PPO-直观理解
1. 基础概念
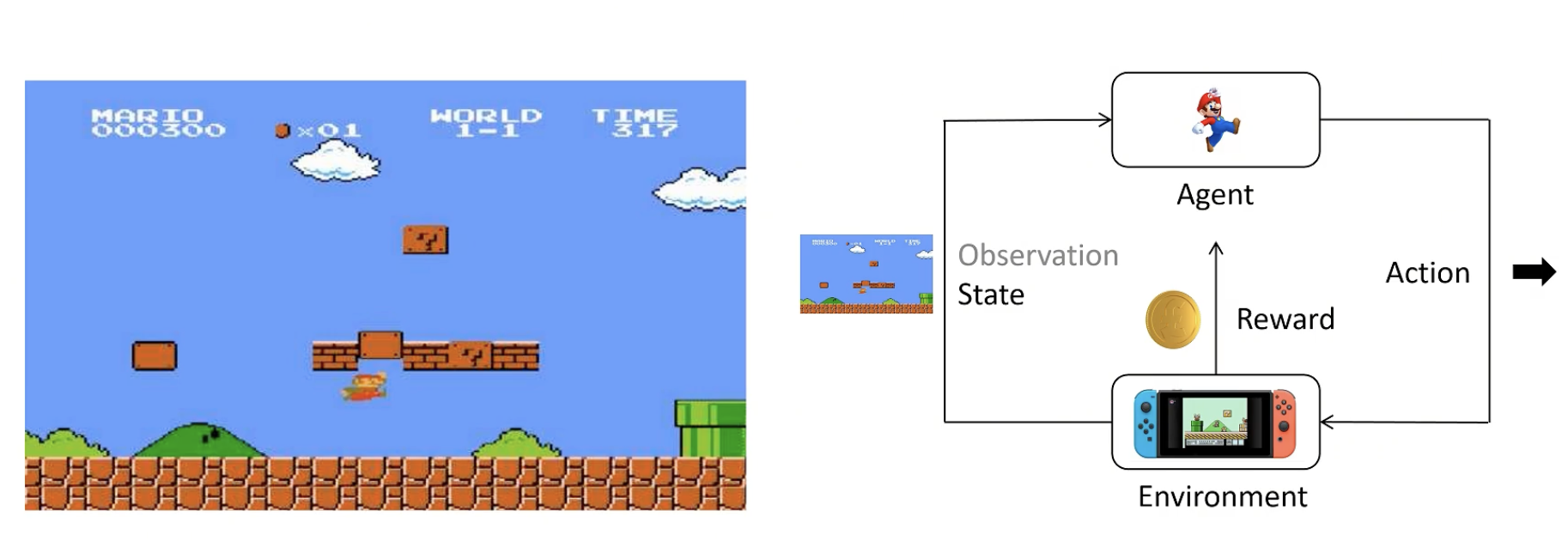
enviroment:看到的画面+看不到的后台画面,不了解细节
agent(智能体):根据策略得到尽可能多的奖励
state:当前状态
observation:state的一部分(有时候agent无法看全)
action:agent做出的动作
reward:agent做出一个动作后环境给予的奖励
action space:可以选择的动作,如上下左右
policy:策略函数,输入state,输出Action的概率分布。一般用π表示。
- 训练时应尝试各种action
- 输出应具有多样性
Trajectory/Episode/Rollout:轨迹,用 t 表示一连串状态和动作的序列。有的状态转移是确定的,也有的是不确定的。
Return:回报,从当前时间点到游戏结束的 Reward 的累积和。
强化学习目标:训练一个Policy神经网络π,在所有状态S下,给出相应的Action,得到Return的期望最大。
2. Policy gradient
目标:求return期望的最大值
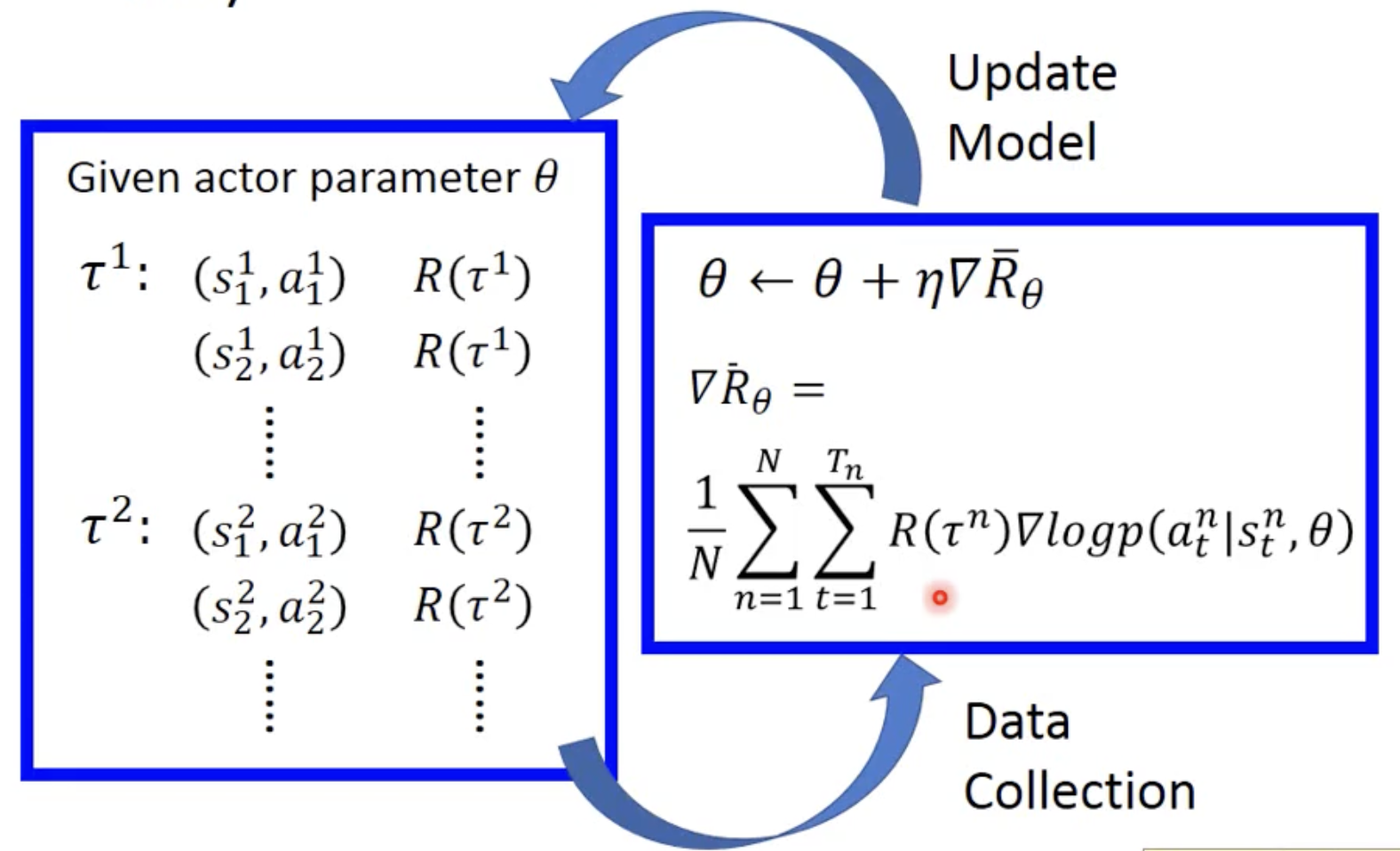
计算过程
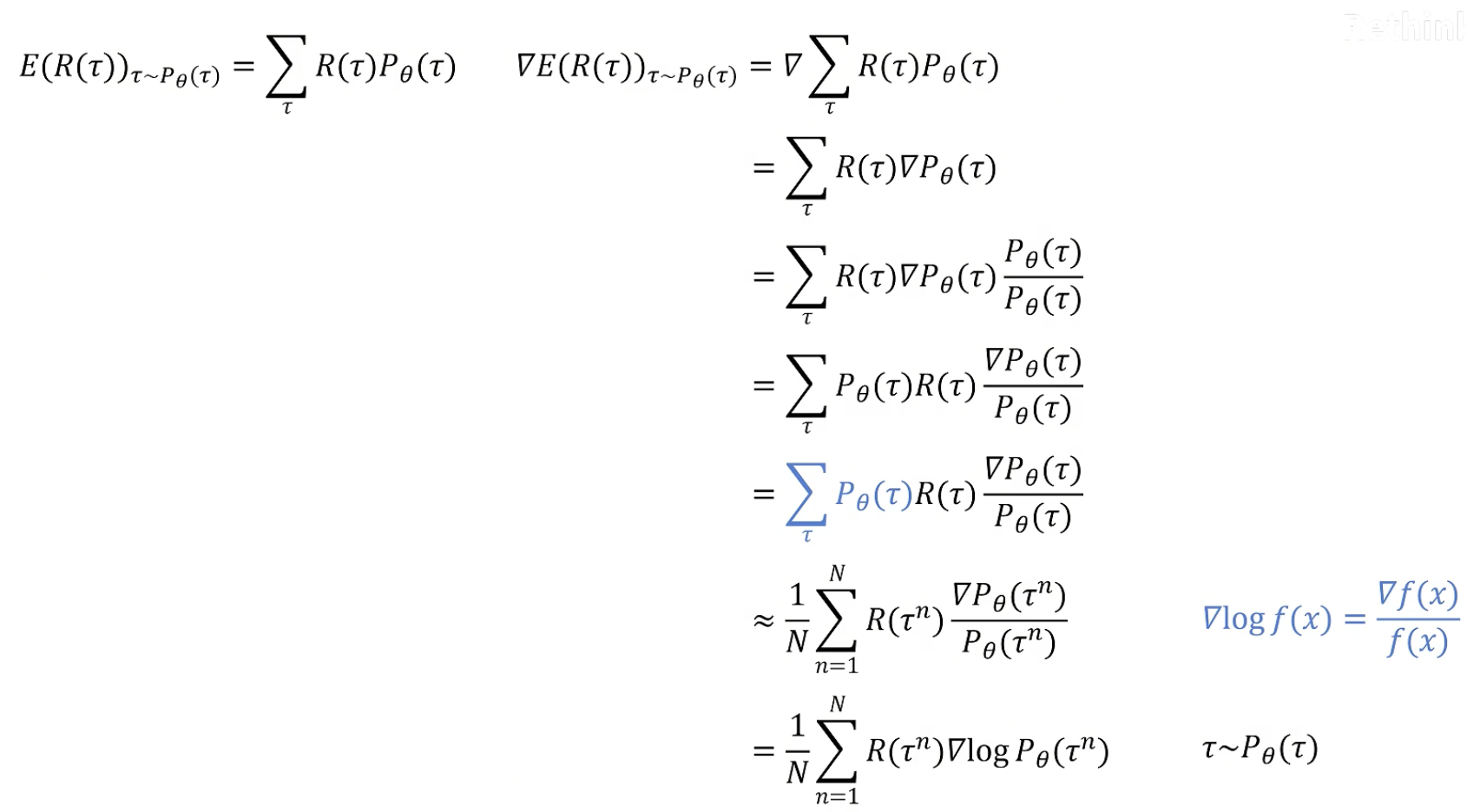
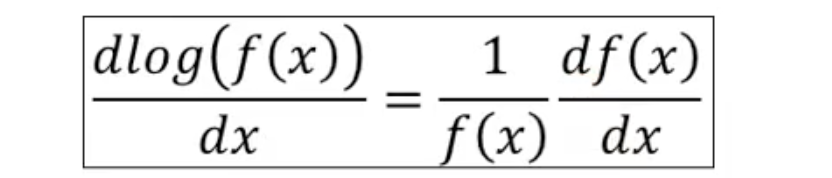
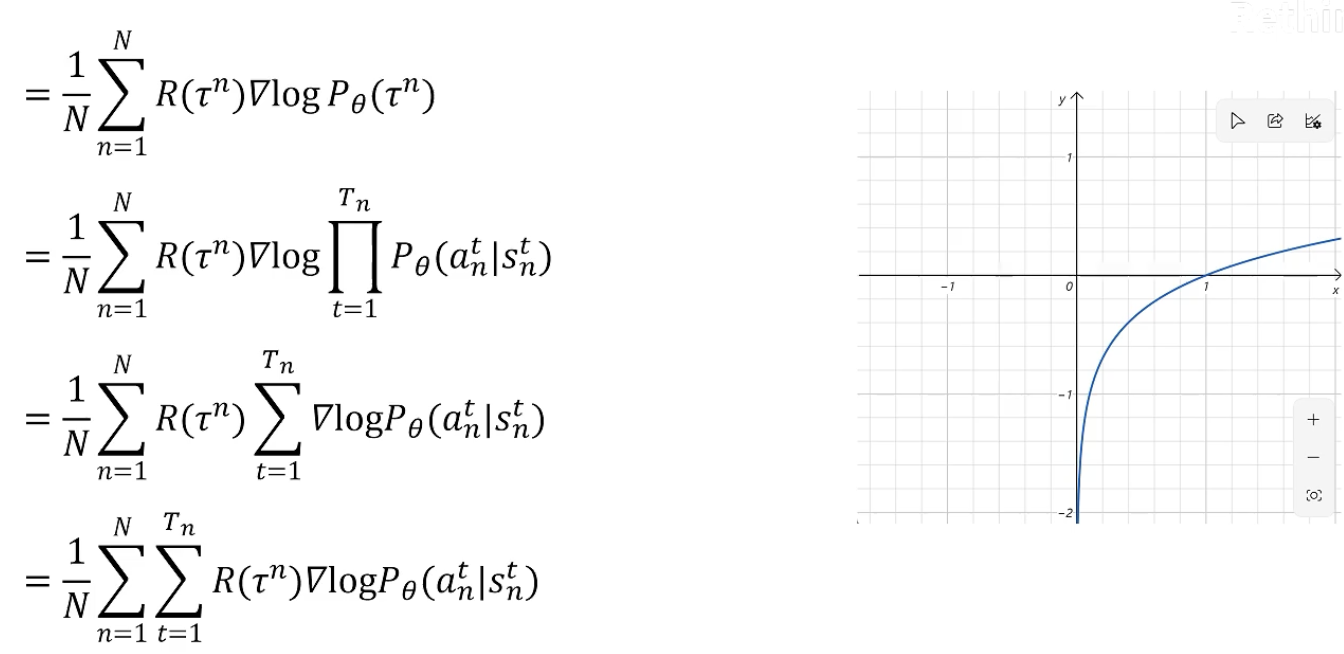
直观理解:
对所有可能的 trajectory 期望最大的梯度。可以用这个梯度乘学习率去更新神经网络里的参数。
若去掉梯度,则表达式的意义:若一个trajectory 得到的 return 大于零,则增大这个trajectory里所有状态下,采取当前action的概率。
训练 policy 神经网络
输入:当前画面
输出:action 的概率
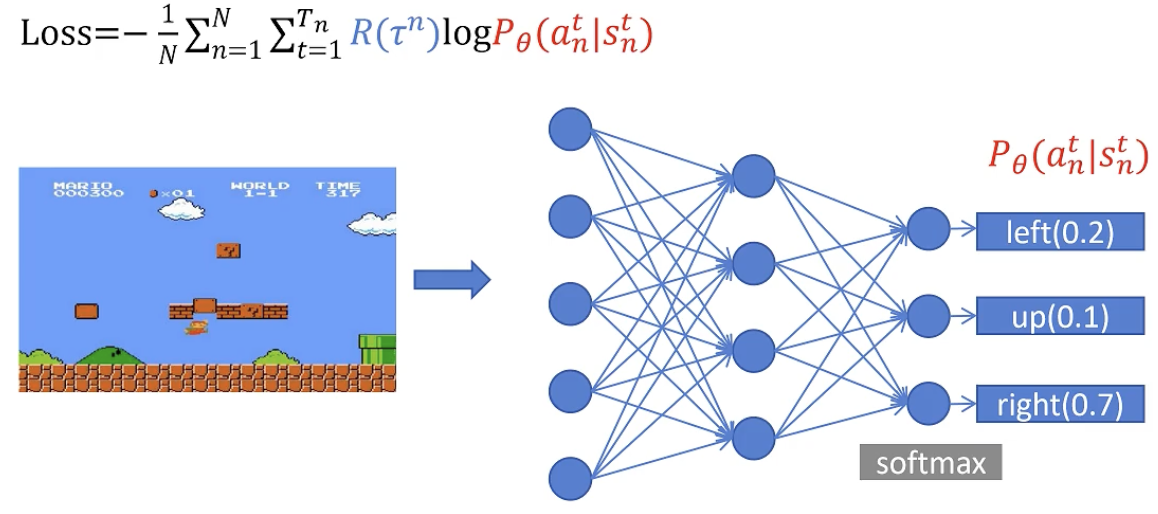
玩n场游戏后,得到n个trajectory的最后的return值
此时可以得到loss里的所有值,可以进行一个batch训练,来更新policy神经网络
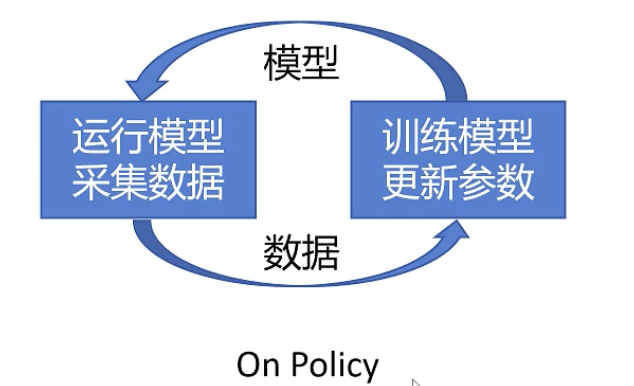
存在问题:大部分时间在采集数据,很慢
完整过程
随机初始化 actor 参数 theta
玩 n 次游戏,收集 n 个 trajectory(state、action),算出 reward
用得到的 data 去更新参数 theta


如果 R(τⁿ) 为正,梯度更新会提升该轨迹中所有动作的概率;若为负,则降低概率。
得到新的 actor 后,再去玩新的 n 次游戏
循环往复上述过程
如何更新参数
以分类问题为例:
每个训练数据通过乘以 R,来调整输入数据的权重。
每搜集一次数据,都要 train 一次。
3. 如何与环境进行交互
强化学习与一般机器学习的区别:
agent 所采取的行为会影响到它未来发生的事情。
例如
- alpha go:输入棋盘局势,输出下一步
- 让机器学会玩游戏:
- Gym: https://gym.openai.com/
- Universe: https://openai.com/blog/universe/
- 自动驾驶
- 对话系统
分类问题的缺点:behavior cloning,机器不知道学到的行为的是好是坏/重点是什么。解决方式:
- 强化学习:自行与环境进行互动,通过观察 reward 得知行为是好是坏。
- 示范学习:expert 示范如何解决任务,机器从示范中学习。
4. Actor-Critic
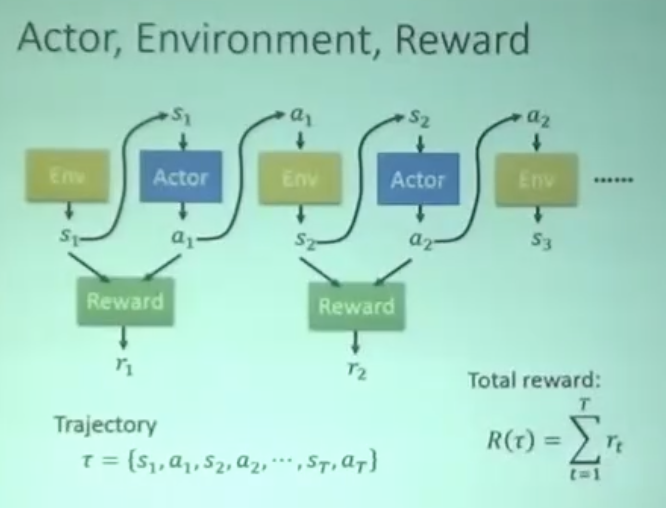
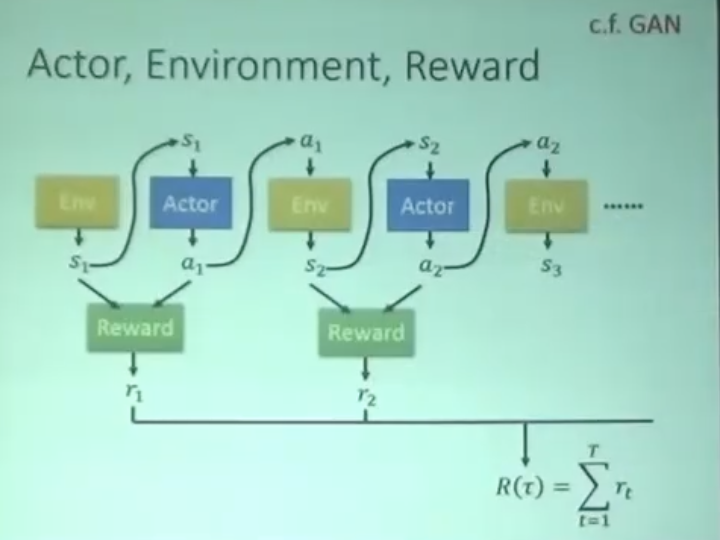
目标:R(t) 越大越好。
1. Actor
actor 本质是神经网络
输入:游戏画面
输出:各动作的概率
2. Critic
critic 本身不能决定任何 action;给它一个 actor ,它可以告诉你这个 actor 有多好。
State value function V(a|s):给它一个 actor,它告诉你接下来一直到游戏结束,可以得到的所有 reward 的期望值是多少。

怎么算 critic?
Monte-Carlo
让 ciric 看玩游戏的过程:看 s 做出 action a 后,一直到 episode 结束,所得到的 rewrd $G_a$。
学习到:我的输出和 $G_a$ 越接近越好。

Temporal-difference approach
V(St) = V(St+1) + rt

3. Actor-Critic
上述算法可改进:
是否增大某动作概率,应该看做了该动作之后,到游戏结束累积的 reward;而不是整个 trajectory 的 reward。
一个动作只能影响它之后的 reward,而无法影响它之前的 reward
某动作可能只影响接下来的几步,且影响逐步衰减。后面的reward更多是被当时的action影响。
修改公式:actor-critic
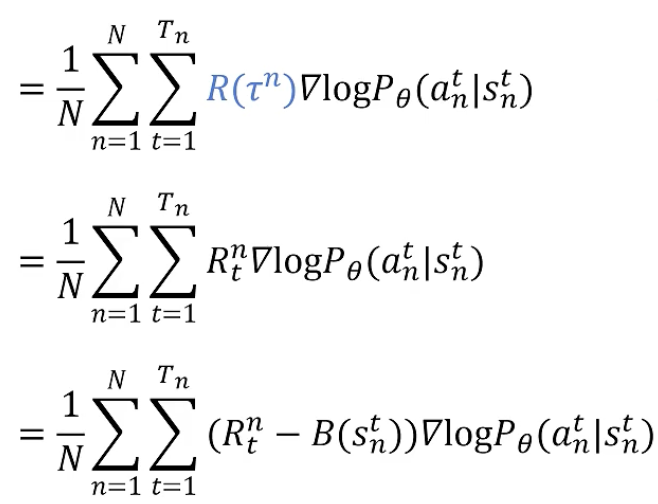
对当前动作之后的折扣累积回报进行求和
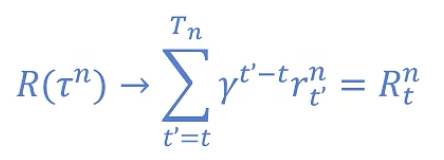
引入 gamma:距离当前越远,影响越小
对所有的动作减去一个baseline,得到的就是该动作相对于其他动作的好坏。避免训练慢。
actor:输出动作的概率分布。
critic:评估状态值函数 V(s) 的网络。估计当前状态的价值,而不是直接评估动作的好坏。
5. 优势函数(Advantage Function)

动作价值函数

优势函数计算公式
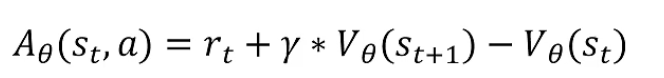
之前需要训练两个神经网络(动作+状态),变成只需要训练一个代表状态价值的函数。
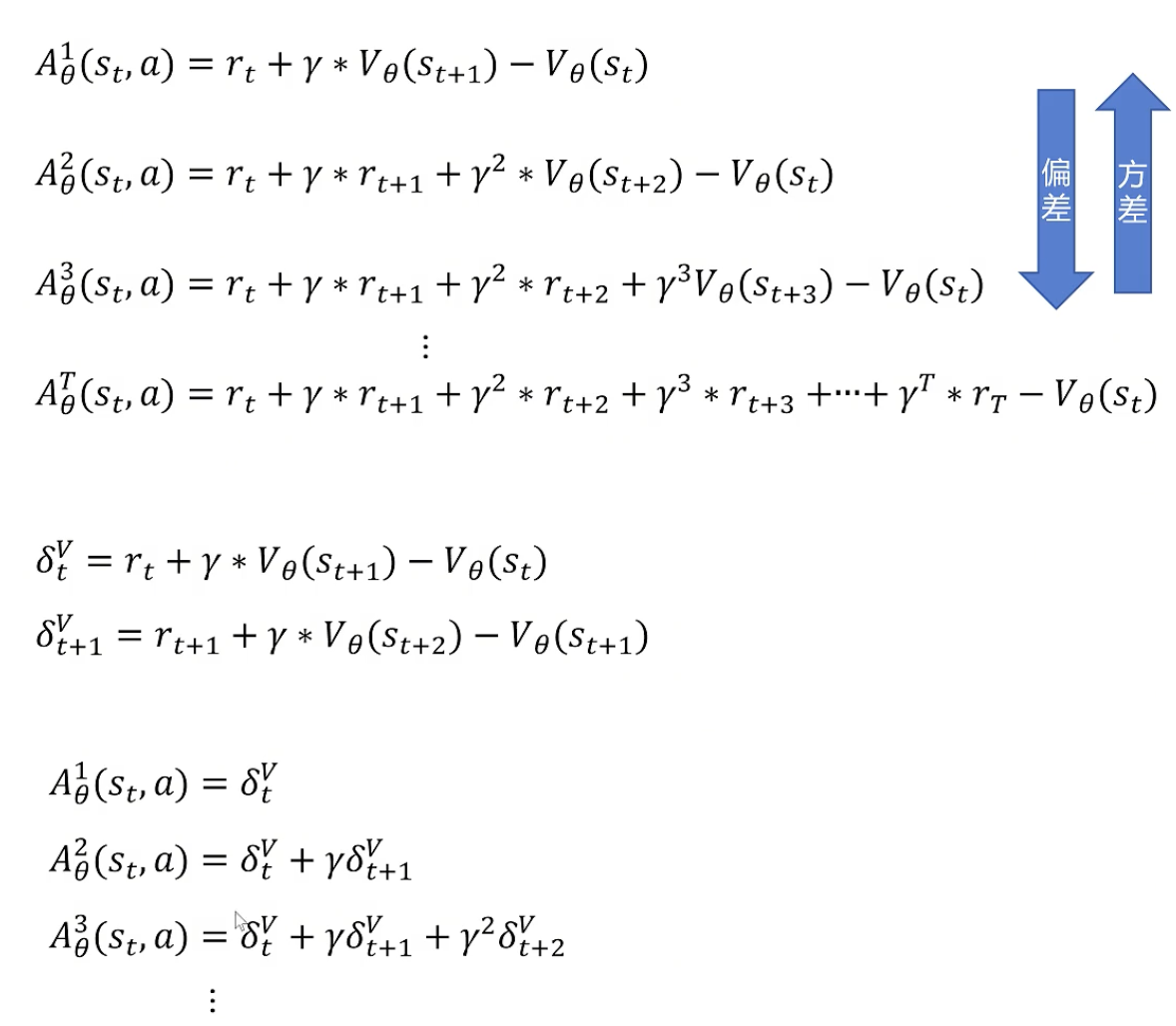
要采样几步?Generalized Advantage Estimation (GAE):全都要
通过一个超参数控制了我们想要的方差-偏差间的平衡。权重随着步数增加而降低。
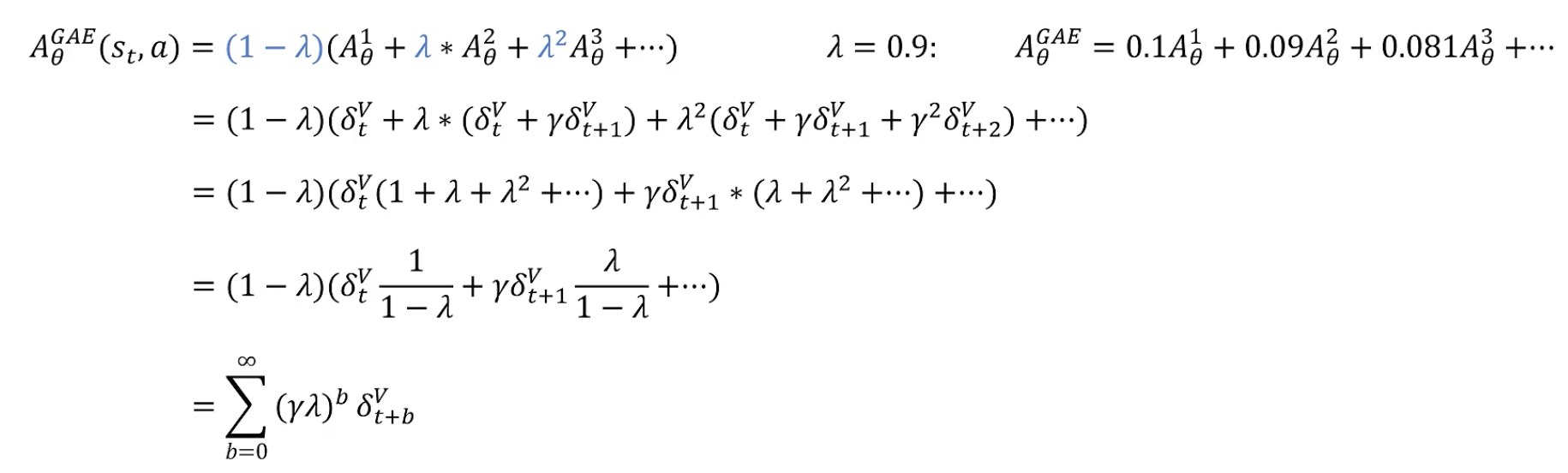
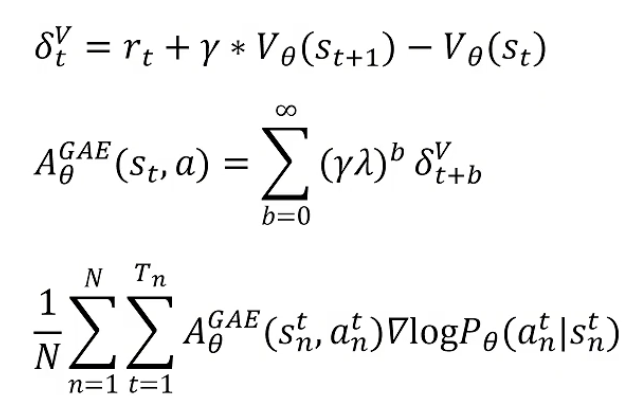
目标:策略梯度优化目标函数值(即第三个式子)越大越好
状态价值函数用神经网络拟合,它可以和策略函数公用网络参数,只是最后一层不同:状态价值函数在最后一层输出一个单一值代表当前价值即可。
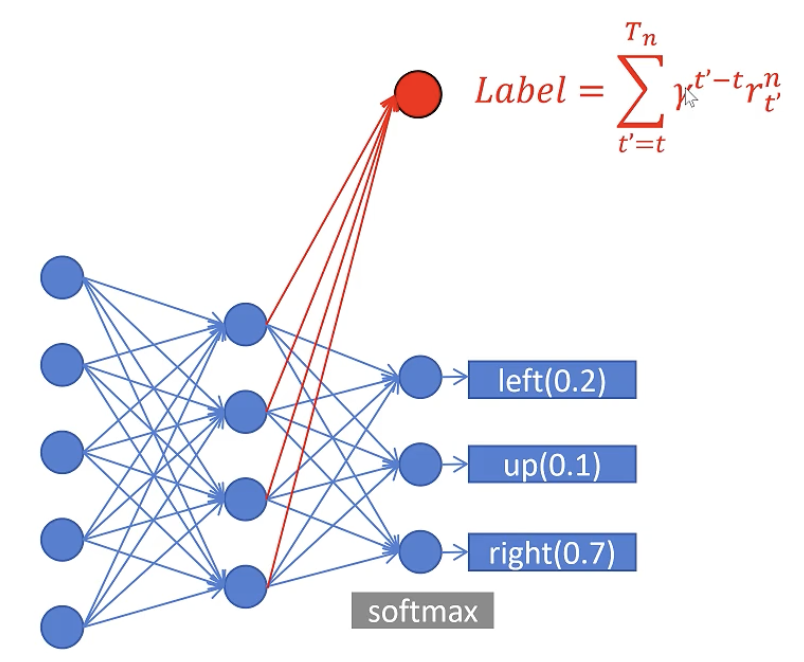
训练价值函数:统计当前步到 trajectory 结束,所有 reward的加减加和 作为label。衰减系数用gamma控制。用价值网络拟合retuen值即可。
6. on-policy与off-policy

动作价值函数Q(s,a):在state s下,做出Action a,期望的回报。
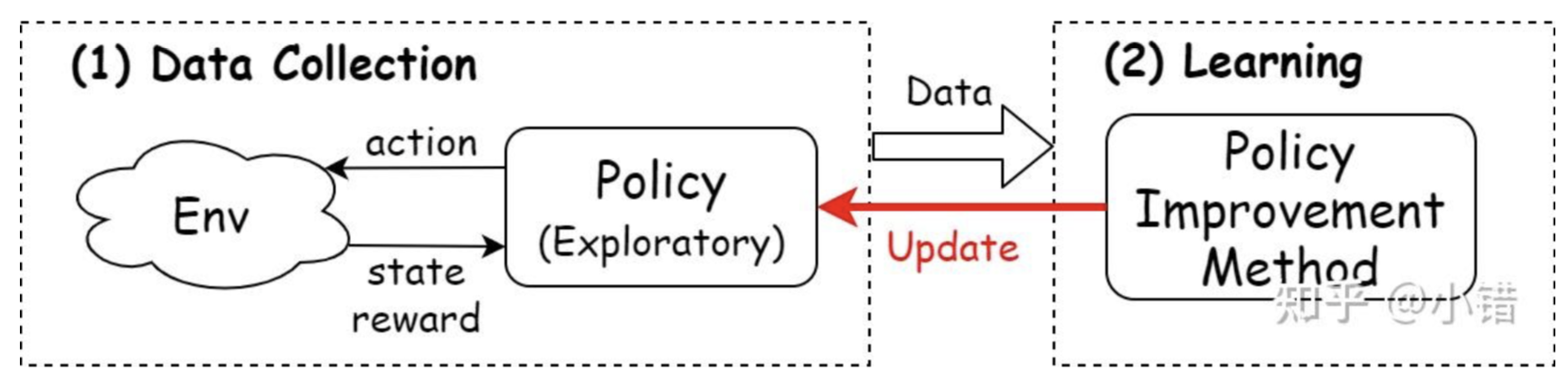
RL 算法可抽象为:
- 收集数据(Data Collection):与环境交互,收集学习样本;
- 学习(Learning)样本:学习收集到的样本中的信息,提升策略。
随机探索策略
先用Q函数构造确定性策略
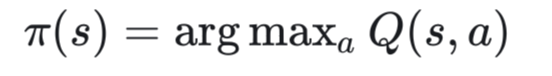
选取Q值最大的动作为最优动作。(注意:一般只有在动作空间离散的情况下采用这种策略,若动作空间连续上式中的最大化操作需要经过复杂的优化求解过程。)
再用 ε-greedy方法将上述确定性策略改造成具有探索能力的策略

以ϵ的概率选择随机动作(Exploration),以1-ϵ的概率按照确定性策略选取动作。
off-policy方法
将收集数据当做一个单独的任务 (Q-Learning)
off-policy的方法将收集数据作为RL算法中单独的一个任务,它准备两个策略:行为策略(behavior policy)与目标策略(target policy)。
- 行为策略:专门负责学习数据的获取,具有一定的随机性,总是有一定的概率选出潜在的最优动作。
- 目标策略:借助行为策略收集到的样本以及策略提升方法提升自身性能,并最终成为最优策略。
Q-Learning

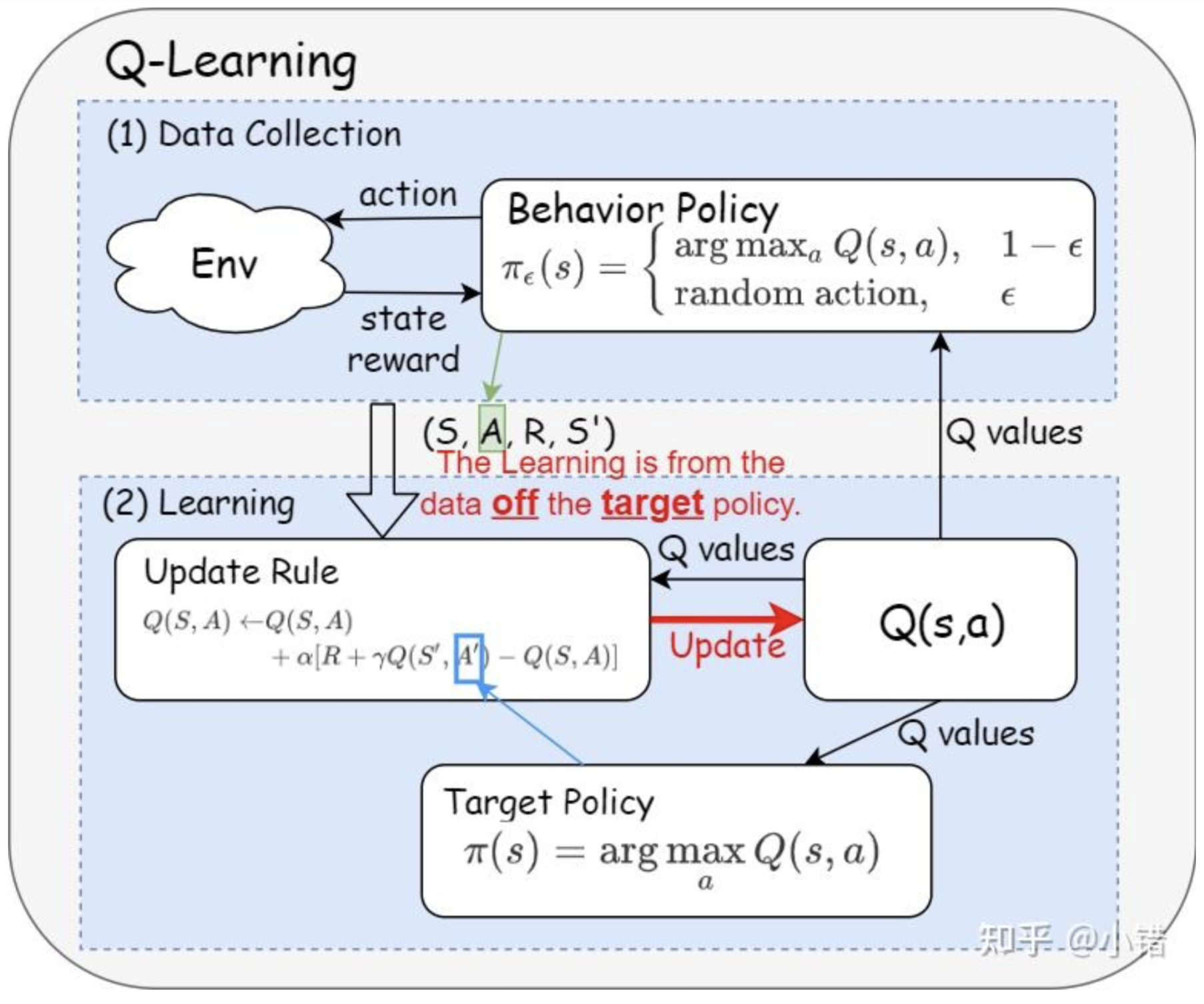
Q 函数更新规则(update rule)中的训练样本是由行为策略(而非目标策略)提供,因此它是典型的off-policy方法。
如果需要用off-policy方法估计/预测状态值或动作值时,需要用到重要性采样!
重要性采样:用一个概率分布的样本来估计某个随机变量关于另一个概率分布的期望。
假设已知随机策略π(a|s),现在需要估计策略π对应的状态值Vπ,但是只能用另一个策略 π′(a|s)获取样本。对于这种需要用另外一个策略的数据(off-policy)来精确估计状态值的任务,需要用到重要性采样的方法:具体做法是在对应的样本估计量上乘上一个权重(π与π′的相对概率),称为重要性采样率。
Q-Learning算法(或DQN)身为off-policy可以不用重要性采样
Q-Learning的思想:从任意初始化的Q函数出发,以最优贝尔曼方程为标准调整Q函数。

on-policy方法
on-policy里面只有一种策略,它既为目标策略又为行为策略。
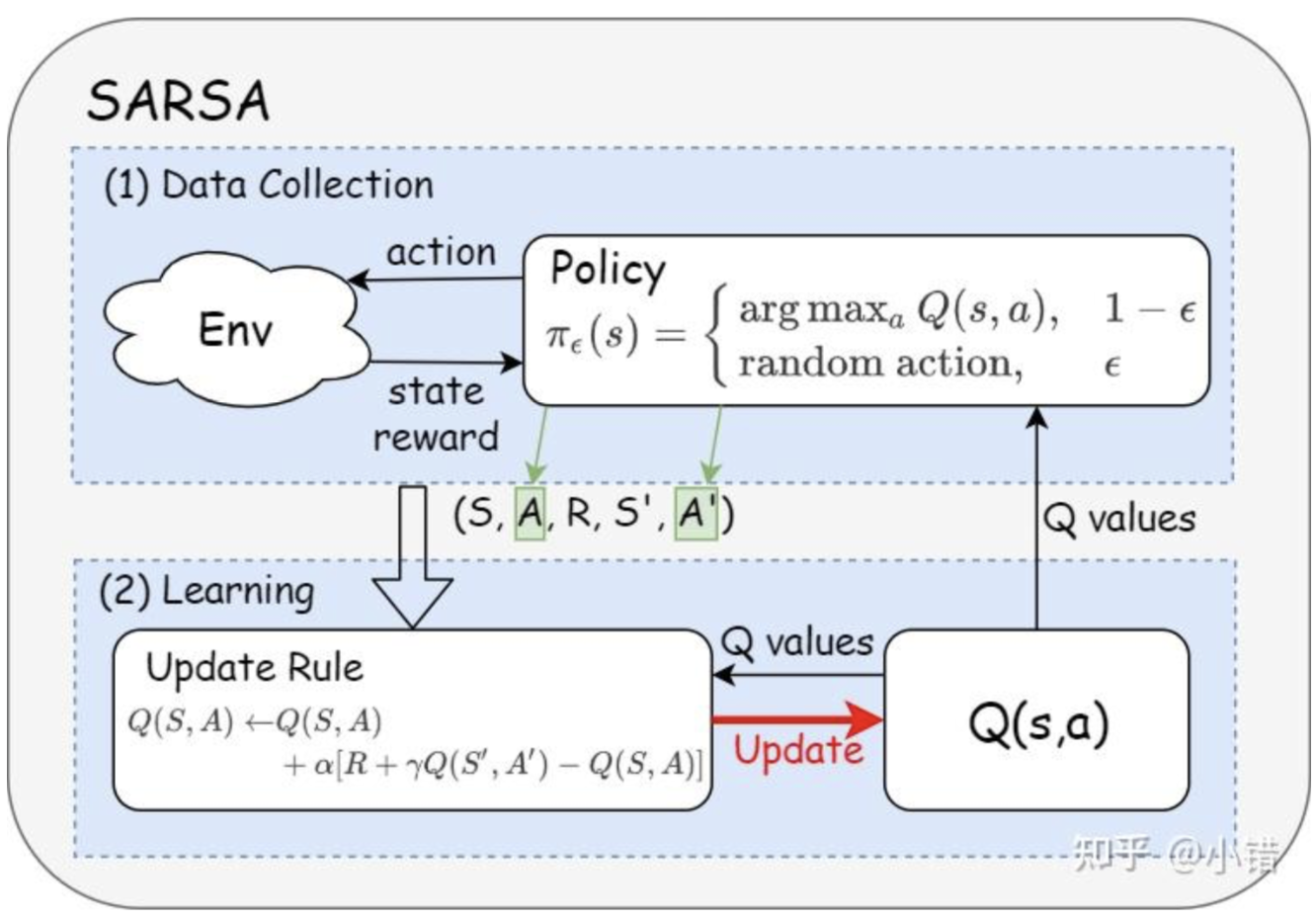
Actor-Critic 方法通常是 on-policy 的,Critic 的评估基于当前策略生成的数据,因此需要遵循当前策略来收集数据。
采集数据只用一次就要丢弃,训练速度慢。
重要性采样
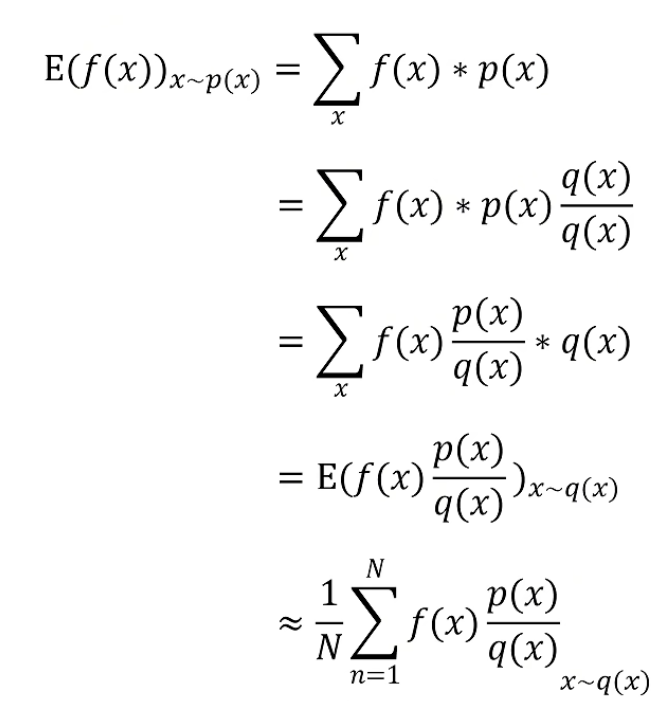
利用重要性采样更新目标函数的梯度公式,可以将on-policy策略替换为off-policy策略。
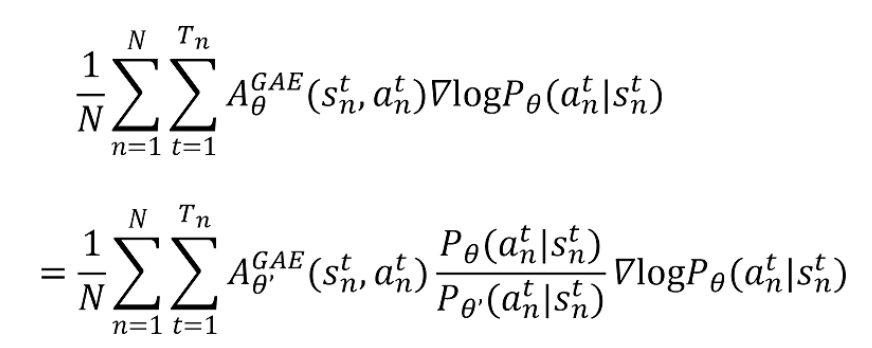
总结
- off-policy 的最简单解释: the learning is from the data off the target policy。
- on-policy 方法要求使用当前策略生成的数据来更新策略。
- on/off-policy的概念帮助区分训练的数据来自于哪里。
- off-policy方法中不一定非要采用重要性采样,要根据实际情况采用(比如,需要精确估计值函数时需要采用重要性采样;若是用于使值函数靠近最优值函数则不一定)。
例如:小明根据老师的表扬和批评来调整自己的行为,是on-policy;其他同学根据老师对小明的评价,调整自己的行为,是off-policy。
7. PPO
概述
算法全称 Proximal Policy Optimization(近端策略优化)。
核心思想:通过限制策略更新的幅度,避免策略更新过大导致训练不稳定。
使用了重要性采样(importance sampling)来复用旧策略的数据,同时通过限制策略更新的幅度来保证训练的稳定性。
loss函数
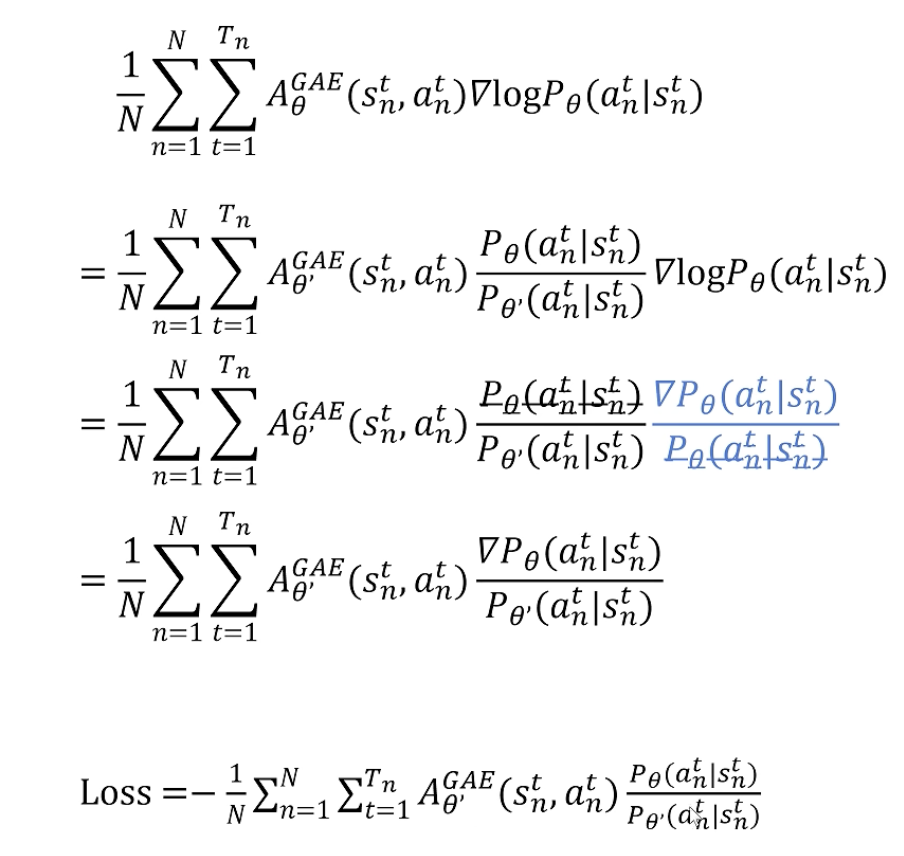
解决了on-policy 训练效率低的问题
用参考策略进行数据采样:通过重要性采样复用旧策略的数据,从而提高了数据利用率。
采样的数据可以多次用于训练:通过限制策略更新的幅度,使得旧策略的数据可以多次用于训练,从而提高了训练效率。
但是,训练策略和参考策略相差不能太大,不然很难学到有用的经验和训练。
添加KL散度作约束
目的:通过限制策略更新的幅度,避免了策略更新过大导致的训练不稳定。
- 法一:KL 散度是一种衡量两个概率分布相似程度的指标。分布越一致,KL散度越小。
- 法二:PPO-Clip 使用**截断函数(clipping function)**来限制策略更新的幅度,从而避免策略更新过大。
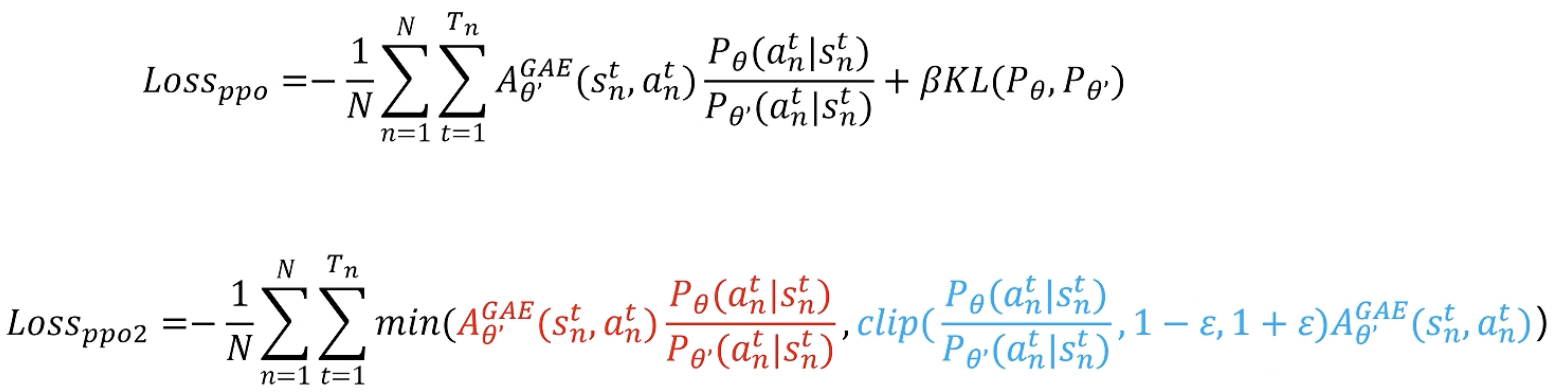
PPO-Clip 实现简单且效果稳定,因此在实践中更为常用。