Lift-splat-shoot
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
1. 关键:Lift
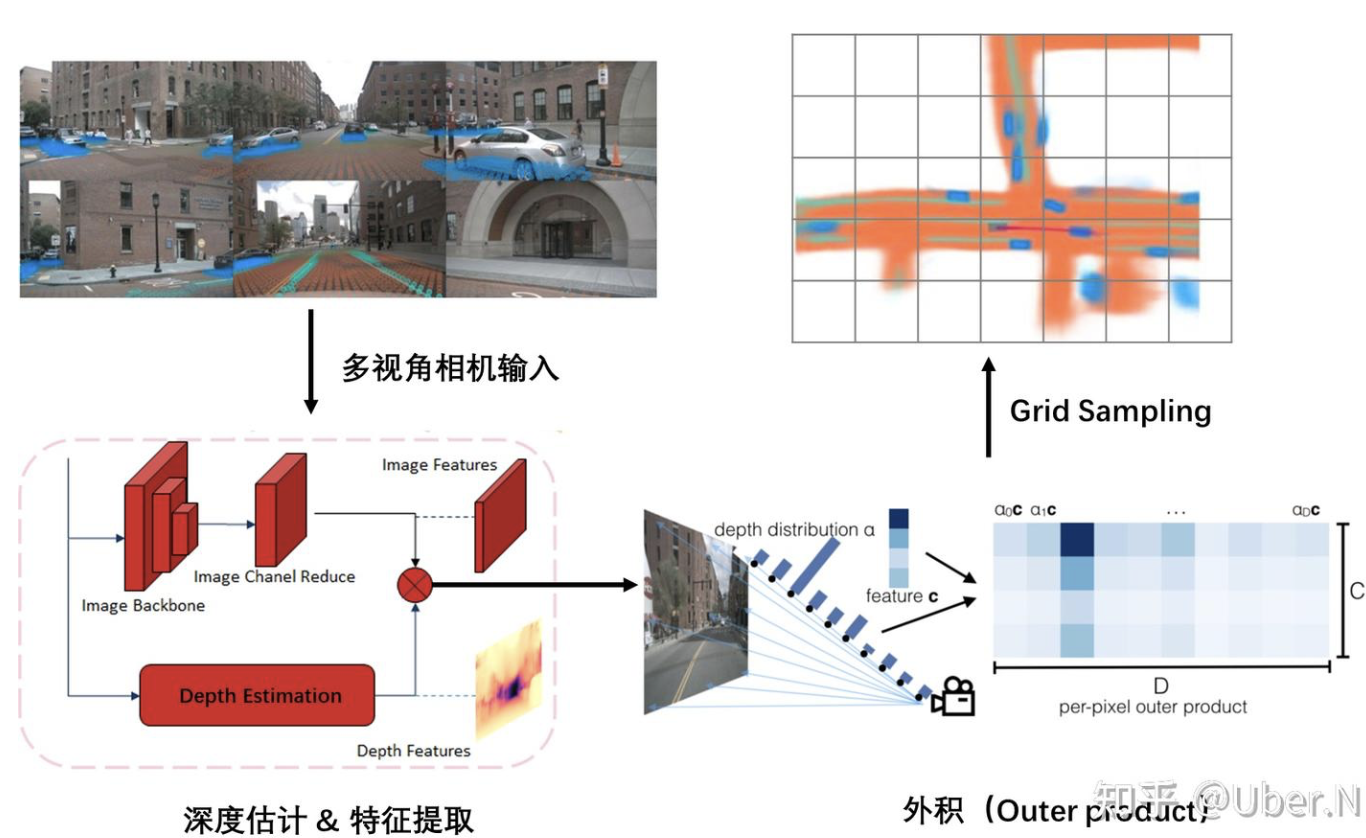
特征提取&深度估计
多视角相机输入后,进行特征提取与深度估计
外积(Outer product)—— 最核心的操作
无法确定每个 pixel 的特征投影 BEV 视角下的具体位置;对于每个 pixel 特征,使用的是“all possible depths”。
使用外积操作,将 Image feature (H * W * C) 和 Depth feature (H * W * D)构造成一个(H * W * D * C) 的 Frustum feature。
Grid Sampling
目的:将构造出的 Frustum Feature 利用相机外参和内参转换到BEV视角下。
过程:通过限定好 BEV 视角的范围,划定好一个个的 grid,将能够投影到相应 grid 的 Feature 汇总到一个 grid 里。
- 缺点:
极度依赖Depth信息的准确性,且必须显示地提供Depth 特征。
一个好的解决方法是先预训练好一个较好的Depth权重,使得LSS过程中具有较为理想的Depth输出。
外积操作过于耗时。
2. LSS完整流程
生成视锥,并根据相机内外参将视锥中的点投影到 ego 坐标系
生成视锥
其位置是基于图像坐标系的,同时锥点是图像特征上每个单元格映射回原始图像的位置
锥点由图像坐标系向 ego 坐标系进行坐标转化
主要涉及到相机的内外参数
对环视图像完成特征的提取,并构建图像特征点云
利用 Efficientnet-B0 主干网络对环视图像进行特征提取。
输入的环视图像 (bs, N, 3, H, W),在进行特征提取之前,会将前两个维度进行合并,一起提取特征,对应维度变换为 (bs, N, 3, H, W) -> (bs * N, 3, H, W)
特征融合
对其中的后两层特征进行融合,丰富特征的语义信息,融合后的特征尺寸大小为 (bs * N, 512, H / 16, W / 16)
估计深度
估计深度方向的概率分布,并输出特征图每个位置的语义特征 (用64维的特征表示);整个过程用1x1卷积层实现。
对上一步骤估计出来的离散深度,利用softmax()函数计算深度方向的概率密度
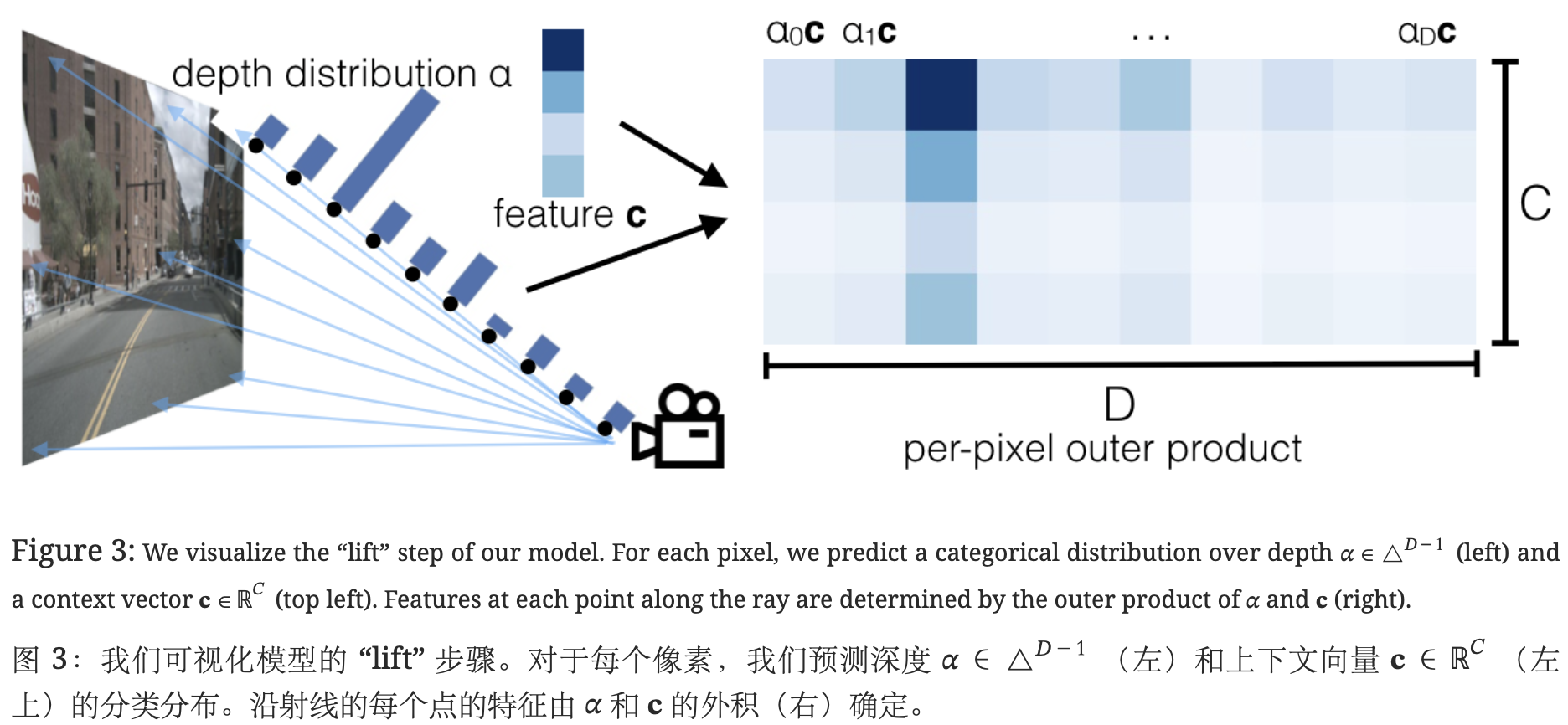
外积
利用得到的深度方向的概率密度和语义特征,通过外积运算构建图像特征点云
利用变换后的 ego 坐标系的点与图像特征点云利用 Voxel Pooling 构建 BEV 特征
Voxel Pooling 前的准备工作
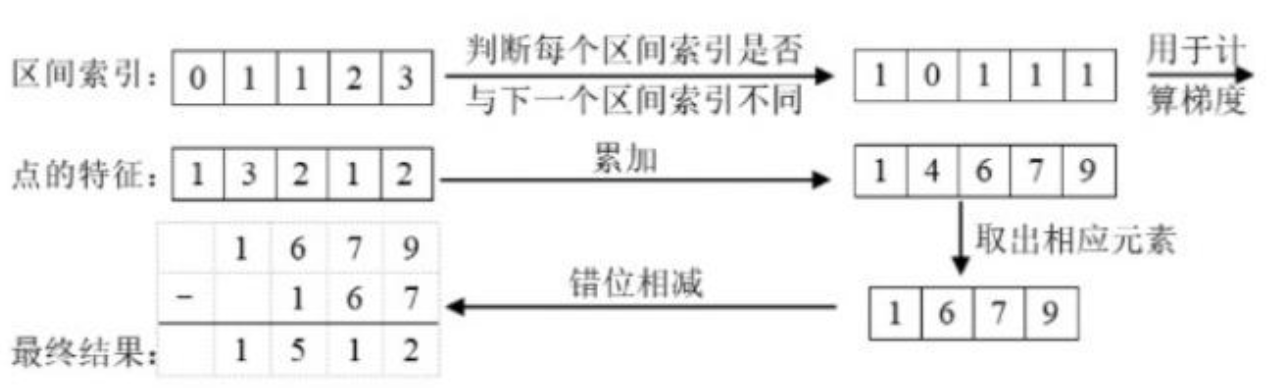
数据展平与坐标转换、边界过滤、排序与分组、累积求和、网格化输出
采用cumsum_trick完成Voxel Pooling运算
前向传播:计算前缀和、筛选体素边界点、差分计算恢复原始特征。
反向传播:梯度会从最后一个点累积到前面的点
对生成的 BEV 特征利用 BEV Encoder 做进一步的特征融合
利用特征融合后的 BEV 特征完成语义分割任务
最后将输出的语义分割结果与 binimgs 的真值标注做基于像素的交叉熵损失,从而指导模型的学习过程。
论文阅读
本文提出了一种架构,旨在从任意摄像机装备推断鸟瞰图表示。
Introduction
目标:从任意数量的摄像机中直接提取给定图像数据的场景的鸟瞰图表示。
单视图扩展成多视图的对称性:
- 平移等方差: 如果图像中的像素坐标全部偏移,则输出将偏移相同的量。
- Permutation invariance: 最终输出不取决于 n 相机的特定顺序。
- 自我框架等距等方差: 无论捕获图像的相机相对于自我汽车的位置如何,都会在给定图像中检测到相同的对象。
缺点:反向传播不能用于使用来自下游规划器的反馈来自动改进感知系统。
传统在与输入图像相同的坐标系中进行预测,我们的模型遵循上述对称性,直接在给定的鸟瞰图框架中进行预测,以便从多视图图像进行端到端规划。
Related Work
- 单目物体检测
- 在图像平面中应用一个成熟的 2D 对象检测器,然后训练第二个网络将 2D 框回归到 3D 框。
- 伪激光雷达:训练一个网络进行单目深度预测,另一个网络分别进行鸟瞰检测。
- 使用 3 维对象基元,
- BEV 框架中的推理:使用 extrinsics 和 intrinsics 直接在鸟瞰框架中执行推理
- MonoLayout:从单个图像执行鸟瞰图推理,并使用对抗性损失来鼓励模型对合理的隐藏对象进行修复。
- Pyramid Occupancy Networks:提出了一种 transformer 架构,将图像表示转换为鸟瞰图表示。
- FISHING Net:提出了一种多视图架构,既可以分割当前时间步中的对象,也可以执行未来预测。
- 单目物体检测
Method
对每个图像,都有一个 extrinsic matrix 和 intrinic matrix,它们共同定义每个相机从参考坐标 (x,y,z) 到局部像素坐标 (h,w,d) 的映射。
核心流程:
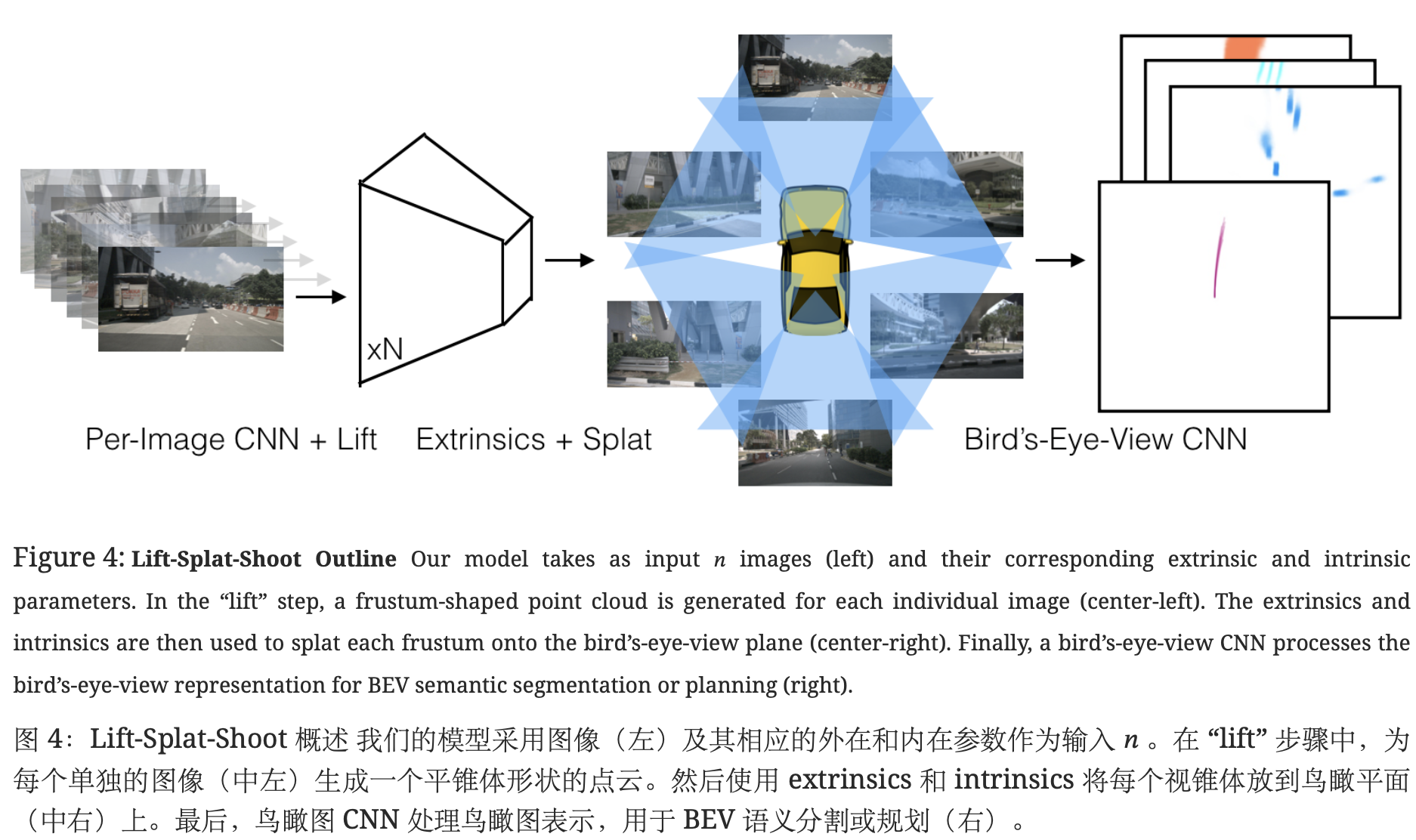
Lift:将2D图像特征显式提升到3D空间(通过深度估计生成视锥特征)。
Splat:将3D特征“展开”到BEV空间,构建鸟瞰图特征。
Shoot:基于BEV特征进行运动规划或轨迹预测。
Lift:潜在深度分布
目的:将每个图像从本地 2 维坐标系 “提升” 到在所有摄像机之间共享的 3 维帧。
Splat:支柱池
lift输出:大点云
将每个点分配给最近的 pillar,并执行总和池化,以创建一个可由标准 CNN 处理以进行鸟瞰推理的 C×H×W 张量。(pillars 是具有无限高度的体素)
- 加速:不是填充每个 pillar 然后执行 sum pooling,而是通过使用 packing 和利用 “cumsum 技巧” 进行 sum pooling 来避免填充。
Shoot: 运动规划
定义 planning:预测自我车辆在模板轨迹上的 K 分布。
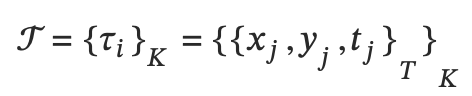
在测试时,实现使用 inferred cost map 的 planning:
通过“射击”不同的轨迹,对它们的成本进行评分,然后根据最低成本轨迹采取行动。
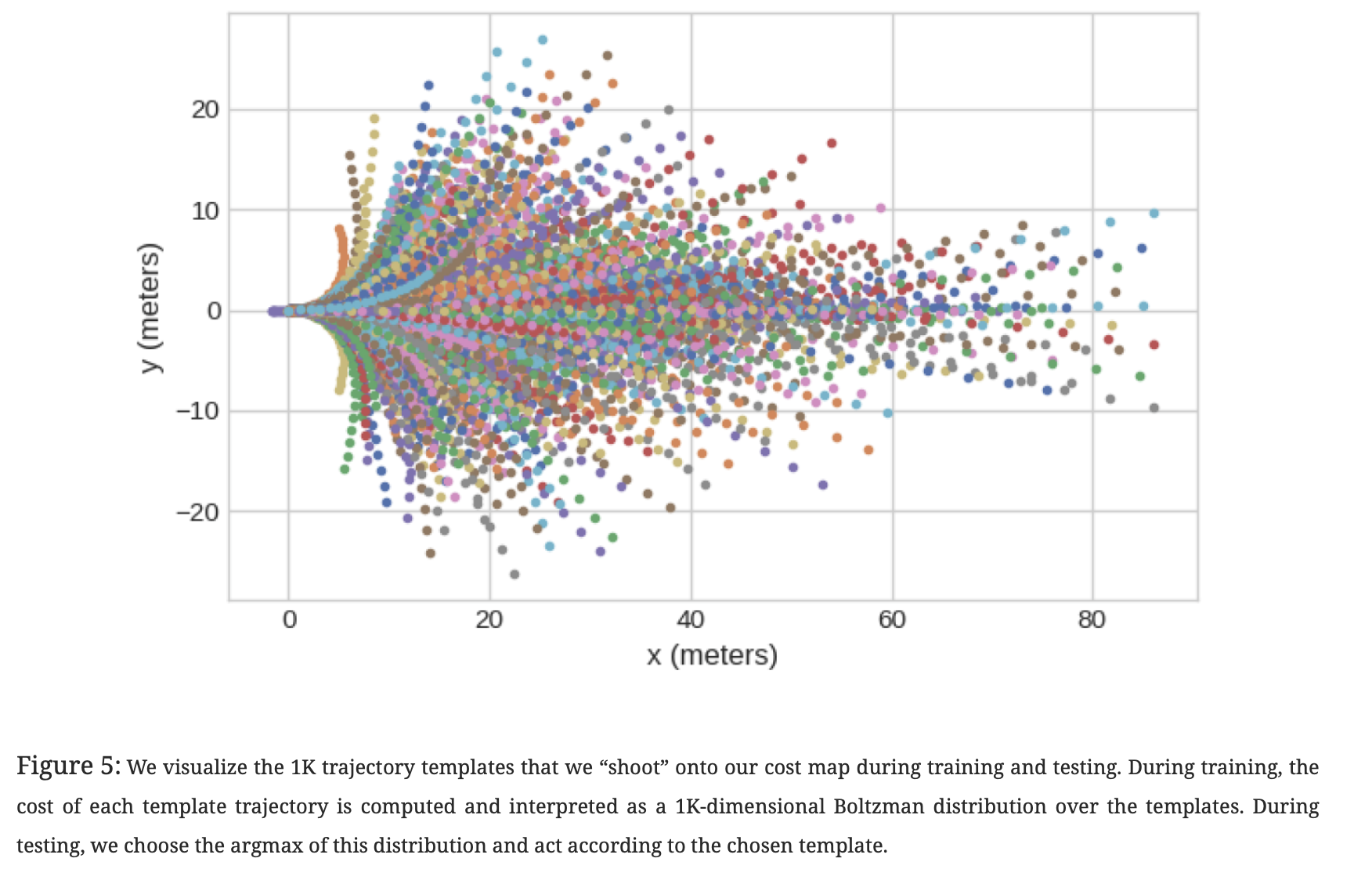
在实践中,我们通过在大量 template trajectories 上运行 K-Means 来确定模板轨迹集。
Implementation
模型有两个大型网络主干,由 lift-splat 层连接起来。
其中一个主干 对每个图像单独进行操作,以便对每个图像生成的点云进行特征化。
利用了在 Imagenet 上预训练的 EfficientNet-B0 中的层。
另一个主干 在点云被展开到参考系中的pillars后,对点云进行操作。
使用类似于 PointPillars 的 ResNet 块组合。
- 技巧:
- 选择了跨 pillar 的 sum pooling,而不是 max pooling :免于因填充而导致的过多内存使用。
- Frustum Pooling:将 n 图像产生的视锥转换为固定维度 C×H×W 的张量,而与相机 n 的数量无关。