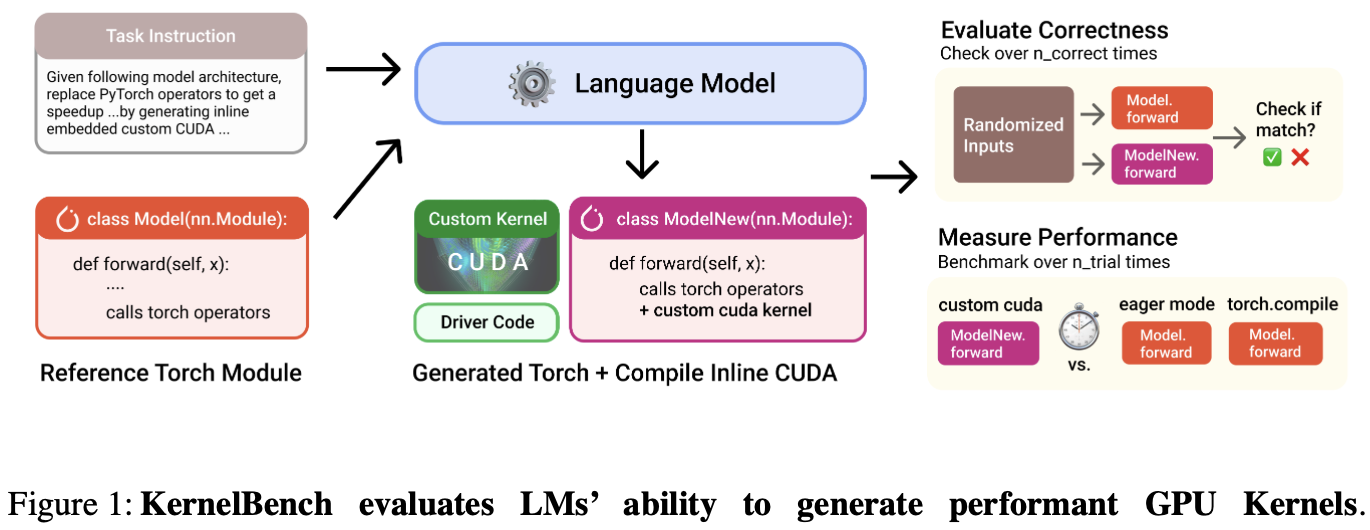
KernelBench 是一个评估 LLMs 在生成高性能 GPU 内核代码上能力的基准测试框架。论文引入了新评估指标 fast_p:衡量生成的 正确、且速度提升超过阈值p 的内核的比例。
Introduction
背景:每个硬件都有不同的规格和指令集,跨平台移植算法是痛点。
论文核心探讨:LM 可以帮助编写正确和优化的内核吗?
KernelBench 的任务:让 LMs 基于给定的 PyTorch 目标模型架构,生成优化的 CUDA 内核;并进行自动评估。
环境要求
自动化 AI 工程师的工作流程。
支持多种 AI 算法、编程语言和硬件平台。
轻松评估 LM 代的性能和功能正确性,并从生成的内核中分析信息。
测试级别
Individual operations::如 AI 运算符、包括矩阵乘法、卷积和损失。
Sequence of operations:评估模型融合多个算子的能力。
端到端架构:Github 上流行 AI 存储库中的架构。
工作流程