PPO 代码实现
1. 论文详读
Proximal Policy Optimization Algorithms
2. Policy Gradient
1. 完整过程
随机初始化 actor 参数 theta
玩 n 次游戏,收集 n 个 trajectory(state、action),算出 reward
用得到的 data 去更新参数 theta


如果 R(τⁿ) 为正,梯度更新会提升该轨迹中所有动作的概率;若为负,则降低概率。
得到新的 actor 后,再去玩新的 n 次游戏
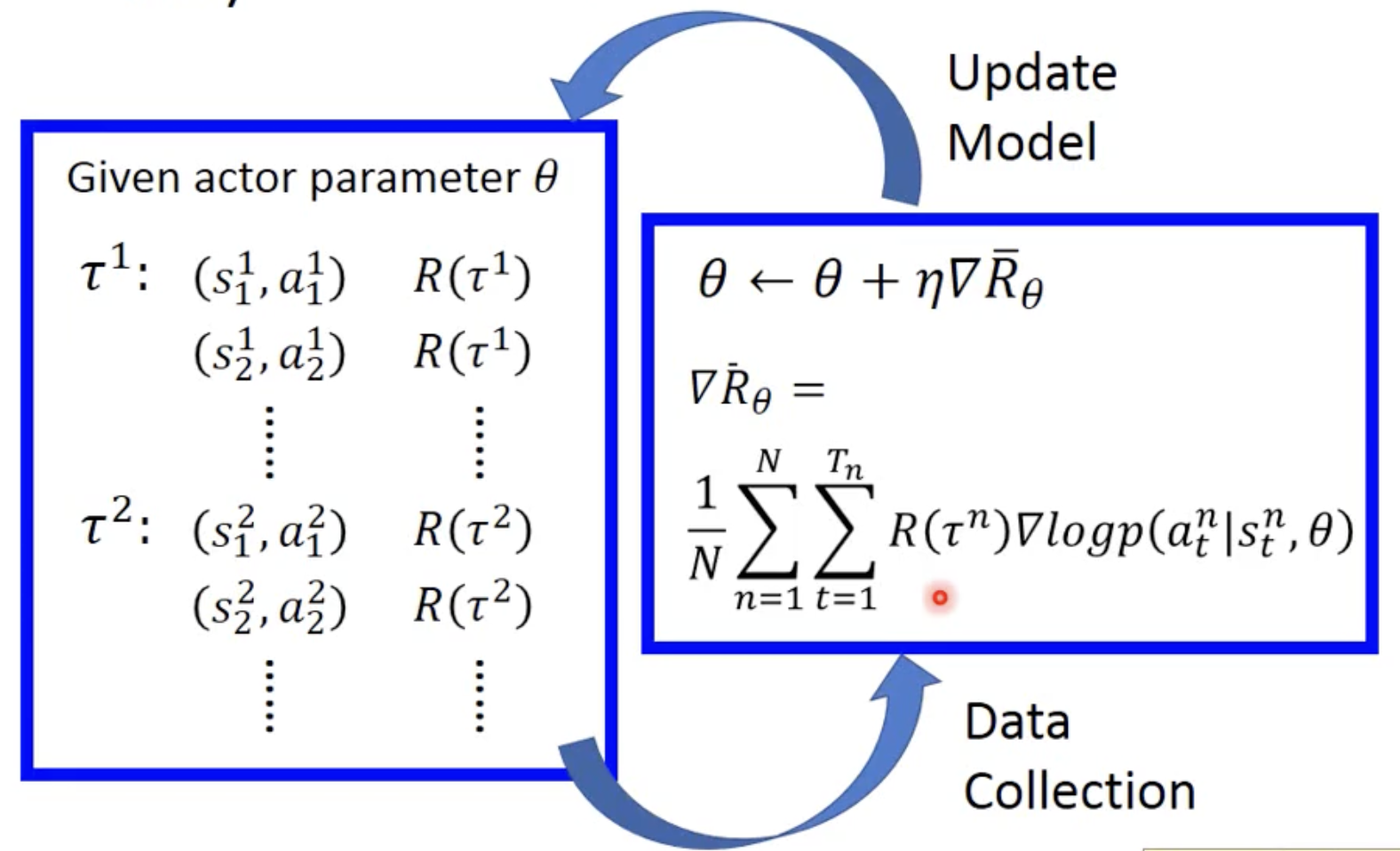
循环往复上述过程
2. 如何更新参数
以分类问题为例:
每个训练数据通过乘以 R,来调整输入数据的权重。
每搜集一次数据,都要 train 一次。