LLM - 3.指令理解阶段(核心) - 强化学习

监督微调的局限
- 高质量回复标注需耗费高昂人力成本
- 交叉熵损失函数要求输出与答案逐字匹配,既无法适应语言的表达多样性,也难以解决输出对输入微小变动的敏感性
LLM-RL 发展方向
基于人类反馈的强化学习 (RLHF)
通过奖励模型对生成文本进行整体质量评估,使模型自主探索更优的回复。
通过生成-反馈的闭环机制持续优化,侧重人类价值对齐。
面向深度推理的强化学习框架
将复杂问题分解为长思维链(Chain-of-Thought)的决策序列,通过答案校验引导模型进行多步推理
自主探索最优推理路径,专注复杂问题求解。
1 强化学习概述
核心:智能体与环境交互的问题,其目标是使智能体在复杂且不确定的环境中最大化奖励。
策略是智能体的动作模型,决定了智能体的动作。
基于价值的智能体显式地学习价值函数 Vπ(s) 或 Qπ(s,a),隐式推导策略,典型算法如 Q-Learning。
价值函数的值是对未来奖励的预测,可以用它来评估状态的好坏。
基于策略的智能体则直接学习策略函数 πθ (a|s),价值函数隐式地表达在策略函数中,典型算法如 REINFORCE。
演员**–**评论员智能体(Actor-critic Agent)则是把基于价值的智能体和基于策略的智能体结合起来,既学习策略函数又学习价值函数,通过两者的交互得到最佳的动作,典型算法如 PPO。
强化学习优势
- 减少人工规则设计,让算法自主发现最优路径
- 算法应通过计算规模扩展而非人工知识注入来提升能力
- 专注构建通用长期优化架构的前瞻性
2. 策略梯度方法
思路:将策略本身参数化(例如用神经网络表示),直接通过梯度上升优化策略参数,让智能体更倾向于选择能带来高回报的动作。
2.1 策略梯度
直接优化策略函数 π(a|s; θ),以最大化预期的回报(累计奖励):

使用梯度上升法优化参数 θ,计算期望回报的梯度为:

引入基线降低策略梯度方法中回报 Rt 的方差
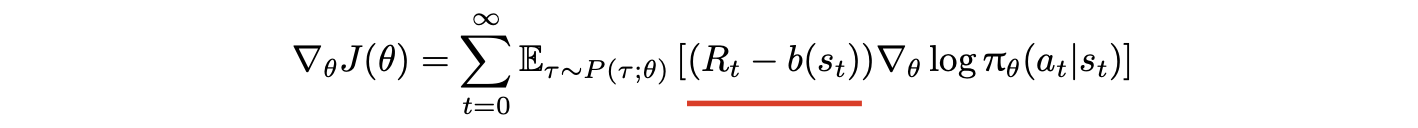
常用的基线选择:状态价值函数 V(st)
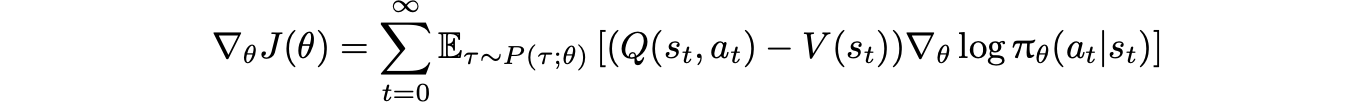
优势函数:衡量动作 at 相对于状态 st 的预期回报提升。
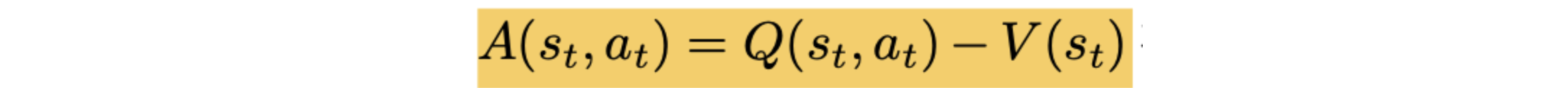
2.2 REINFORCE 算法
核心:通过蒙特卡洛采样方法直接估计策略梯度,利用轨迹的完整回报来更新策略参数 θ,从而最大化期望累积奖励。

引入 状态相关的基线 降低方差
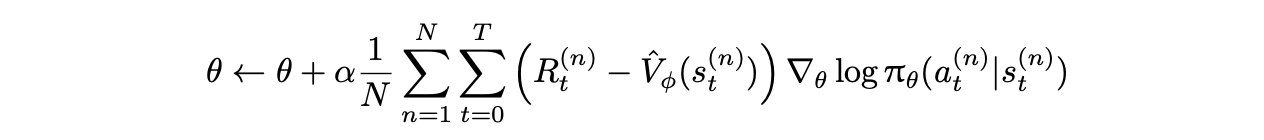
缺点:
- 依赖完整轨迹采样的蒙特卡洛特性导致梯度估计方差过高,训练过程不稳定。
- 必须等待整条轨迹结束后才能更新策略参数,在长周期任务或持续性环境中会大幅降低学习效率。
- 每次策略更新后必须重新采样轨迹数据,样本利用率低下。
- 适用于小规模离散动作空间场景。
2.3 广义优势估计
时序差分方法(TD):基于动态规划的思想,通过引入 Bootstrapping 机制,即利用当前的价值估计来更新自身,而不必等待完整的轨迹结束。

采样 k 步奖励:
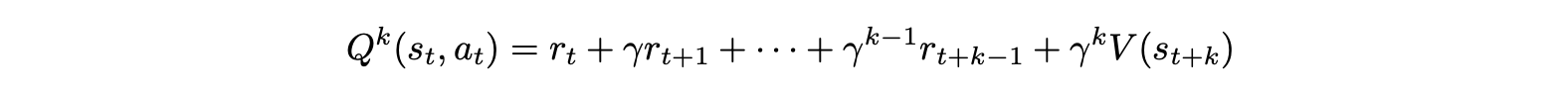
广义优势估计(GAE):优势函数定义为 k 步优势的指数平均:
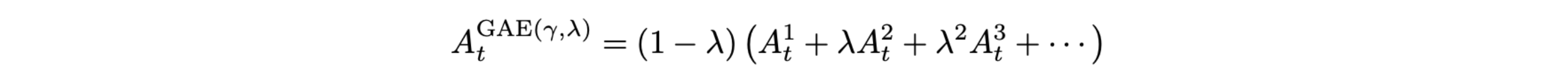
引入 TD 误差:
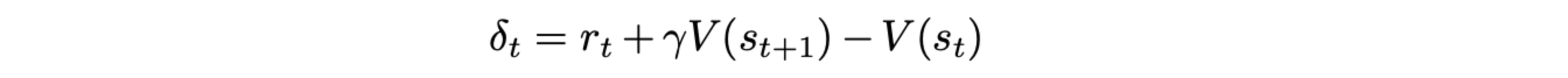
将 k步优势的计算转化为对每一步的 TD 误差的加权求和,从而降低了计算复杂度。将上述结果代入广义优势估计的公式:

2.4 近端策略优化算法 (PPO)
重要性采样
假设我们希望计算期望 Ex∼P(x)[f(x)],但采样数据来自另一个分布 Q(x),可以通过设置采样数据的权重来修正结果:
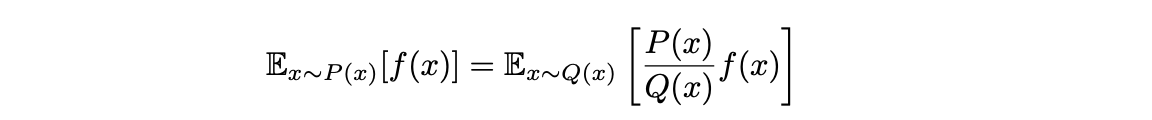
两个分布的差异不能过大,否则会导致以下问题:
- 高方差:当分布差异较大时,权重 P (x)/Q(x) 可能出现极端值,导致估计的期望值方差增大。
- 偏差:为了解决高方差问题,通常需要对权重进行裁剪或限制,这可能引入偏差。
引入剪切机制,通过将权重限制在特定范围内来避免优化不稳定
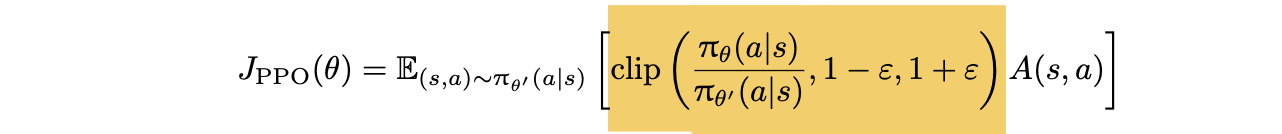
算法流程

2.5 RLOO(REINFORCE Leave-One-Out)
通过利用多个在线样本构建更有效的基线来降低方差,从而提升算法性能。
改进基线的构建方式
REINFORCE 通常使用简单的移动平均基线,这种基线在处理复杂环境和多样本情况时存在一定局限性。
RLOO 利用每次采样得到的多个样本之间的关系,为每个样本单独构建基线。RLOO 构建的基线为除 y(i) 之外的其他k−1 个样本奖励的平均值。
RLOO 的策略梯度估计公式为

算法步骤

与 REINFORCE 算法对比
方差降低、利用了多个样本之间的关系、计算量增大。
2.6 GRPO
Group Relative Policy Optimization(GRPO)旨在解决传统 PPO 在计算资源和训练稳定性方面的问题。它通过组奖励机制来估计基线。
GRPO 从旧策略中抽取多个输出(形成组),利用组内奖励信息计算优势值,以此优化策略。减少了训练资源的消耗,在提升计算效率的同时,增强了训练过程的稳定性。
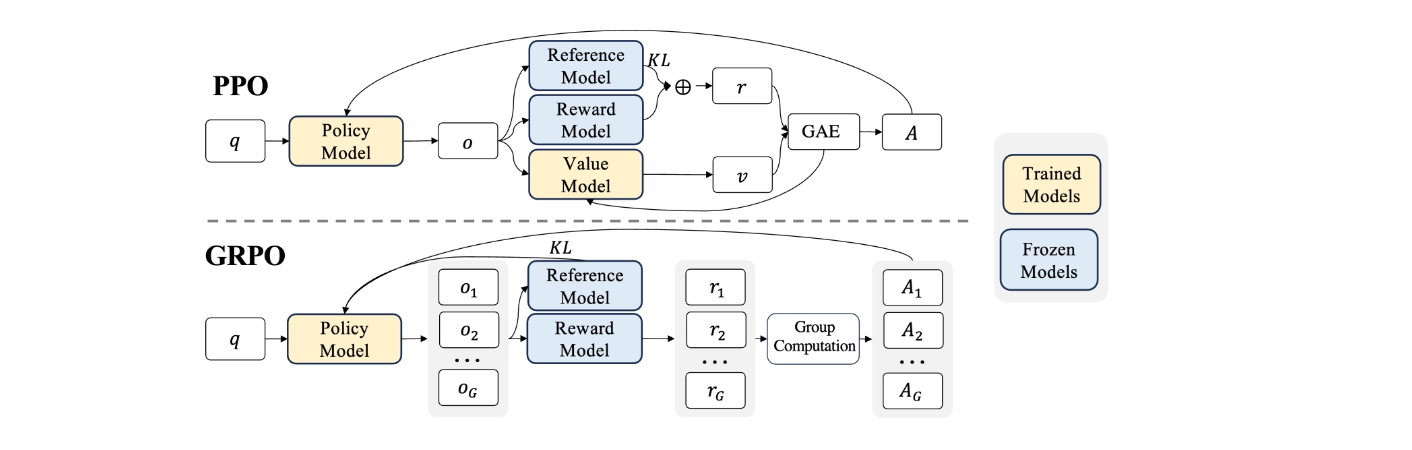
Reference Model: 旧策略的副本,用于计算新策略与旧策略之间的 KL 散度
优化目标函数的设计
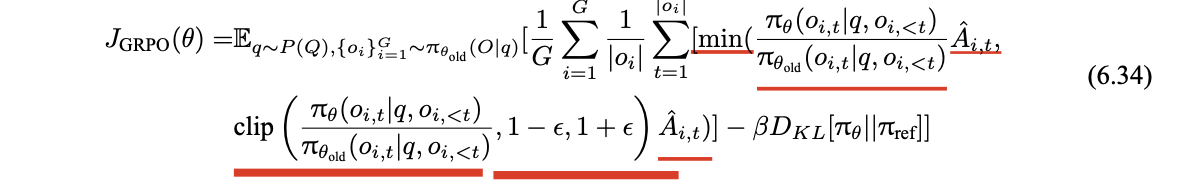
Ai,t 是基于组内奖励计算得到的优势值,它衡量了在时间步 t 采取动作 oi,t 相对于平均水平的优势程度。
DKL[πθ ||πref] 用于约束当前策略 πθ 和参考策略 πref 之间的差异,确保策略不会偏离参考策略太远。
算法步骤
- 初始化策略参数:随机初始化当前策略模型 πθ 的参数 θ以及旧策略模型 πθold 的参数。
- 抽取组样本:计算优势值。
- 更新策略参数:通过优化目标函数 JGRPO(θ) ,计算梯度并更新当前策略模型 πθ 的参数 θ。通常使用随机梯度下降(SGD)或其变种算法来进行参数更新。
- 更新旧策略:将更新后的当前策略 πθ 的参数复制给旧策略模型 πθold ,为下一轮迭代做准备。
- 重复迭代重复步骤 2 - 5,直到达到预设的训练轮数、策略收敛或满足其他停止条件。
与 PPO 的对比
计算负担小、通过分组计算奖励,基线估计效率高、方差较高更稳定。
优势:计算资源友好、稳定、应用效果好。
3. 推理模型的强化学习
推理模型目标:优化推理能力(效率/准确性)
3.1 DeepSeek - R1
1. DeepSeek-R1-Zero:基于基座模型的强化学习
强化学习算法
采用 GRPO 算法进行强化学习,通过从一组得分估计基线。
奖励建模
采用基于规则的奖励系统,包含两种奖励类型:
- 准确性奖励:用于评估模型响应的正确性。
- 格式奖励:促使模型将思考过程置于 ‘’ 和 ‘’ 标签之间,确保推理过程清晰呈现。
训练模板
推理过程和答案分别包含在 和 标签内
优势
- 性能: pass@1 分数从初始的 15.6% 显著提升至 71.0%
- 自我进化过程:模型的思考时间和生成回答的长度不断增加
- 顿悟时刻:凸显了强化学习在激发模型智能方面的潜力
存在问题:可读性差、语言混合等。
DeepSeek-R1-Zero 首次验证了大语言模型的推理能力可通过纯强化学习激发,无需监督微调作为前期步骤。
2. DeepSeek-R1:冷启动强化学习
冷启动
为解决训练初期不稳定问题,DeepSeek-R1 构建并收集少量长思维链数据对 DeepSeek-V3-Base 模型进行微调,作为初始 RL 模型。
优势:改善了输出的可读性;融入人类先验知识,提升了模型的性能潜力。
面向推理的强化学习
在冷启动微调后,采用与 DeepSeek-R1-Zero 相同的大规模强化学习训练过程,聚焦于推理密集型任务。
针对训练中发现的 CoT 语言混合问题,引入语言一致性奖励,根据 CoT 中目标语言单词的比例计算。
拒绝采样和监督微调
当面向推理的 RL 训练接近收敛时,利用此时的检查点收集用于后续轮次的监督微调数据。
- 推理数据:通过拒绝采样生成推理轨迹,扩展数据集。
- 非推理数据:对于写作、事实性问答、自我认知和翻译等非推理任务,复用 DeepSeek-V3 的 pipeline 和部分 SFT 数据集。
全场景强化学习
进行二次强化学习训练,旨在提升模型的有用性、无害性并进一步优化推理能力。
DeepSeek-R1 在多个推理任务中表现出色。
3. 蒸馏:赋予小模型推理能力
使用在 DeepSeek-R1 训练过程中收集的 800k 样本,对 Qwen 和 Llama 等开源模型进行直接微调。
这种简单的蒸馏方法能显著提升小模型的推理能力。
3.2 Kimi k1.5
有出色的推理性能、创新的技术架构通过长上下文扩展和改进的策略优化、高效的数据处理与训练。
1. 数据集
强化学习提示数据集构建:3 个关键属性(多样覆盖、平衡难度、准确评估能力)
预训练数据集的构建与处理: 为保证数据高质量,采用多种清洗方法
微调数据集的构建: 文本示例 + 文本- 视觉示例
多模态数据: 标题数据、图像-文本交错数据、OCR 数据
2. 算法创新
长上下文扩展
采用部分回放技术,通过重用之前轨迹的大部分来采样新轨迹,减少计算开销。
即,部分展开系统将长响应分解为多个段,在多个迭代中逐步处理,加快训练速度。
Long2short 的上下文压缩策略
模型合并:简单平均 长上下文模型 和 短上下文模型 的权重,获得无需训练的新模型,有助于保持泛化能力。
最短拒绝采样:对同一问题多次采样,选择最短的正确响应。
DPO:形成成对偏好数据用于 DPO 训练。
长到短强化学习:应用长度惩罚方案惩罚超长响应。
改进的策略优化
采样策略:采用课程采样和优先级采样策略。
课程采样从简单任务开始训练,逐渐过渡到困难任务,利用数据的难度标签提高训练效率;
优先级采样跟踪每个问题的成功率,按比例采样问题,使模型专注于薄弱领域。
长度惩罚:针对 RL 训练期间模型响应长度增加的问题,引入长度奖励限制 token 长度增长。
3. 训练架构及工程框架
三个阶段
视觉语言预训练阶段
最初仅在语言数据上训练,随后逐步引入交错式视觉- 语言数据,获取多模态能力。
视觉语言冷却阶段
使用高质量的语言和视觉语言数据集训练,加入合成数据可提高在数学推理、基于知识的任务和代码生成方面的性能。
长上下文激活阶段
使用上采样的长上下文冷却数据训练,处理扩展序列任务。
大规模 RL 训练系统:
通过迭代同步方法操作,每次迭代包括展开阶段和训练阶段。
- 展开阶段:生成响应序列并存储在重放缓冲区
- 训练阶段:访问经验更新模型权重
混合部署框架
利用 Kubernetes Sidecar 容器共享 GPU 资源,实现训练和推理任务的并行。
4. 基于人类反馈的强化学习
基于人类反馈目标:对齐人类偏好(自然性/安全性)
4.1 基于人类反馈的强化学习流程
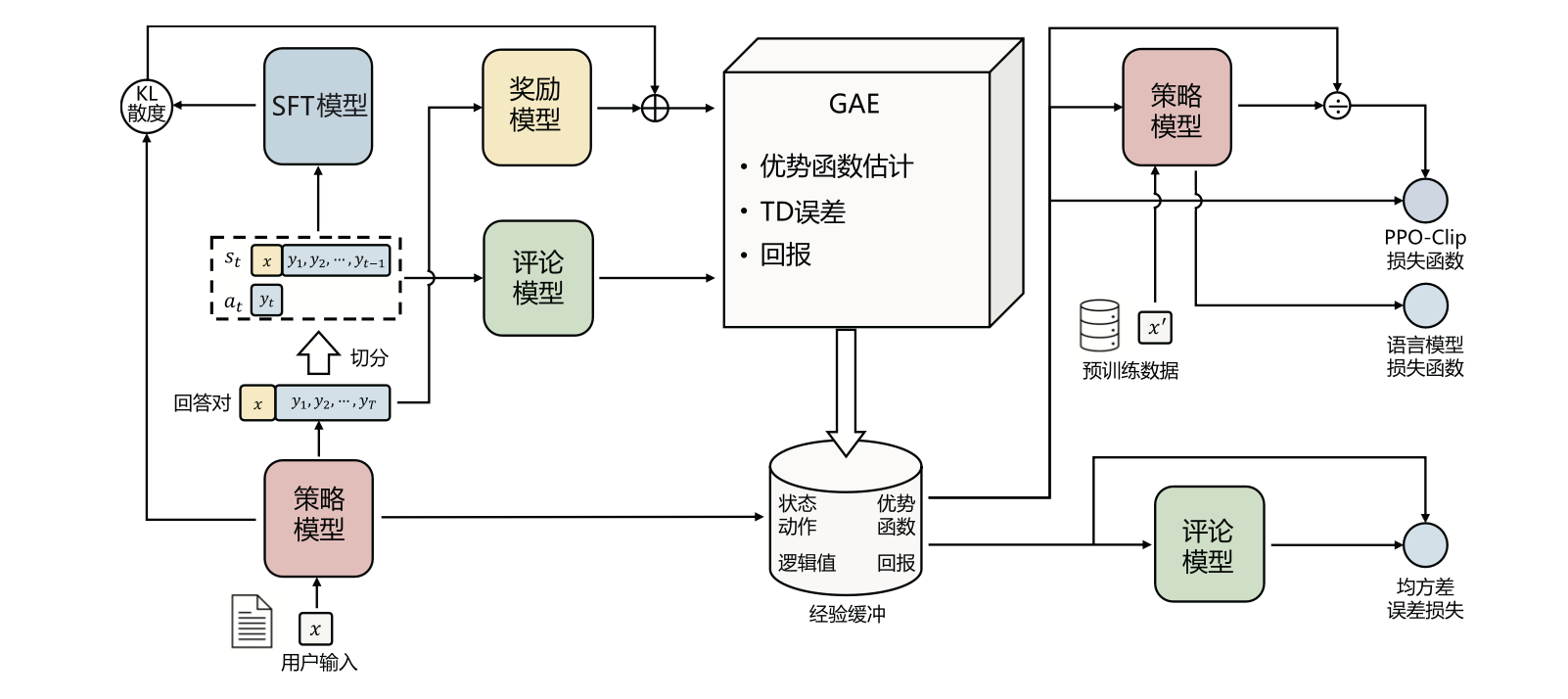
- 环境采样:策略模型基于给定输入生成一系列的回复,奖励模型则对这些回复进行打分获得奖励。
- 优势估计:利用评论模型预测生成回复的未来累积奖励,并借助广义优势估计(GAE)算法估计优势函数,有助于准确地评估每次行动的好处。
- 优化调整:使用优势函数优化和调整策略模型,同时利用参考模型确保更新的策略不会
4.2 奖励模型
1. 数据收集
3H 原则:帮助性 (Helpfulness)、 真实性 (Honesty) 、无害性 (Harmless)
2. 模型训练
奖励模型通常基于 Transformer 结构的预训练语言模型,为文本序列中的最后一个标记分配一个标量奖励值,样本质量越好,奖励值越大。
通常需要使用由相同输入生成的两个不同输出之间的配对比较数据集。
模仿学习
目标:学习从输入到输出的映射,以便能够在类似的输入上生成类似的输出。
引入 强化学习策略与初始监督模型之间的KL散度 到奖励函数中
目的:促进了在策略空间中的探索;维持了学习过程的稳定性和一致性。
3. 开源数据
Summarize from Feedback 数据集、HH-RLHF 数据集、Stanford Human Preferences(SHP)数据集…
5. 实践:verl
字节 + 港大:解决了传统 RL/RLHF 系统灵活性和效率不足的问题
创新性采用混合编程模型,将控制流和计算流解耦。
流程:训练脚本与参数配置、基于 Ray 分布式计算框架的训练流程、奖励函数配置。