LLM - 2.预训练阶段

1 预训练数据
目标:构造海量“高质量”数据。
1.1 数据来源
数据来源可分为两类:通用数据和专用数据。
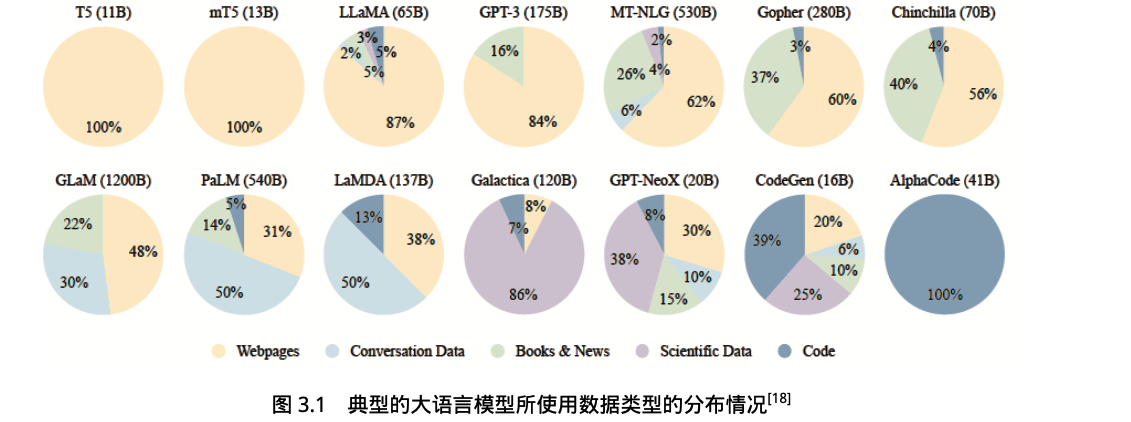
通用数据
网页、对话文本、书籍、多语言数据、科学文本、百科、代码…
专业数据
金融领域、医疗领域、法律领域…
1.2 数据处理

1. 质量过滤
基于分类器的方法
目标:训练文本质量判断模型,利用该模型识别并过滤低质量数据。
分类器使用一组精选文本(维基百科、书籍等)进行训练,给于训练数据类似的网页较高分数,从而可以评估网页的内容质量。
基于启发式的方法
通过一组精心设计的规则来消除低质量文本。
规则:语言过滤、指标过滤、统计特征过滤、关键词过滤…
2. 冗余去除
在不同的粒度上去除重复内容(包括句子、文档和数据集等粒度)。
- 句子级别:删除包含大量重复单词或者短语的句子
- 文档级别:依靠文档之间的表面特征相似度(例如 n-gram 重叠比例)进行检测并删除重复文档
- 数据集级别:从句子、文档、数据集三个级别去除重复
3. 隐私消除
从预训练语料库中删除包含个人身份信息的内容。
4. 词元切分
未登录词 (OOV):不在词表中的词,模型无法为其生成对应的表示。通常用[UNK]表示。
子词(Subword)词元化
词元表示模型会维护一个词元词表,其中既存在完整的单词,也存在形如"c" “re"等单词的部分信息,称为子词。
词元分析(Tokenization)是将原始文本分割成词元序列的过程。
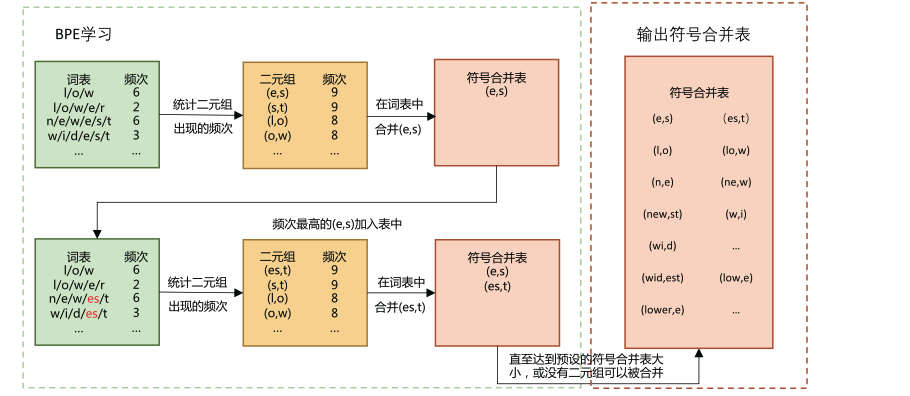
字节对编码
一种常见的子词词元算法。采用的词表包含 最常见的单词 和 高频出现的子词。
常见词通常位于 BPE 词表中;罕见词通常能被分解为若干个包含在 BPE 词表中的词元。
BPE 中词元词表计算过程
WordPiece
一种常见的词元分析算法。在每次合并时,选择使得训练数据似然概率增加最多的词元对。
- 度量方法如:根据训练数据库中两个词元的共现计数除以它们各自的出现计数的乘积
1.3 数据影响分析
1. 数据规模
- 模型大小加倍,则训练词元数量也应该加倍
- 对于给定训练计算量目标,存在一个最佳模型参数量和训练数据量配置
- 随着训练数据量的增加,模型在任务的数据集上的性能都在稳步提高
- 仅对模型进行 10M∼100M个词元的训练,就可以获得可靠的语法和语义特征。然而,需要更多的训练数据才能获得足够的常识知识和其他技能,并在典型的下游自然语言理解任务中取得较好的结果
2. 数据质量
- 大量重复的低质量数据甚至导致训练过程不稳定,造成模型训练不收敛
- 语言模型在经过清洗的高质量数据上训练可以得到更好的性能
- 数据时效性对于模型效果有影响
- 重复数据对于语言模型建模具有重要影响
3. 数据多样性
通过使用不同来源的数据进行训练,大语言模型可以获得广泛的知识。
1.4 开源数据集
包括 Pile, ROOTS, RefinedWeb, CulturaX, SlimPajama…
2 分布式训练
目标:解决海量的计算和内存资源需求问题
分布式训练:将机器学习或深度学习模型训练任务分解成多个子任务,并在多个计算设备(如中央处理器(CPU)、图形处理器(GPU)、张量处理器(TPU)和神经网络处理器(NPU))上并行训练。

2.1 分布式训练的并行策略
目标:将单节点模型训练转换成等价的分布式并行模型训练
1. 数据并行
每个计算设备只分配一个批次数据样本的子集。计算完成后,所有计算设备聚合其他加速卡给出的梯度值,然后使用平均梯度对模型进行更新,完成该批次训练。
2. 模型并行
流水线并行
并行气泡/流水线气泡:下游设备需要长时间持续处于空闲状态,等待上游设备计算完成,才能开始计算自身的任务。
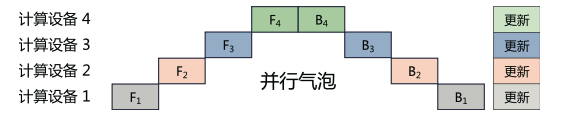
GPipe 方法:将小批次进一步划分成更小的微批次。

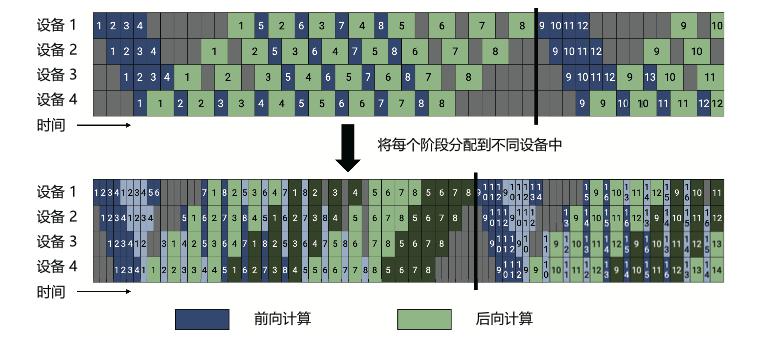
1F1B 非交错式调度模式:
- 热身阶段,在计算设备中进行不同数量的前向计算
- 前向-后向阶段,计算设备按顺序执行一次前向计算,然后进行一次后向计算
- 后向阶段,计算设备完成最后一次后向计算
1F1B 交错式调度模式:
张量并行
关注如何将参数切分到不同设备,以及如何保证切分后的数学一致性这两个问题
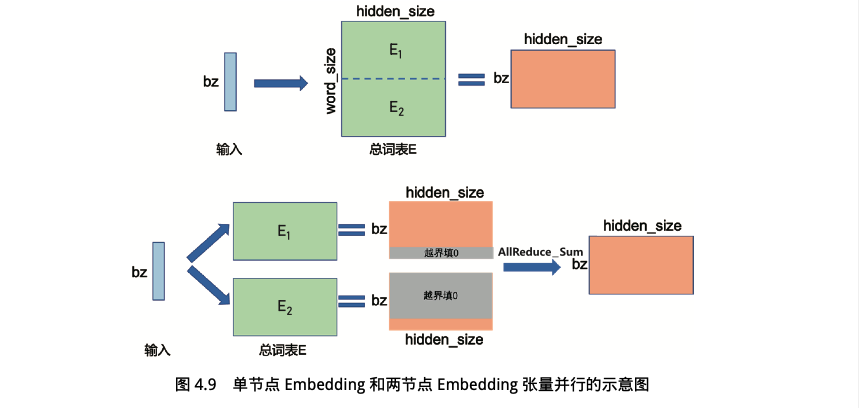
嵌入式表示(Embedding)
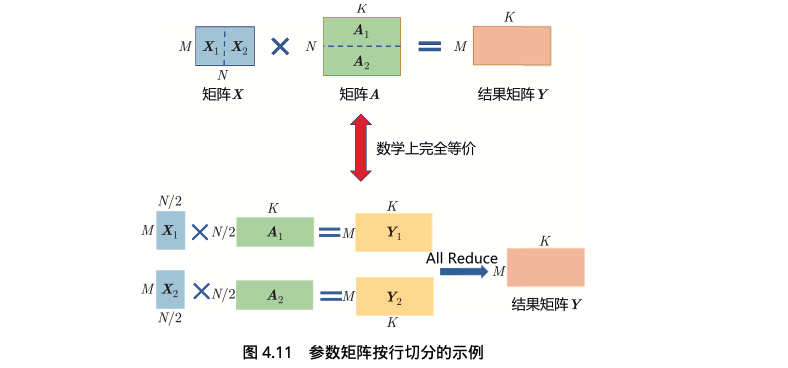
矩阵乘(MatMul)
交叉熵损失(Cross Entropy Loss)
按照类别维度切分,同时通过中间结果通信,得到最终的全局交叉熵损失。
3. 混合并行
将多种并行策略如数据并行、流水线并行和张量并行等混合使用。
4. 计算设备内存优化
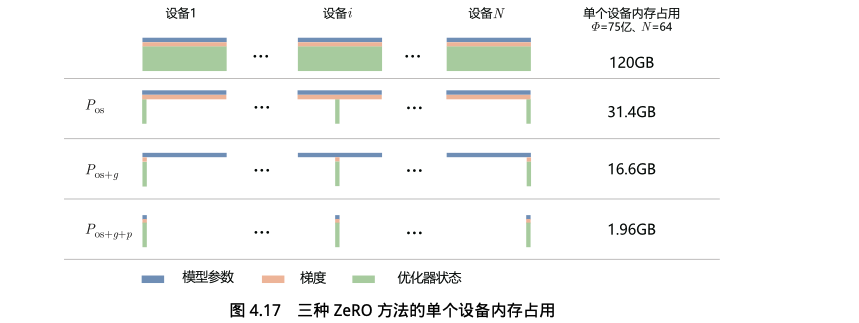
零冗余优化器(ZeRO)的目标:针对模型状态的存储进行去除冗余的优化
- 对 Adam 优化器状态进行分区
- 对模型梯度进行分区
- 对模型参数进行分区
2.2 分布式训练的集群架构
属于高性能计算集群,目标是提供海量的计算能力。
有两种常见架构:参数服务器架构 和 去中心化架构。
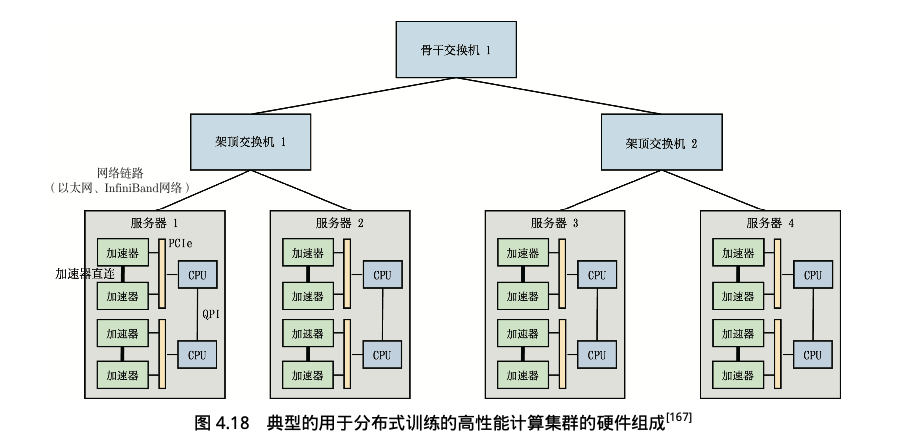
1. 高性能计算集群的典型硬件组成
2. 参数服务器架构
系统中有两种服务器角色:训练服务器和参数服务器。
训练服务器
提供大量的计算资源,将分配到此服务器的训练数据集切片并进行计算,将得到的梯度推送到相应的参数服务器。
参数服务器
提供充足的内存资源和通信资源,等待两个训练服务器都完成梯度推送,再计算平均梯度并更新参数。
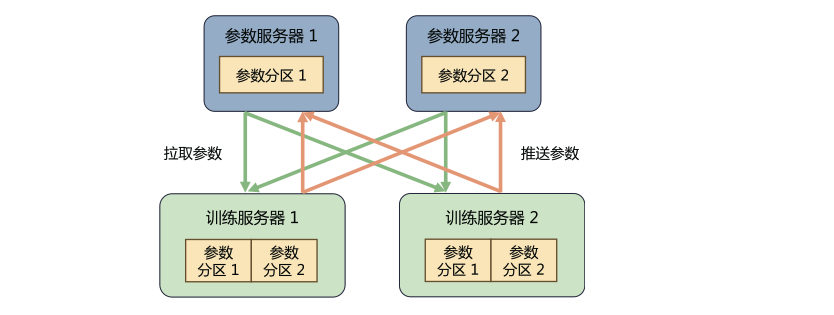
- 分类
- 同步训练:参数服务器在收到所有训练服务器的梯度后,进行梯度聚合和参数更新。
- 异步训练:参数服务器不再等待接收所有训练服务器的梯度,而是直接基于已收到的梯度进行参数更新。
3. 去中心化架构
采用集合通信实现分布式训练系统。没有中央服务器或控制节点,而是由节点之间进行直接通信和协调。
集合通信原语: Broadcast, Scatter, Reduce, All Reduce, Gather, All Gather, Reduce Scatter…
常见通信库: MPI、 GLOO、 NCCL…