区
graphrag init --root ./ragtest这将创建两个文件:
.envandsettings.yamlin./ragtest.env包含运行 GraphRAG 管道所需的环境变量。环境变量GRAPHRAG_API_KEY=<API_KEY>.替换为<API_KEY>——OpenAI 或 Azure API keysettings.yaml包含管道的设置
run the pipeline
graphrag index --root ./ragtest可以看到一个名为
./ragtest/output的新文件夹,其中包含一系列 parquet 文件Using the Query Engine
使用 Global search 提出 high-level question:
graphrag query \ --root ./ragtest \ --method global \ --query "What are the top themes in this story?"使用 Local search 询问更具体的问题:
graphrag query \ --root ./ragtest \ --method local \ --query "Who is Scrooge and what are his main relationships?"
返回更多信息:https://microsoft.github.io/graphrag/query/overview/
可视化:https://microsoft.github.io/graphrag/visualization_guide/