RAG实践
RAG 整体框架
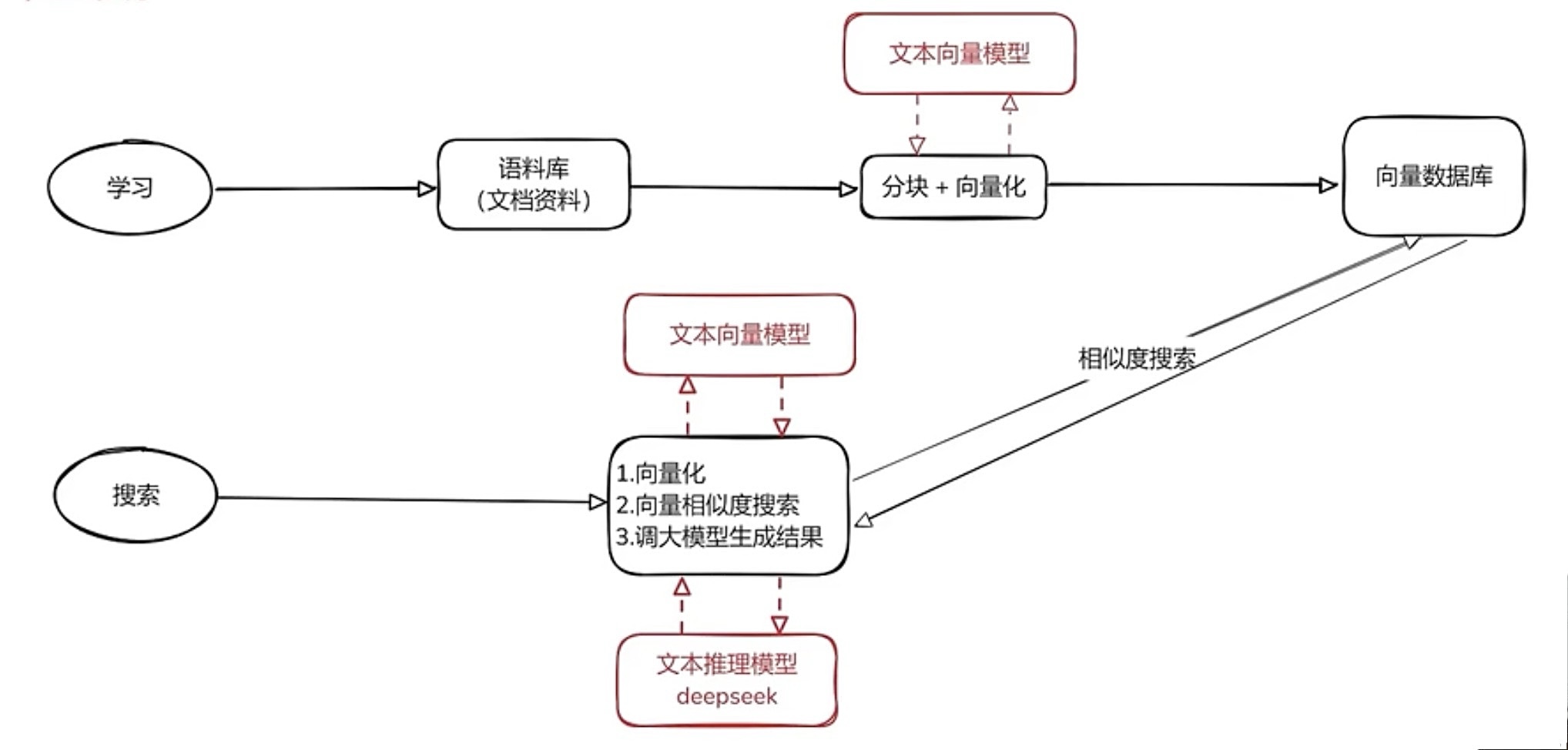
将语料库喂给LLM
- 文字分块向量化(利用LLM),从而基于向量相似度进行搜索
- 将得到的向量存储到向量数据库中
搜索
- 将用户问题进行向量化,在向量数据库中进行搜索,得到相关内容
- 将检索得到的相关内容(不一定相关)和关用户问题 一起传给 LLM
- LLM提取出相关信息,生成正确结果
LLM 常见参数
temperature
控制生成文本的随机性。温度越高,生成的文本越随机和创造性;温度越低,文本越趋向于确定性和重复性。
- 常见设置:通常设置在0.7到1之间。较低的温度(如0.7)可以使生成的文本更加连贯和准确,而较高的温度(如1)则使文本更加多样和创造性。
top_k
只从模型认为最可能的k个词中选择下一个词。k值越大,选择范围越广,生成的文本越多样;k值越小,选择范围越窄,生成的文本越趋向于高概率的词。
- 常见设置:一般设置在40到100之间。较小的
k值可以提高文本的相关性和连贯性,而较大的k值则增加了文本的多样性。
top_p
从概率累计达到p的那一组词中随机选择下一个词。与Top-K不同,Top-P是动态的,依据每个上下文的不同而变化。
- 常见设置:通常设置在0.8到0.95之间。较低的
top_p值(如0.8)使生成的文本更加可预测和相关,而较高的值(如0.95)增加了文本的多样性和创造性。
RAGFLow
最近在学习使用 RAGFlow,在这里记录一下遇到的问题。
部署
mac 部署 RAGFlow:https://jishuzhan.net/article/1889102793436827650
进入 ragflow 项目
使用 Docker 启动 “基本” 服务 (包括 MinIO、Elasticsearch、Redis 和 MySQL)
docker compose -f docker/docker-compose-base.yml up -d启动 RAGFlow 后端服务
激活 Python 虚拟环境:
source .venv/bin/activate # 设置 Python 路径(必须) export PYTHONPATH=$(pwd)设置 HuggingFace 镜像站点(可选):
export HF_ENDPOINT=https://hf-mirror.com启动后端服务:
bash docker/entrypoint.sh
启动 RAGFlow 前端服务
cd web npm run dev
为什么除了DeepSeek、RAGFlow外我还需要 “Embedding模型”?
Embedding 模型是用来对用户上传的附件进行解析的。
检索(Retrieval)过程:
淮备外部知识库:外部知识库可能来自本地的文件、搜索引擎结果、API等等。
通过 Embedding 模型,对知识库文件进行解析:Embedding的主要作用是将自然语言转化为机器可以理解的高维向量,并且通过这一过程捕获到文本背后的语义信息(比如不同文本之间的相似度关系)。
通过 Embedding 模型,对用户的提问进行处理:用户的输入同样会经过 Embedding 处理,生成一个高维向量。
拿用户的提问去匹配本地知识库:使用用户输入生成的高纬向量,去查询知识库中相关的文档片段。在这个过程中,系统会利用某些相似度度量(如cos相似度)去判断相似度。
模型分类:Chat模型 和 Embedding模型

DIFY
部署
部署 Dify:https://zhuanlan.zhihu.com/p/1899807556676854122
进入 dify 项目根目录找到 docker 文件夹
右键打开命令行,运行 docker 环境
docker compose -p dify -f docker-compose.yaml up -d启动 dify
http://localhost:5201
知识库创建
- 创建知识库。
- 指定分段模式。内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。
- 设定索引方法和检索设置。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。