REINFORCE
Q-learning、DQN 算法都是基于价值(value-based)的方法
- Q-learning 是处理有限状态的算法
- DQN 可以用来解决连续状态的问题
在强化学习中,除了基于值函数的方法,还有一支非常经典的方法,那就是基于策略(policy-based)的方法。
对比 value-based 和 policy-based
- 基于值函数:主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;
- 基于策略:直接显式地学习一个目标策略。策略梯度是基于策略的方法的基础。
1. 策略梯度
将策略参数化:寻找一个最优策略并最大化这个策略在环境中的期望回报,即调整策略参数使平均回报最大化。
策略学习的目标函数

- J(θ) 是策略的目标函数(想要最大化的量);
- πθ 是参数为θ的随机性策略,并且处处可微(可以理解为AI的决策规则);
- Vπθ(s0) 指从初始状态s₀开始遵循策略π能获得的预期总回报;
- Es0 是对所有可能的初始状态求期望。
对目标函数求导:
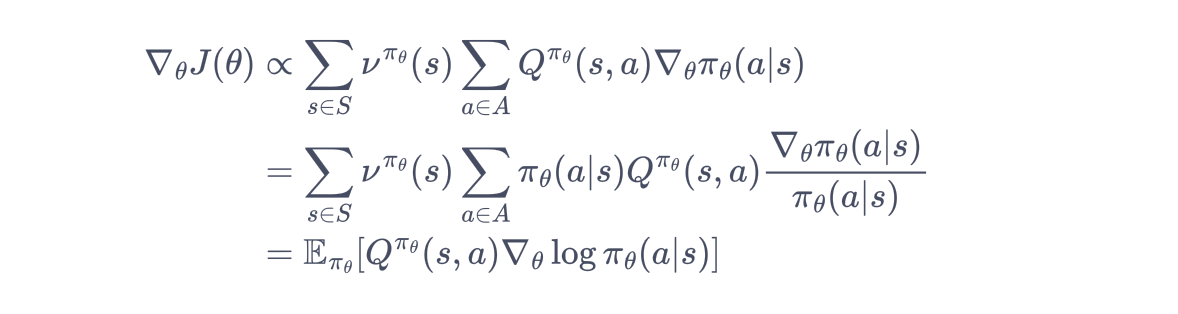
状态分布νπθ(s)
策略 πθ 下状态 s 的稳态分布(即在长期运行中,状态 s 出现的概率)
状态-动作值函数Qπθ(s,a)
在状态 s 下执行动作 a 后,按策略 πθ 继续执行能获得的期望回报
策略梯度 ∇θπθ(a∣s)
πθ(a∣s) 是策略在状态 s 下选择动作 a 的概率。
在每一个状态下,梯度的修改是让策略更多地去采样到带来较高值的动作,更少地去采样到带来较低值的动作。
注:期望E的下标是πθ,所以策略梯度算法为在线策略(on-policy)算法,即必须使用当前策略采样得到的数据来计算梯度。
2. REINFORCE
智能体根据当前策略直接和环境交互,通过采样得到的轨迹数据直接计算出策略参数的梯度,进而更新当前策略,使其向最大化策略期望回报的目标靠近。
策略梯度(有限步数的环境)
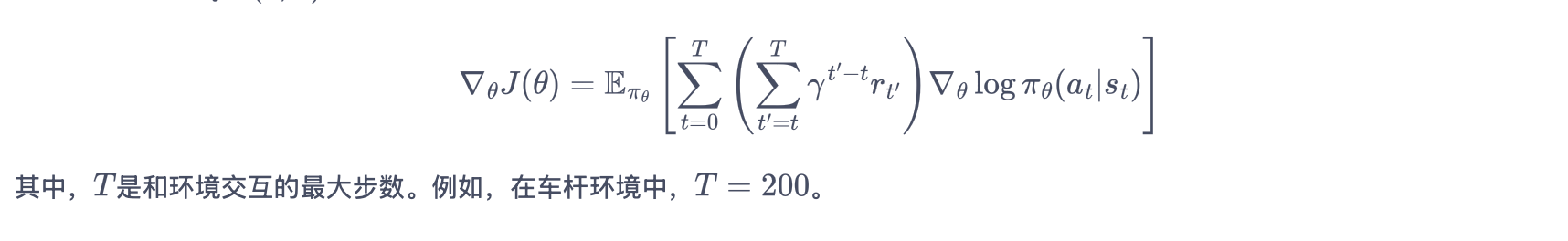
采用蒙特卡洛方法来估计 Qπθ(s,a)。
具体算法流程

import gym
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import rl_utils
定义策略网络
PolicyNet输入是某个状态,输出则是该状态下的动作概率分布。
这里采用在离散动作空间上的
softmax()函数来实现一个可学习的多项分布(multinomial distribution)。class PolicyNet(torch.nn.Module): def __init__(self, state_dim, hidden_dim, action_dim): super(PolicyNet, self).__init__() self.fc1 = torch.nn.Linear(state_dim, hidden_dim) self.fc2 = torch.nn.Linear(hidden_dim, action_dim) def forward(self, x): x = F.relu(self.fc1(x)) return F.softmax(self.fc2(x), dim=1)定义 REINFORCE 算法
在函数
take_action()函数中,我们通过动作概率分布对离散的动作进行采样。在更新过程中,我们按照算法将损失函数写为策略回报的负数,对θ求导后就可以通过梯度下降来更新策略。class REINFORCE: def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, device): self.policy_net = PolicyNet(state_dim, hidden_dim, action_dim).to(device) self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr=learning_rate) # 使用Adam优化器 self.gamma = gamma # 折扣因子 self.device = device def take_action(self, state): # 根据动作概率分布随机采样 state = torch.tensor([state], dtype=torch.float).to(self.device) probs = self.policy_net(state) action_dist = torch.distributions.Categorical(probs) action = action_dist.sample() return action.item() def update(self, transition_dict): reward_list = transition_dict['rewards'] state_list = transition_dict['states'] action_list = transition_dict['actions'] G = 0 self.optimizer.zero_grad() for i in reversed(range(len(reward_list))): # 从最后一步算起 reward = reward_list[i] state = torch.tensor([state_list[i]], dtype=torch.float).to(self.device) action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device) log_prob = torch.log(self.policy_net(state).gather(1, action)) G = self.gamma * G + reward loss = -log_prob * G # 每一步的损失函数 loss.backward() # 反向传播计算梯度 self.optimizer.step() # 梯度下降REINFORCE 算法在车杆环境上训练
learning_rate = 1e-3 num_episodes = 1000 hidden_dim = 128 gamma = 0.98 device = torch.device("cuda") if torch.cuda.is_available() else torch.device( "cpu") env_name = "CartPole-v0" env = gym.make(env_name) env.seed(0) torch.manual_seed(0) state_dim = env.observation_space.shape[0] action_dim = env.action_space.n agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma, device) return_list = [] for i in range(10): with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar: for i_episode in range(int(num_episodes / 10)): episode_return = 0 transition_dict = { 'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': [] } state = env.reset() done = False while not done: action = agent.take_action(state) next_state, reward, done, _ = env.step(action) transition_dict['states'].append(state) transition_dict['actions'].append(action) transition_dict['next_states'].append(next_state) transition_dict['rewards'].append(reward) transition_dict['dones'].append(done) state = next_state episode_return += reward return_list.append(episode_return) agent.update(transition_dict) if (i_episode + 1) % 10 == 0: pbar.set_postfix({ 'episode': '%d' % (num_episodes / 10 * i + i_episode + 1), 'return': '%.3f' % np.mean(return_list[-10:]) }) pbar.update(1)
REINFORCE 算法使用了更多的序列,这是因为 REINFORCE 算法是一个在线策略算法,之前收集到的轨迹数据不会被再次利用。
此外,REINFORCE 算法的性能也有一定程度的波动,这主要是因为每条采样轨迹的回报值波动比较大,这也是 REINFORCE 算法主要的不足。
REINFORCE 通过蒙特卡洛采样的方法对策略梯度的估计是无偏的,但是方差非常大。我们可以引入基线函数(baseline function)来减小方差。