「论文阅读」RAG 文献调研
评估
RagChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Introduction
评估 RAG 系统的难点
- 模块化复杂
- 指标限制
- 检索器:传统指标(如 recall@k 和 MRR)依于 带注释的分块 和 严格的分块方式,忽视了知识库的完整语义范围
- 生成器:典型度量(如,基于 n-gram 的方法(如BLEU 和 ROUGE)、基于嵌入的方法(例如,BERTScore)和基于 LLM 的方法等)等可处理简单回答,但无法在较长的响应中检测到更精细的区别。
- 指标可靠性
对比其他(RAGAS、TruLens、ARES、RGB、RECALL、NoMIRAC),RagChecker 能 从人类角度评估 RAG 系统质量和可靠性方面的有效性,对错误来源做分析。
Related Work
现有评估可分为两种方法:仅评估 generators 的基本功能 和 评估 RAG 系统的端到端性能。
- generators:RGB、RECALL、NoMIRACL、Wu、FaaF…
- RAG 系统:TruLens、RAGAS、ARES、CRUD-RAG…
- 数据集:Liu、MEDRAG(医疗RAG基准)、MultiHop-RAG、CDQA…
RagChecker 框架
1 输入:元组 <q,D,gt>
- q:查询, 即 RAG 系统的输入问题。
- D:文档,提供可能的上下文,并被处理成同样数量 tokens 的块
- gt: ground-truth answer,输入问题的完整正确答案。
2 具有参考信息的细粒度评估
RAG 系统生成的响应可能是正确 和错误声明的混合,同时也缺少一些claims
[!NOTE]
RAG系统通过检索外部知识生成回答,其输出可能包含:
✅ 正确主张(与in-ground-truth一致);
❌ 错误主张(与事实矛盾);
❓ 缺失主张(漏掉了本应包含的in-ground-truth信息)。
例如,若问题涉及“COVID-19的传播途径”,而标准答案(in-ground-truth)包含“飞沫传播”和“接触传播”,但RAG仅生成“飞沫传播”,则缺失了“接触传播”这一in-ground-truth claim。
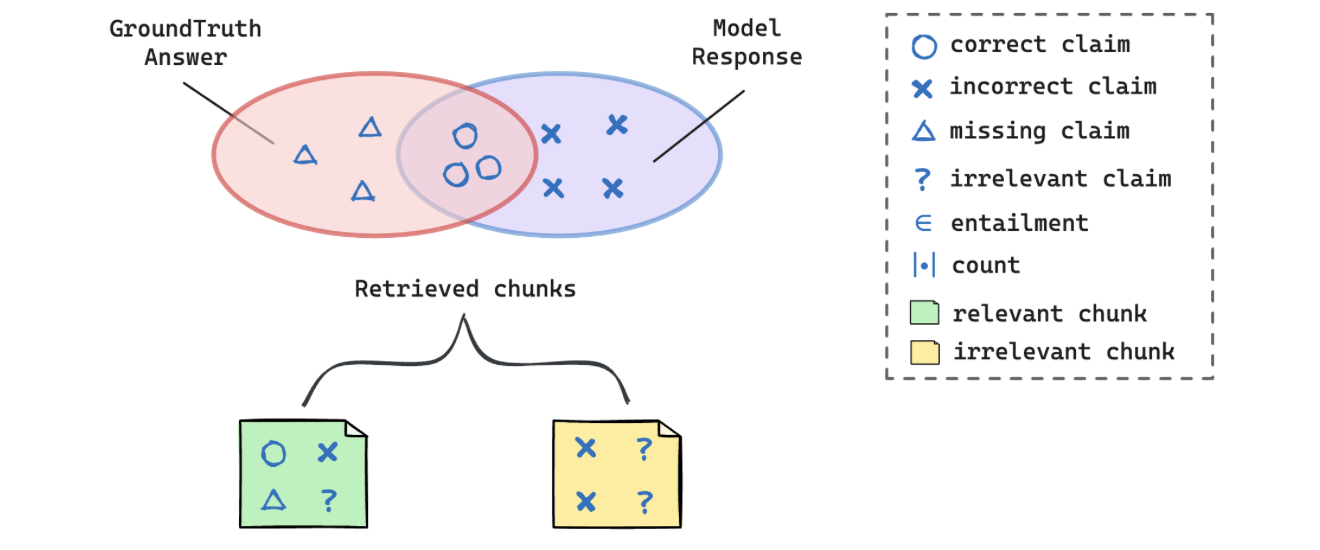
- 引入两个组件:
- 将给定文本 T 分解为一组声明的提取器 {ci}
- 一个检查器,用于确定给定的声明 c 是否包含在参考文本 Ref 中
3 指标
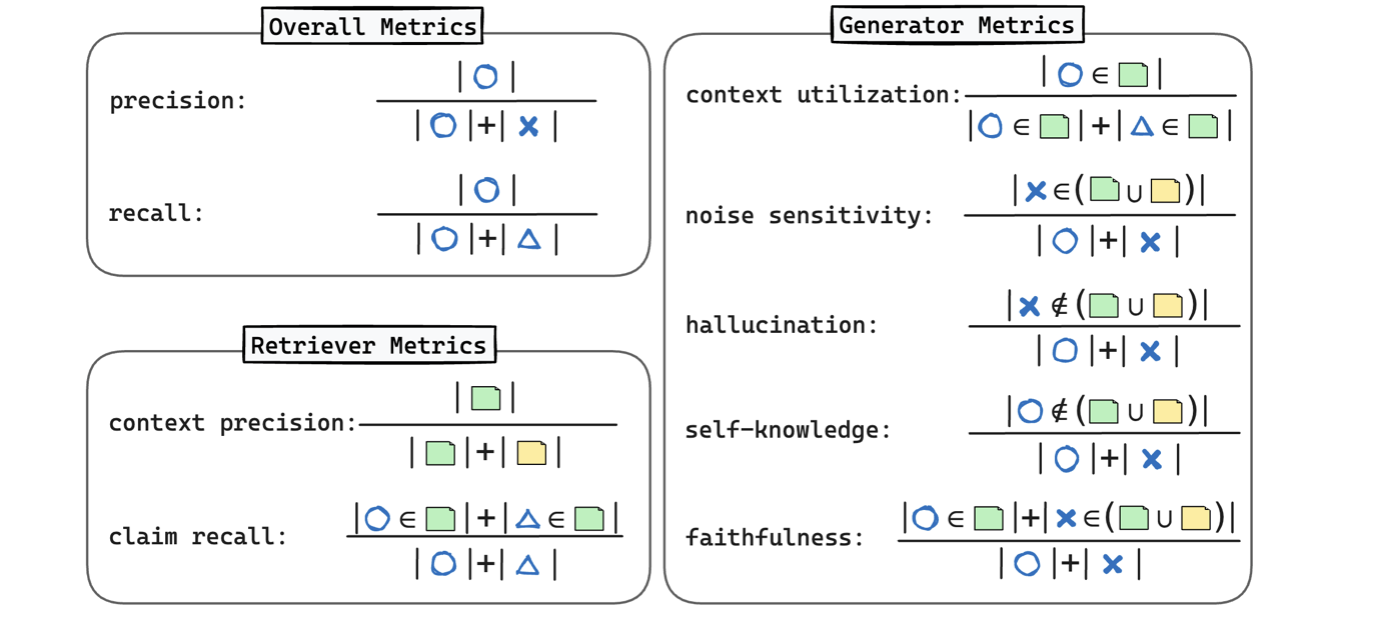
- 整体指标
- Precision:响应中正确claim的比例。
- Recall:覆盖ground-truth中正确claim的比例。
- F1 Score:综合精度与召回率的调和平均。
- 检索器诊断指标
- Claim Recall (CR):检索结果覆盖ground-truth claim的比例。
- Context Precision (CP):检索chunk中包含相关claim的比例(按chunk级计算)。
- 生成器诊断指标
- Context Utilization (CU):生成内容中来自检索上下文的ground-truth claim比例。
- Relevant Noise Sensitivity:生成器对相关噪声(检索结果中的错误claim)的敏感度。
- Irrelevant Noise Sensitivity:生成器对无关噪声(非检索结果中的错误claim)的敏感度。
- Hallucination:生成内容中完全未出现在检索结果中的错误claim比例。
- Self-knowledge:生成器依赖自身知识而非检索结果的claim比例。
- Faithfulness:生成内容忠实于检索上下文的比例。
实验设计与结果
1 基准数据集
- 来源:整合公开数据集(RobustQA、ClapNQ、NovelQA等),覆盖10个领域(医学、金融、小说等)。
- 处理:将短答案扩展为长文本,通过GPT-4生成并过滤幻觉内容。
2 评估的RAG系统
- 组合方式:2 种检索器(BM25、E5-Mistral) × 4 种生成器(GPT-4、Mixtral-8x7B、Llama3-8B/70B)
- 配置:检索 top-20 chunks,生成温度设为 0,最大长度 2048 tokens。
3 元评估(Meta-Evaluation)
- 方法:人工标注 280 组响应对,比较不同指标与人类偏好的相关性。
- 结果:
- RAGCHECKER 的Overall F1与人类判断的相关性最高(Pearson 0.619,Spearman 0.609)
- 显著优于传统指标(如BLEU的0.351)和现有框架(如RAGAS的0.483)
4 结论
- 检索器的重要性
- 更强的检索(E5-Mistral)显著提升整体性能(F1从46.3→52.7)。
- Claim Recall 每提升1%,F1 平均提高0.3%。
- 生成器规模效应
- Llama3-70B 在所有指标上优于小模型(如Context Utilization从54.9→63.7)。
- 开源模型(如Llama3)易盲目信任上下文,导致噪声敏感性较高。
- 关键权衡
- 检索质量 vs. 噪声引入:Claim Recall 提升可能导致生成器对噪声更敏感。
- 上下文利用率 vs. 幻觉控制:利用更多检索内容会降低幻觉,但增加噪声干扰。
优化建议与启示
- 检索优化策略
- 块大小与数量:增大块尺寸可提升Claim Recall,但需平衡噪声。
- 重叠率:块重叠对性能影响有限,建议默认值0.2。
- 生成器调优方向
- Prompt设计:明确要求忠实性(如“仅使用上下文信息”)可减少幻觉(下降2.3%)。
- 三重困境:需在上下文利用率、噪声敏感性与幻觉间权衡,优先满足业务需求。
- 未来方向
- 扩展基准至多模态和跨语言场景
- 细化错误分类(如区分“矛盾”与“中性”蕴含结果)
数据集
MEDRAG: Enhancing Retrieval-augmented Generation with Knowledge Graph-Elicited Reasoning for Healthcare Copilot
Introduction
对于医疗来说,最重要和最具挑战性的任务之一是:根据患者的表现提供准确的诊断 ,然后根据诊断提供适当的治疗计划和药物建议。然而,当疾病具有相似的表现时,区分变得困难。
此外,当患者信息不足或诊断不明确时,医疗副驾驶应主动提供精确的后续问题,以增强决策过程。
contributions
- 提供了两个诊断知识图谱:一个专注于慢性疼痛,另一个基于 DDXPlus(一个大规模合成数据集)。这些知识图谱包含丰富的疾病层次结构,以及它们的关键诊断差异。这种综合组织可以提高疾病鉴别和诊断的精确性,从而为各个医疗系统提供更好的决策支持。