vLLM
vLLM 是一个专门用于高效运行大语言模型的 Python 库。
KV Cache
大模型推理时 huggingface 按照可生成最长序列长度分配显存。但这造成三种类型的浪费:
- 预分配最大的 token 数,但不会用到。
- 剩下的 token 还尚未用到,但现存已被预分配占用。
- 显存之间的间隔碎片,因为 prompt 之间不同,显存不足以预分配给下一个文本生成。
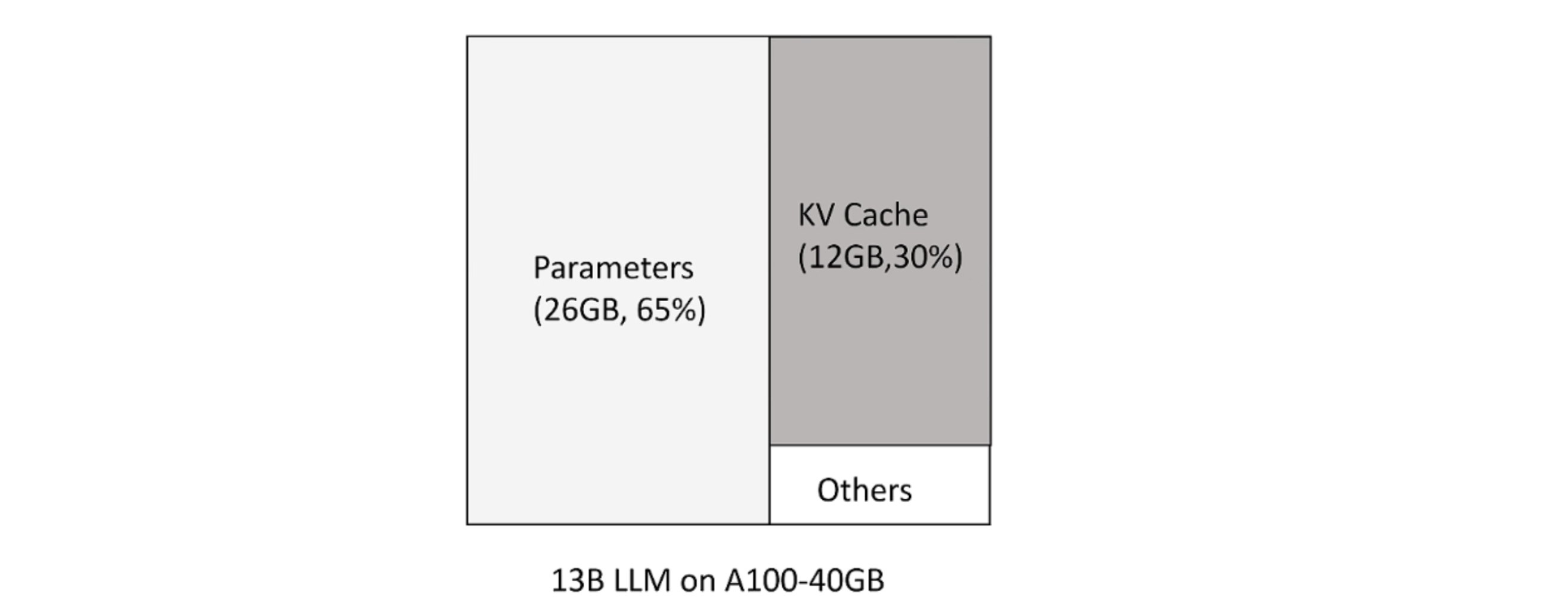
新 token 只用到前面 token 的 kv 向量,事实上只需保存之前的 kv 向量。
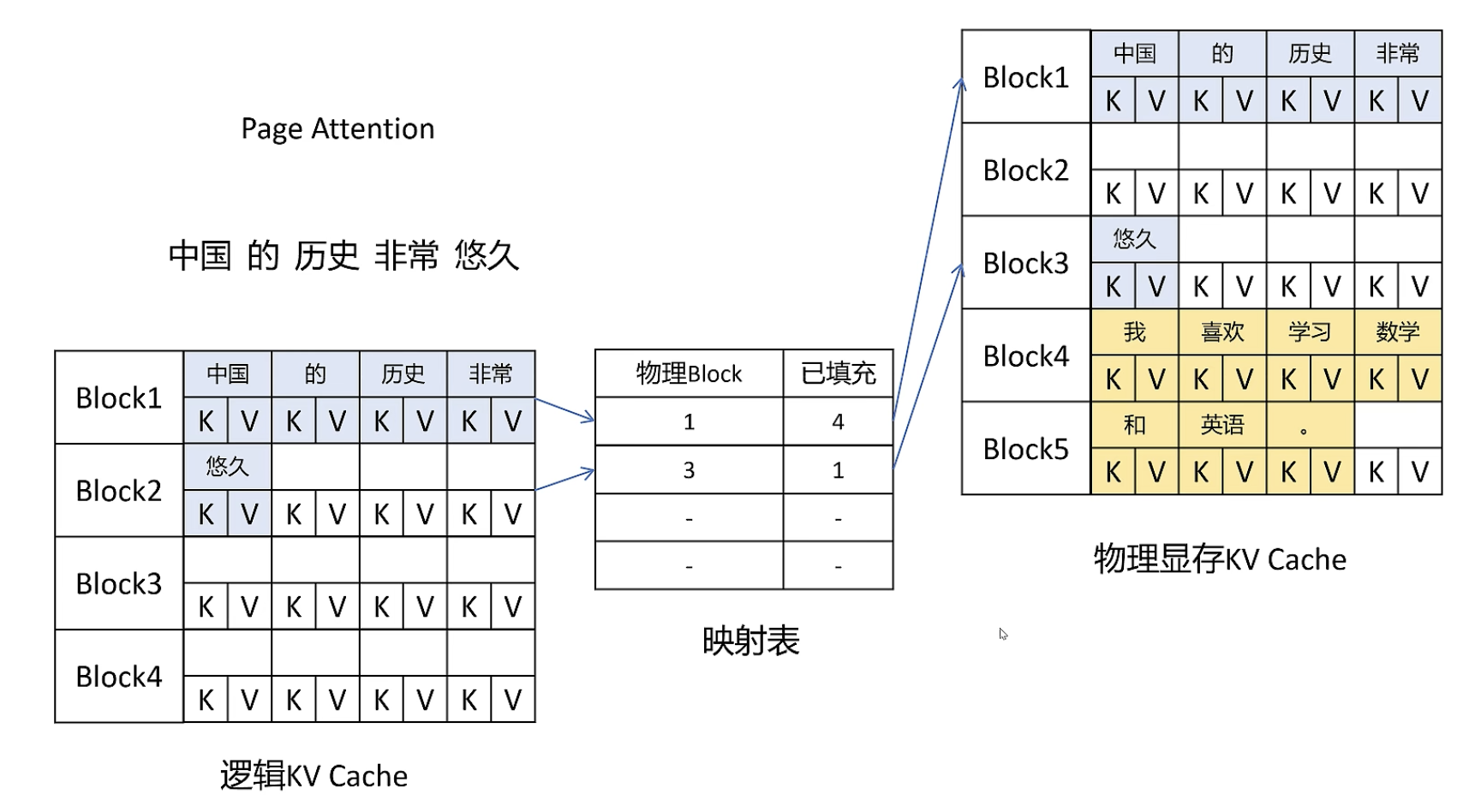
Page Attention
借鉴 OS 中的虚拟内存和页管理技术,把显存划分为 KVBlock,显存按照 KVBlock 来管理 KVCache,不用提前分配。
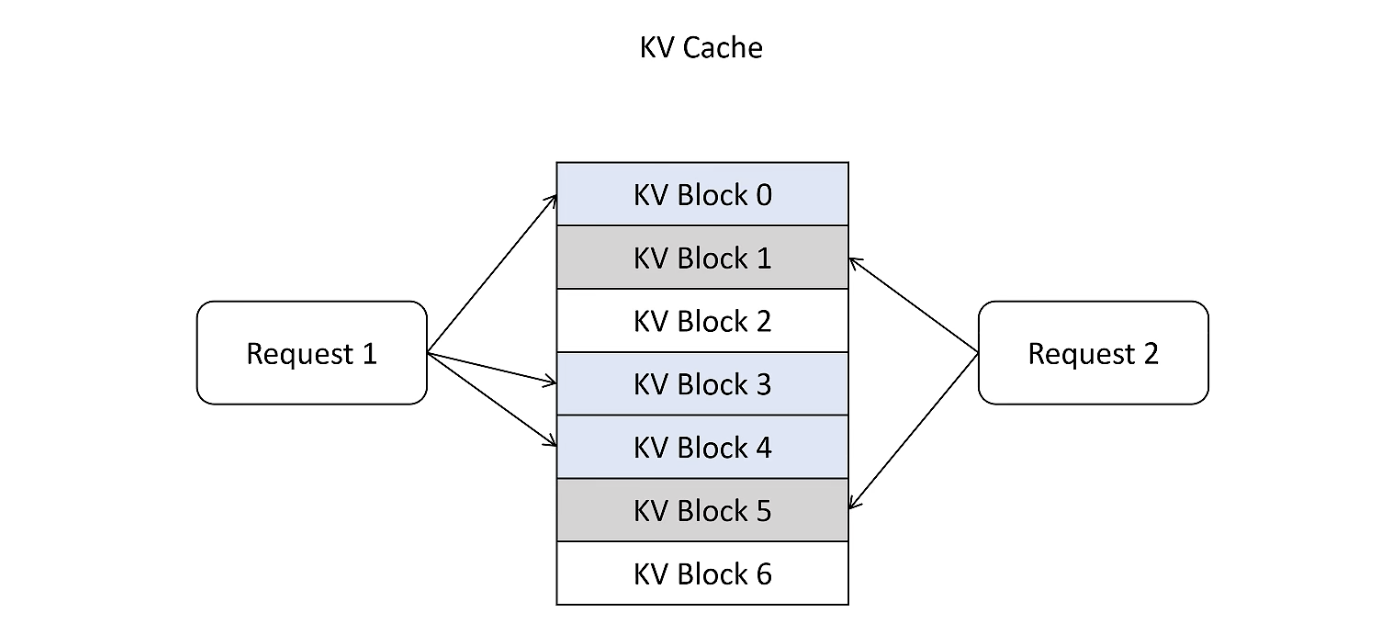
虚拟内存
每个请求都有一个逻辑的 KVCache,VLLM 会在后台维护一个逻辑映射表:
KVBlocks 共享
增加引用标志,不同序列的同一个 prompt 可以在物理上存放为同一份 KVBlock。当且仅当引用数为0时对应显存才会被释放。
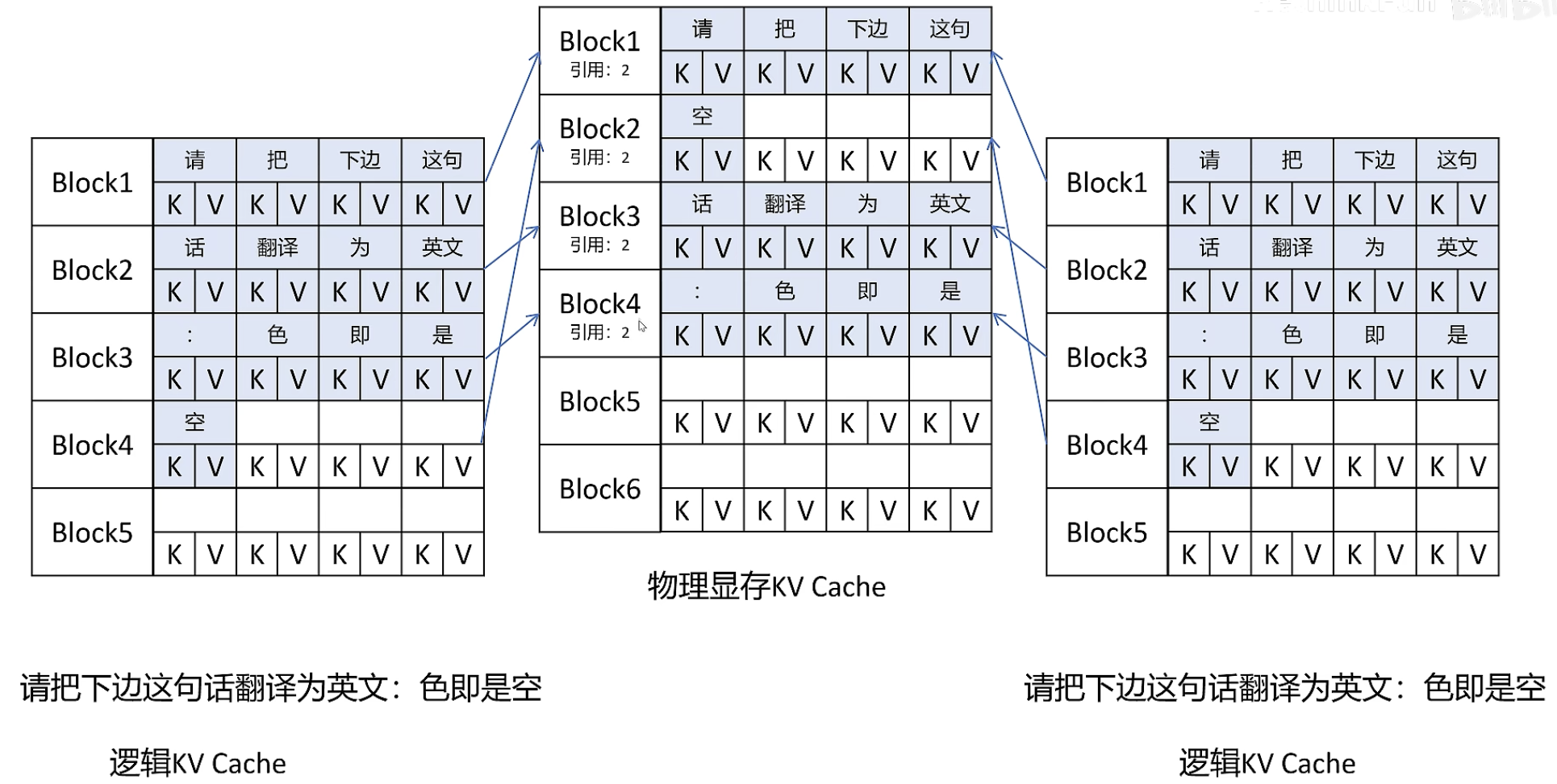
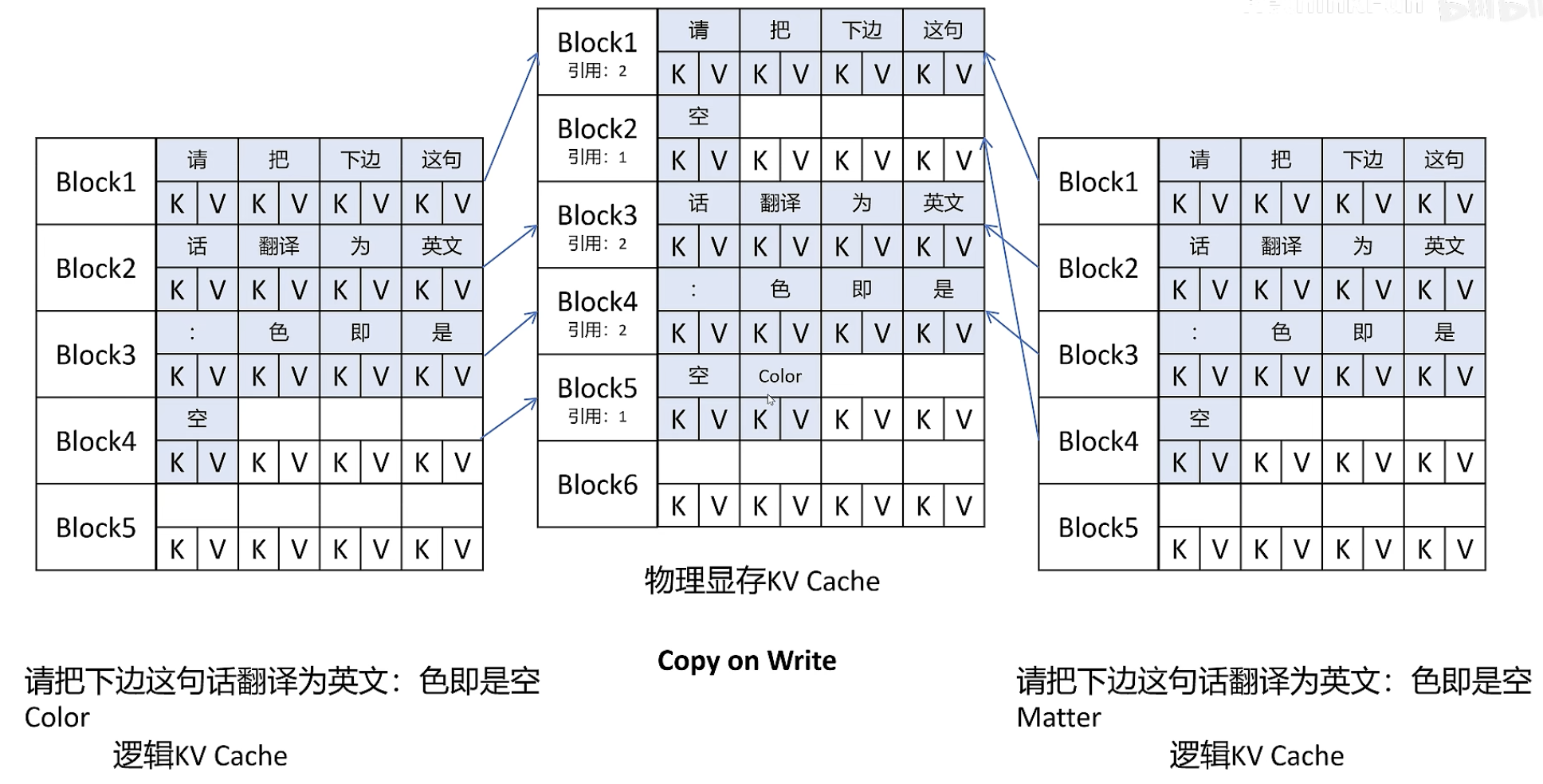
Copy on Write
写入时,当引用数不为1时,不能直接写,需要拷贝一份后再写入新的KVBlock,同时原有的 KVBlock 引用数减1:
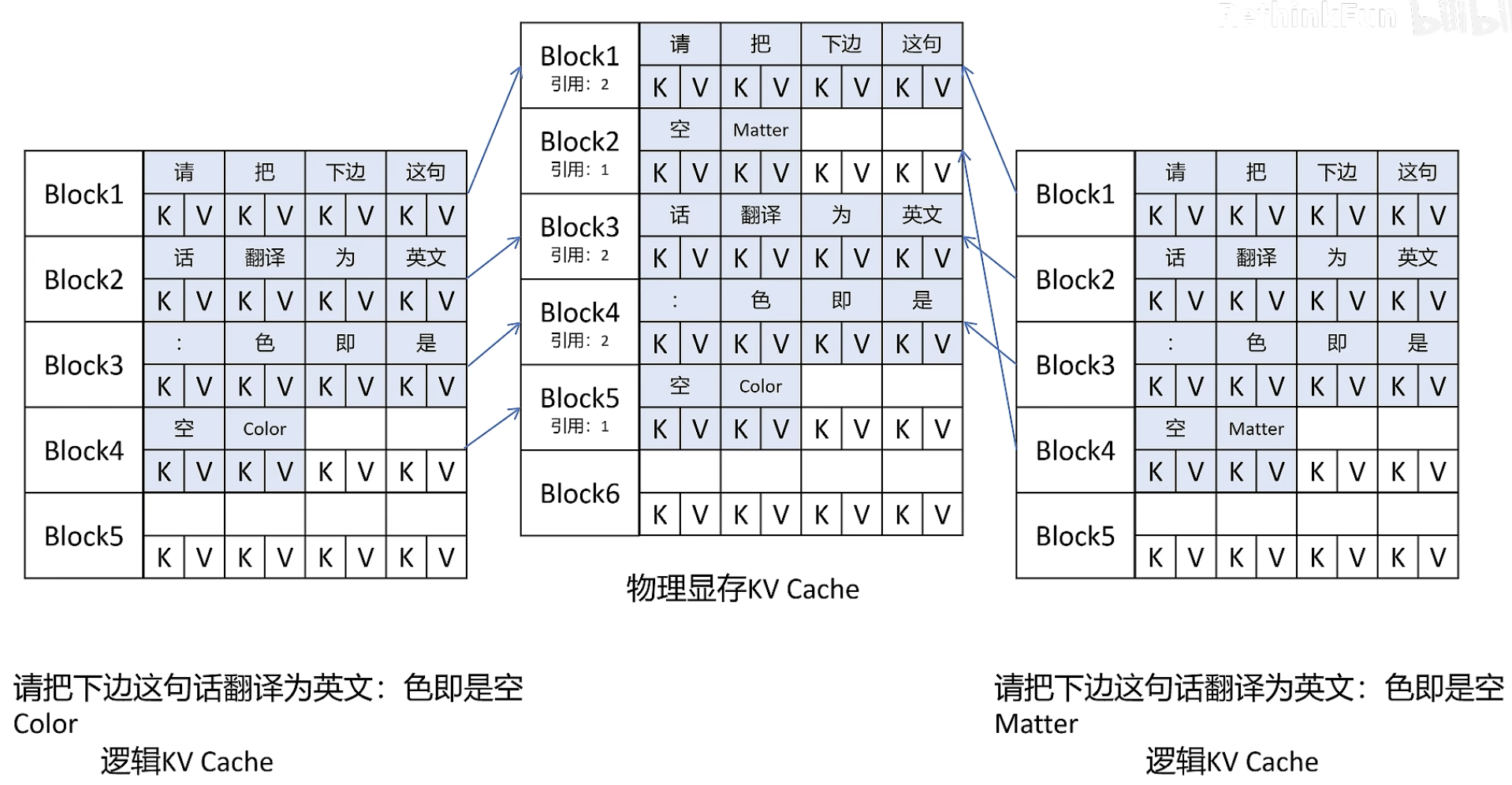
当引用数为1时,可以直接写入下一个 token:
离线批量推理
导入 LLM 和 SamplingParams 类
- LLM 是使用 vLLM 引擎运行离线推理的主要类
- SamplingParams 指定采样过程的参数
from vllm import LLM, SamplingParams定义一系列输入提示词和文本生成采样参数
prompts = [ "Hello, my name is", "The president of the United States is", "The capital of France is", "The future of AI is", ] sampling_params = SamplingParams(temperature=0.8, top_p=0.95)temperature:用于控制采样的随机性。较低的值使模型更具确定性,而较高的值使模型更具随机性。零表示贪婪采样。top_p:float 值,控制排名靠前的 Token 的累积概率。设置为 1 表示考虑所有标记。top_k:float 值,控制排名靠前的令牌数的整数。0/-1 表示考虑所有令牌。min_p:float 值,表示考虑 Token 的最小概率。设置为 0 表示禁用此功能。seed:用于生成的 Random seed。n:给定提示词,返回的输出序列数best_of:给定提示词,生成的输出序列presence_penalty:float 值,基于 new tokens 目前为止是否出现在 生成的文档 里。值 > 0 鼓励模型使用新标记,而值 < 0 鼓励模型重复标记。frequency_penalty:float 值,基于 new tokens 在生成文档中的频率。值 > 0 鼓励模型使用新标记,而值 < 0 鼓励模型重复标记。repetition_penalty:float 值,基于 new tokens 目前为止是否出现在 提示词 和 生成的文档 里。值 > 0 鼓励模型使用新标记,而值 < 0 鼓励模型重复标记。stop:停止生成时,生成的字符串列表。stop_token_ids:停止生成时,生成的 tokens 列表。bad_words:不允许生成的单词列表。max_tokens:每个输出序列的最大 tokens 数。min_tokens:每个输出序列的最小 tokens 数。
LLM 类初始化 vLLM 的引擎、用于离线推理的 OPT-125M 模型
llm = LLM(model="facebook/opt-125m")支持的模型列表:https://docs.vllm.com.cn/en/latest/features/reasoning_outputs.html#supported-models
使用
llm.generate输出生成outputs = llm.generate(prompts, sampling_params) for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")- 将输入提示词添加到 vLLM 引擎的等待队列中
- 执行 vLLM 引擎以高吞吐量生成输出。输出以
RequestOutput对象的列表形式返回,其中包括所有输出 token。
在线服务:使用 OpenAI 兼容服务器
默认情况下,vllm 在 http://localhost:8000 启动服务器,该服务器可以以 OpenAI API 相同的格式进行查询。用户可使用 --host 和 --port 参数指定地址。
启动模型为 Qwen2.5-1.5B-Instruct 的 vLLM 服务器。
vllm serve Qwen/Qwen2.5-1.5B-Instruct查询模型:
curl http://localhost:8000/v1/models
使用 vLLM 的 OpenAI Completions API
使用输入提示词查询:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
通过 openai Python 包查询:
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="Qwen/Qwen2.5-1.5B-Instruct",
prompt="San Francisco is a")
print("Completion result:", completion)
使用 vLLM 的 OpenAI Chat Completions API
使用 创建聊天补全 端点与模型交互:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
使用 openai Python 包与模型交互:
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-1.5B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)