LLM - 3.指令理解阶段(核心) - 指令微调

指令微调又称有监督微调,旨在使模型具备指令遵循 (Instruction Following)能力。
核心问题:如何构造指令数据?如何高效低成本地进行指令微调训练?如何在语言模型基础上进一步扩大上下文?
1. 指令微调训练
步骤
- 明确地定义相应的自然语言形式的指令或者提示
- 把训练数据调整成包含指令以及与之对应的响应的形式
- 使用包含指令和响应的训练数据对预训练模型进行微调操作
目标函数往往只是针对输出部分来计算损失
1.1 指令微调数据
组成:“指令输入”与“答案输出”
若需要模型理解多轮对话的能力,可以将对话历史都做为指令,让模型学习最后一轮的输出结果。(即,把最后一轮“Assistant”回答前的所有数据当做“输入”,最后一轮“Assistant”回答做为“输出)
1.2 数据构建方法
手动构建
- 优点:高质量、可解释性、灵活可控
现有数据集转换
整合和修改多个开源数据集,最终将它们合并成一个新数据集用于大模型指令微调。
优点:多样性和全面性、规模大、节省时间
解决数据冗余的问题:多数据集合并
自动构建指令
用大语言模型的生成能力自动构建指令。

生成任务指令
确定指令是否代表分类任务
生成任务输入和输出
非分类任务:输入优先(即先产生输入,模型再根据任务指令和输入生成输出)
分类任务:输出优先(即先产生所有可能的输出标签,再根据任务指令和输出,补充相应的输入)
目的是避免模型过多地生成某些特定类别的输入,而忽略其他的类别。
在将新生成的指令数据加入指令池之前,过滤低质量数据
1.3 数据评估与影响
评估数据
数据质量、数据多样性…
数据对结果影响
- 若能将数据质量与多样性标准有机结合,模型可以达到更好的效果
- 仅需 60 个训练样本的指令微调,就足以使大语言模型高效执行问答任务,并展现出强大的泛化能力。
- 增加训练数据并未带来显著的性能提升,反而可能损害模型表现。
1.4 指令微调训练策略
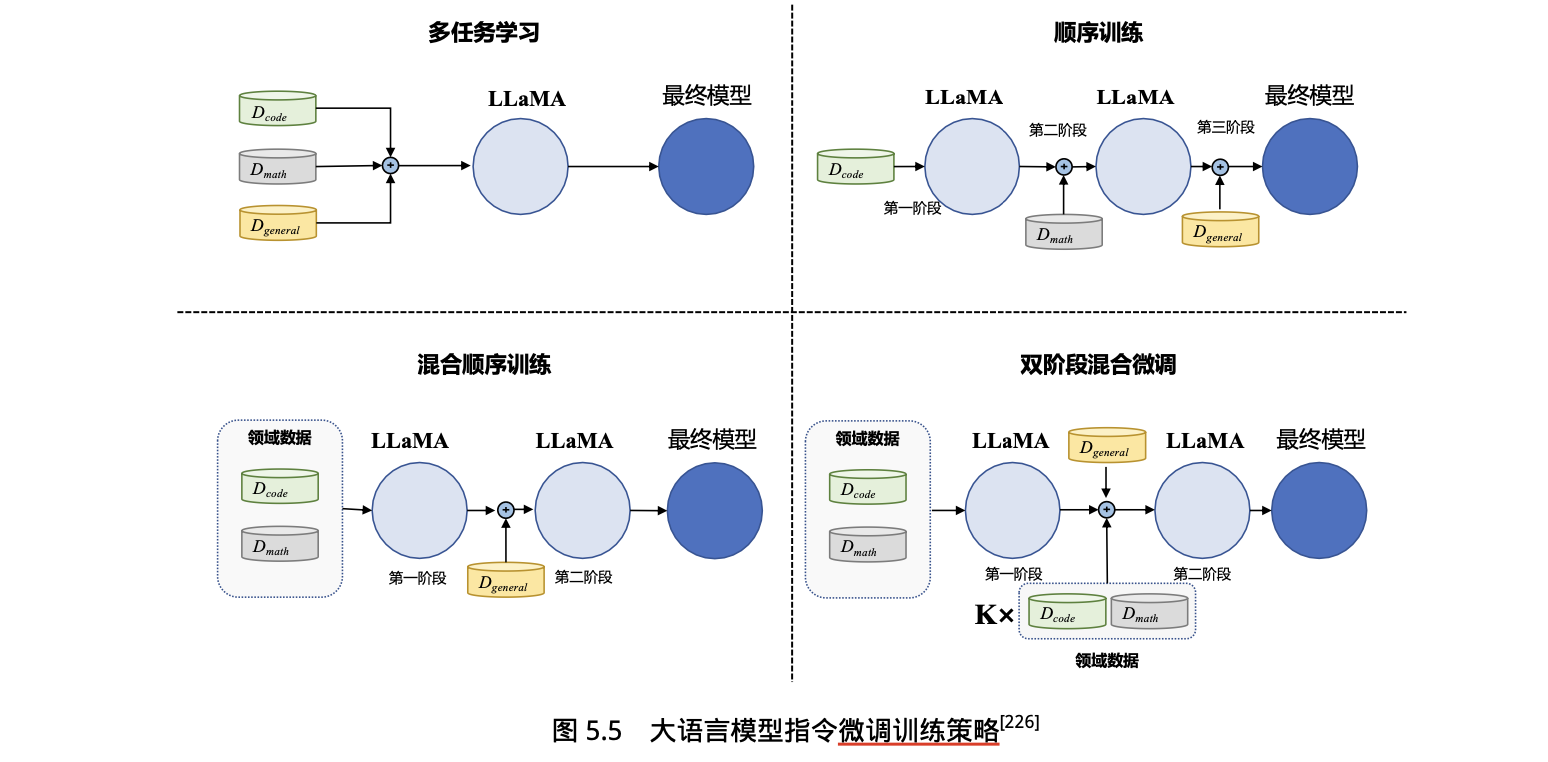
混合各类训练数据在一起可以在一定程度上增强所有任务效果。
- 开源数据集可分为 通用指令微调数据集 和 特定领域指令微调数据集
2. 高效模型微调方法
2.1 传统微调方法
微调适配器(Adapter Layer)
在 Transformer 层中的自注意力模块与 MLP 块之间、以及 MLP 模块与残差连接之间,添加适配器层(Adapter Layer)作为可训练参数。
缺点:增加网络的深度,从而在模型推理时带来额外的时间开销。
前缀微调
在输入序列前缀添加连续可微的软提示作为可训练参数。
缺点:模型可接受的最大输入长度有限,随着软提示的参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能。
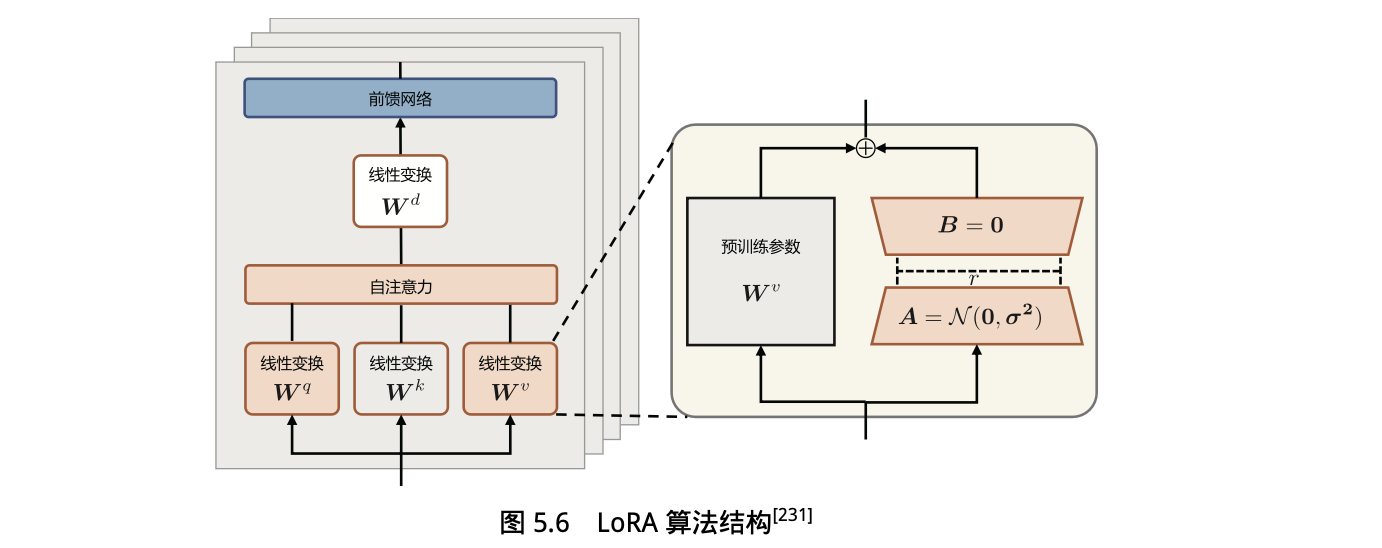
2.2 LoRA
背景:
语言模型针对特定任务微调后,权重矩阵通常具有很低的本征秩。也就是说,参数更新量即便投影到较小的子空间中,也不会影响学习的有效性。
LoRA 方法可以在缩减训练参数量和 GPU 显存占用的同时,使训练后的模型具有与全量微调相当的性能。
方法:固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量。
对于输入 x 来说,输出如下:
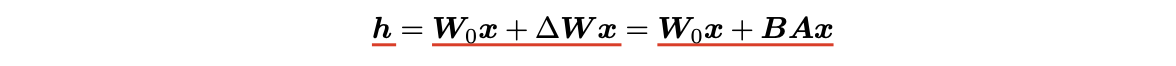
算法结构:
函数库:peft
2.3 LoRA 的变体
AdaLoRA
微调时,根据各权重矩阵对下游任务的重要性动态调整秩的大小
实现方法
直接令重要性分数等于奇异值
对可训练参数 ∆W 进行奇异值分解,令 ∆W= P Γ Q
并在损失函数中添加以下正则化项:
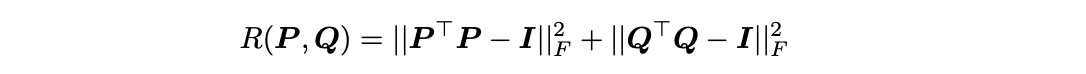
为每一组奇异值及其奇异向量计算重要性分数,根据所有组的重要性分数排序来裁剪权重矩阵,以达到降秩的目的。
计算参数敏感性
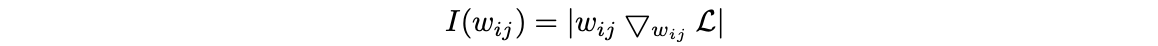
该式估计了某个参数变为 0 后,损失函数值的变化。因此, I(wij) 越大,表示模型对该参数越敏感,这个参数也就越应该被保留。
QLoRA
没有对 LoRA 的逻辑做出修改,而是通过将预训练模型量化为 4-bit 节省计算开销,并保持原本 16-bit 微调的性能。
- 实现方法
- 分页优化器:指在训练过程中显存不足时自动将优化器状态移至内存,在需要更新优化器状态时再加载回来。
- 基于分位数量化构建新的数据类型 4-bit NormalFloat(NF4):使原数据经量化后,每个量化区间中的值的数量相同。
- 双重量化:分块量化减小离群点的影响范围;为了恢复量化后的数据,需要存储每一块数据的放缩系数,故进一步对这些放缩系数进行量化。
- 实现方法
3. 上下文窗口扩展方法
3.1 增加上下文窗口的微调
采用直接的方式,即通过使用一个更大的上下文窗口来微调现有的预训练 Transformer,以适应长文本建模需求。
缺点:在扩展到更大的上下文窗口时效率较低。
3.2 具有外推能力的位置编码
外推能力源于位置编码中表征相对位置信息的部分
T5 Bias Position Embedding
直接在 Attention Map 上操作,对于查询和键之间的不同距离,模型会学习一个偏置的标量值,将其加在注意力分数上,并在每一层都进行此操作,从而学习一个相对位置的编码信息。
ALiBi
一种预定义的相对位置编码。ALiBi 在 Softmax 的结果后添加一个静态的不可学习的偏置项:
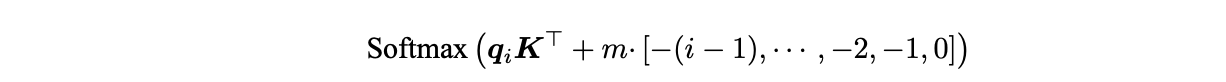
其中 m是对不同注意力头设置的斜率值。

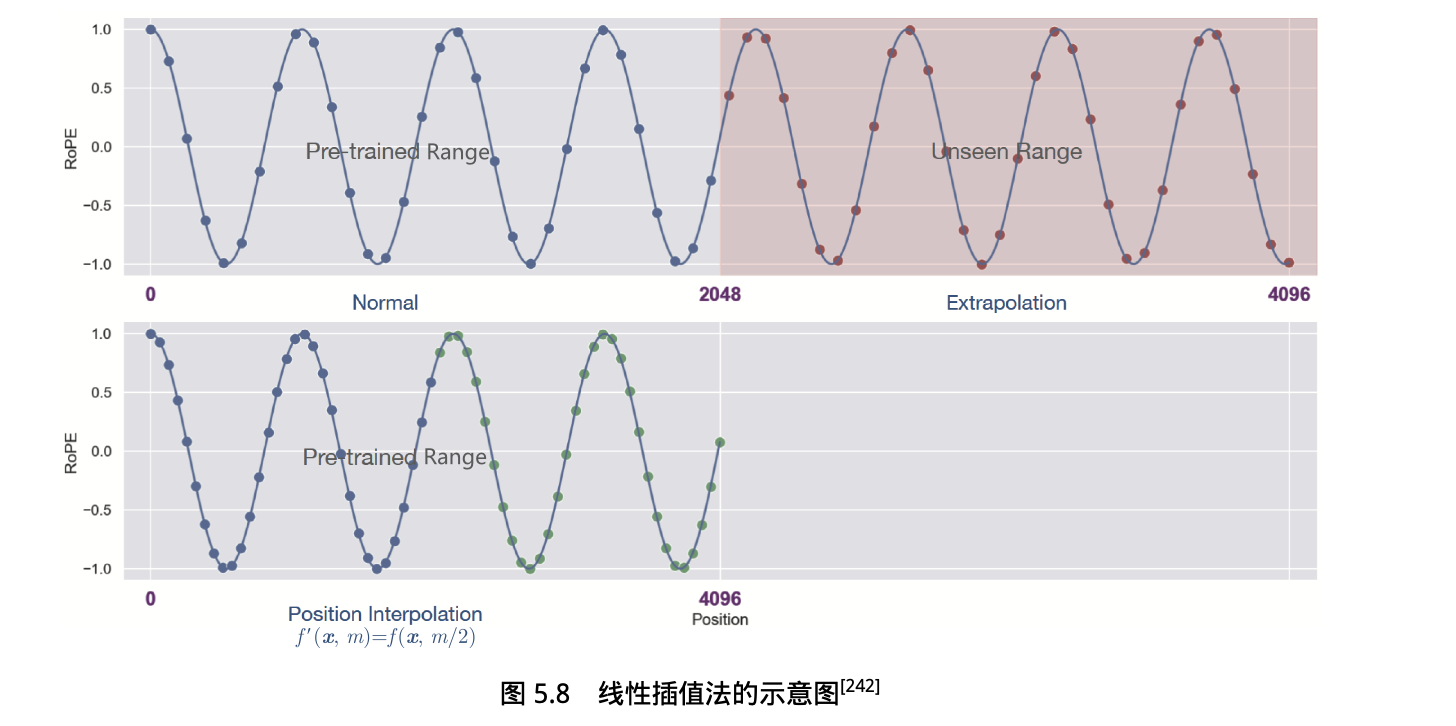
3.3 插值法
不改变模型架构而直接扩展大语言模型上下文窗口大小。
位置插值法:直接缩小位置索引,使最大位置索引与预训练阶段的上下文窗口限制相匹配。
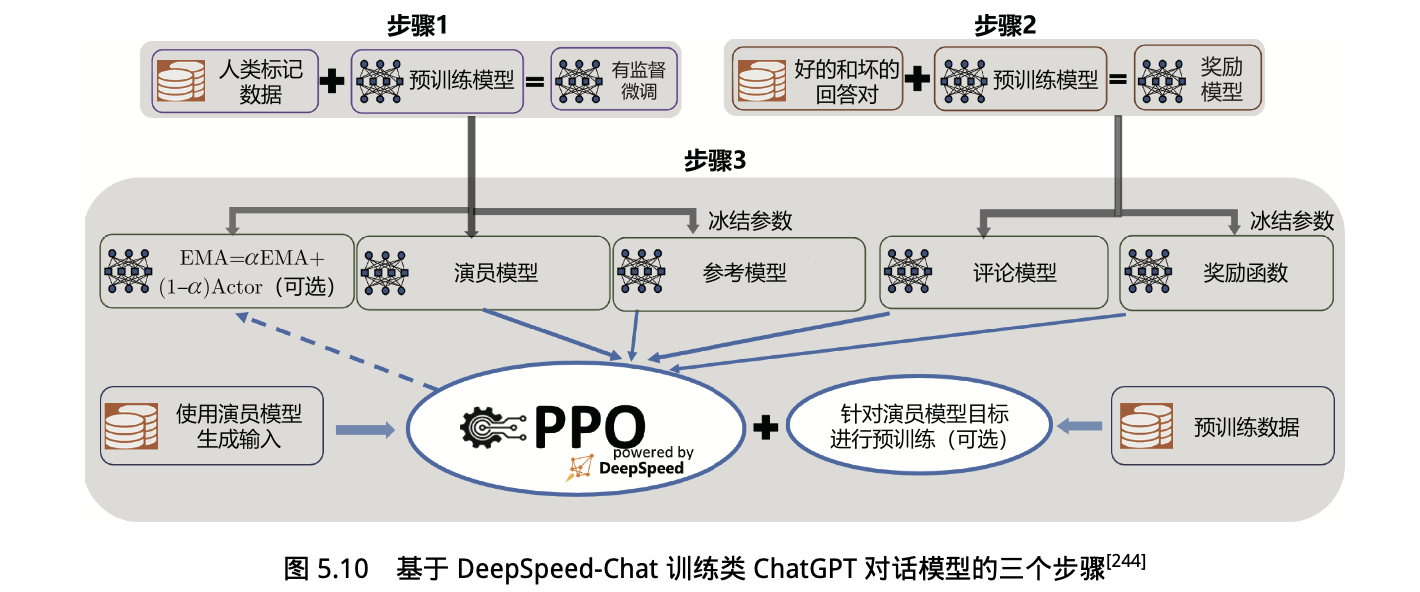
4. 指令微调实践:DeepSpeed-Chat SFT
- 指令微调:使用精选的人类回答来微调预训练语言模型以应对各种查询。
- 奖励模型微调:使用一个包含人类对同一查询的多个答案打分的数据集来训练一个独立的奖励模型。
- 基于人类反馈的强化学习(RLHF)训练:利用近端策略优化 (PPO)算法,根据奖励模型的奖励反馈进一步微调 SFT 模型。