Tag: Diary
「11.11」科研随笔
实习/入学后一直有些忙,其实学习了很多新的东西,但总感觉不太成体系,或者就是没时间,所以很久没记录了。
最近思考了很久要做什么方向,该做什么样的工作,怎么做出有影响里的工作呢。我很想做一些简单、通用、elegant 的工作,可惜过了很久的时间也没一个很具体的想法。是不是应该从小的 case 开始入手呢?多智能体最近看起来挺热门的,入手也简单,但总觉得它们太繁复了。
Tag: Paper
「论文阅读」RAG 文献调研
评估
RagChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Introduction
评估 RAG 系统的难点
- 模块化复杂
- 指标限制
- 检索器:传统指标(如 recall@k 和 MRR)依于 带注释的分块 和 严格的分块方式,忽视了知识库的完整语义范围
- 生成器:典型度量(如,基于 n-gram 的方法(如BLEU 和 ROUGE)、基于嵌入的方法(例如,BERTScore)和基于 LLM 的方法等)等可处理简单回答,但无法在较长的响应中检测到更精细的区别。
- 指标可靠性
对比其他(RAGAS、TruLens、ARES、RGB、RECALL、NoMIRAC),RagChecker 能 从人类角度评估 RAG 系统质量和可靠性方面的有效性,对错误来源做分析。
Related Work
现有评估可分为两种方法:仅评估 generators 的基本功能 和 评估 RAG 系统的端到端性能。
Triton Prompt
AutoTriton
TritonBench Infer Prompt
SYS_INSTRUCTION = """Use triton language write a kernel and wrapper according to the following instruction:
"""
INSTRUCTION_EXTRA = """The wrapper function should have same input and output as in instruction, and written with 'def xxx' DIRECTLY, do not wrap the wrapper inside a class. You may write it as:
```python
@triton.jit
def kernel([parameters]):
# your implementation
def wrapper ([parameters]):
# your implementation
```
"""
prompt = f"""{SYS_INSTRUCTION}
{ORIGINAL_INSTRUCTION}
{INSTRUCTION_EXTRA}
"""
KernelBench Infer Prompt
PROBLEM_STATEMENT = """You are given a pytorch function, and your task is to write the same triton implementation for it.
The triton implementation should change the name from Model to ModelNew, and have same input and output as the pytorch function."""
PROBLEM_INSTRUCTION = """Optimize the architecture with custom Triton kernels! Name your optimized output architecture ModelNew. Output the new code in codeblocks. Please generate real code, NOT pseudocode, make sure the code compiles and is fully functional. Just output the new model code, no input and init function, no other text, and NO testing code! **Remember to Name your optimized output architecture ModelNew, do not use Model again!**"""
prompt = f"""{PROBLEM_STATEMENT}
{PROBLEM_INSTRUCTION}
Now, you need to write the triton implementation for the following pytorch code:
```
{arc_src}
```
"""
CUDA- L1
SFT
Task for CUDA Optimization
You are an expert in CUDA programming and GPU kernel optimization. Now you’re tasked with developing a
high-performance cuda implementation of Softmax. The implementation must:
• Produce identical results to the reference PyTorch implementation.
• Demonstrate speed improvements on GPU.
• Maintain stability for large input values.
Reference Implementation (exact copy)
import torch
import torch.nn as nn
class Model(nn.Module):
"""
Simple model that performs a Softmax activation.
"""
def __init__(self):
super(Model, self).__init__()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Applies Softmax activation to the input tensor.
Args:
x (torch.Tensor): Input tensor of shape (batch_size, num_features).
Returns:
torch.Tensor: Output tensor with Softmax applied, same shape as input.
"""
return torch.softmax(x, dim=1)
batch_size = 16
dim = 16384
def get_inputs():
x = torch.randn(batch_size, dim)
return [x]
def get_init_inputs():
RL
显卡
1. 消费级显卡(GeForce RTX系列)
适合个人研究者、小规模训练或微调,性价比较高,但显存较小,不适合超大规模模型。
- RTX 4090
- CUDA核心:16,384
- 显存:24GB GDDR6X
- 适合:单卡训练中等规模模型(如LLaMA-7B/13B微调)。
- RTX 4080/4080 Super
- 显存:16GB GDDR6X
- 适合:小规模模型或推理。
- RTX 3090/3090 Ti
- 显存:24GB GDDR6X(二手市场常见,性价比高)。
- RTX 6000 Ada Generation(工作站级)
- 显存:48GB GDDR6(ECC支持),适合需要大显存的场景。
注意:消费级显卡通常无ECC显存校验,且多卡并行效率低于专业卡。
2. 专业级显卡(NVIDIA RTX/Tesla系列)
针对数据中心和企业级训练,支持多卡高速互联(NVLink)、ECC显存等特性。
- RTX 5000/6000 Ada
- 显存:32GB~48GB GDDR6,支持NVLink,适合中等规模训练。
- Tesla V100(Volta架构)
- 显存:16GB/32GB HBM2(32GB版更受欢迎)。
- 支持Tensor Core(混合精度训练),曾是早期Transformer模型的标配。
- Tesla A100(Ampere架构)
- 显存:40GB/80GB HBM2e(带宽1555GB/s)。
- 支持NVLink 3.0(多卡互联带宽600GB/s),适合大规模分布式训练。
- Tesla H100(Hopper架构)
- 显存:80GB HBM3(带宽3TB/s)。
- 支持Transformer引擎(加速LLM训练),性能较A100提升数倍。
3. 数据中心级显卡(计算加速卡)
专为AI训练和HPC设计,通常需搭配服务器使用。
- A100 80GB
- 行业标杆,支持多实例GPU(MIG),可分割为多个计算单元。
- H100
- PCIe版和SXM版(后者性能更强),适合LLM训练(如GPT-4级别模型)。
- B100/B200(2024年发布)
- 下一代AI加速卡,预计性能较H100再提升。
4. 特殊用途显卡
- DGX系统:英伟达预配置的AI服务器,如DGX A100(8×A100)、DGX H100。
- Grace Hopper超级芯片:CPU+GPU集成设计,针对超大规模AI优化。
选择建议
- 入门/个人学习:RTX 3090/4090(24GB显存可微调中小模型)。
- 中小团队:A100 40GB(二手)或RTX 6000 Ada(48GB)。
- 企业级训练:H100集群或A100/H100多卡服务器(需NVLink支持)。
关键参数对比
| 显卡型号 | 架构 | 显存容量 | 显存类型 | NVLink支持 | 典型用途 |
|---|---|---|---|---|---|
| RTX 4090 | Ada | 24GB | GDDR6X | 无 | 个人研究/小规模训练 |
| A100 80GB | Ampere | 80GB | HBM2e | 是 | 大规模分布式训练 |
| H100 80GB | Hopper | 80GB | HBM3 | 是 | LLM训练/超算 |
| RTX 6000 Ada | Ada | 48GB | GDDR6 | 是 | 工作站级训练 |
如果需要更具体的推荐(如预算、模型规模),可以进一步补充信息!
「源码阅读」KernelBench
任务描述
构建 KernelBench 有 4 个级别的任务:
- Level 1 🧱: 单核算子(100 个问题),如卷积、矩阵乘法、层归一化
- Level 2 🔗: 简单融合模式(100 个问题),如 Conv + Bias + ReLU,Matmul + Scale + Sigmoid
- Level 3 ⚛️: 端到端全模型架构(50个问题),如MobileNet、VGG、MiniGPT、Mamba)
- Level 4 🤗: Hugging Face 优化过的整个模型架构
评估方法
正确性检查✅:确保模型生成的 kernel 在功能上与参考实现(如 PyTorch 的官方算子)完全一致。进行
n_correctness次测试。性能评估⏱️:验证生成的 kernel 是否比参考实现更高效。重复
n_trial次消除偶然误差。指标是加速比。
实现代码位于: src/eval.py
评估脚本: scripts/run_and_check.py
总基准指标
fast_p:既正确又加速大于阈值的任务的分数p。提高加速阈值p可使任务更具挑战性。加速比:PyTorch 参考实现运行时间 与 生成的内核时间 之比。
计算整体基准测试性能脚本: scripts/greedy_analysis.py
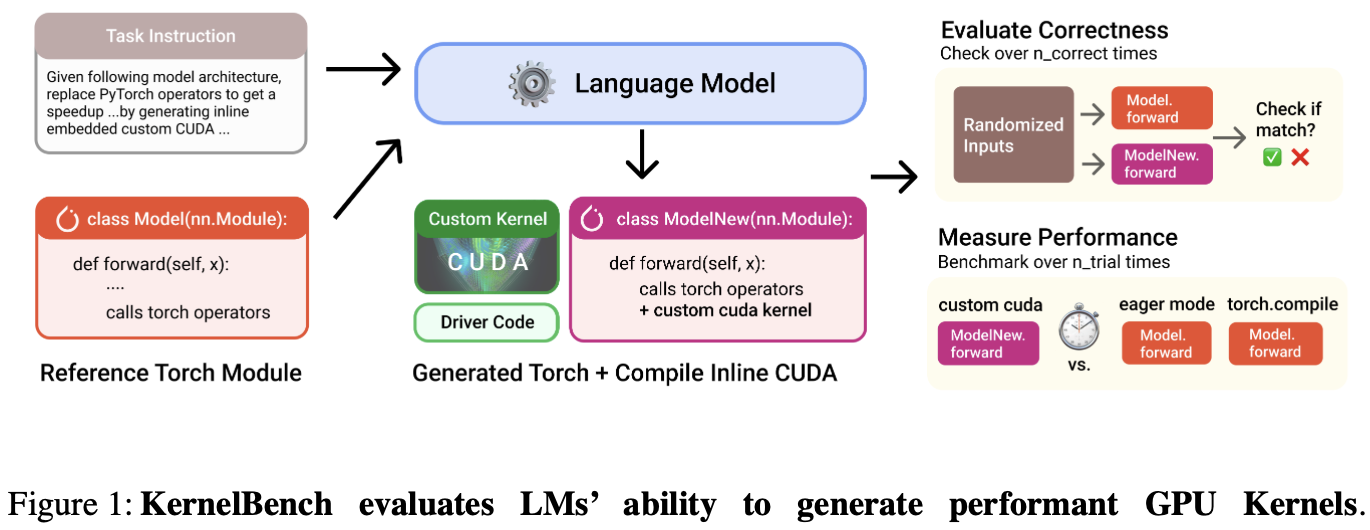
「论文阅读」KernelBench
KernelBench 是一个评估 LLMs 在生成高性能 GPU 内核代码上能力的基准测试框架。论文引入了新评估指标 fast_p:衡量生成的 正确、且速度提升超过阈值p 的内核的比例。
Introduction
背景:每个硬件都有不同的规格和指令集,跨平台移植算法是痛点。
论文核心探讨:LM 可以帮助编写正确和优化的内核吗?
KernelBench 的任务:让 LMs 基于给定的 PyTorch 目标模型架构,生成优化的 CUDA 内核;并进行自动评估。
环境要求
自动化 AI 工程师的工作流程。
支持多种 AI 算法、编程语言和硬件平台。
轻松评估 LM 代的性能和功能正确性,并从生成的内核中分析信息。
测试级别
Individual operations::如 AI 运算符、包括矩阵乘法、卷积和损失。
Sequence of operations:评估模型融合多个算子的能力。
端到端架构:Github 上流行 AI 存储库中的架构。
工作流程
GraphRAG
特点
- 基于图的检索:GraphRAG 引入知识图谱来捕捉实体、关系及其他重要元数据。
- 层次聚类:GraphRAG 使用 Leiden 技术进行层次聚类,将实体及其关系进行组织。
- 多模式查询:支持多种查询模式。
- 全局搜索:利用社区总结来进行全局性推理。
- 局部搜索:通过扩展相关实体的邻居和关联概念来进行具体实体的推理。
- DRIFT 搜索:结合局部搜索和社区信息,提供更准确和相关的答案。
- 图机器学习:集成图机器学习技术,并提供来自结构化和非结构化数据的深度洞察。
- Prompt 调优:提供调优工具,帮助根据特定数据和需求调整查询提示,提高结果质量。
工作流程
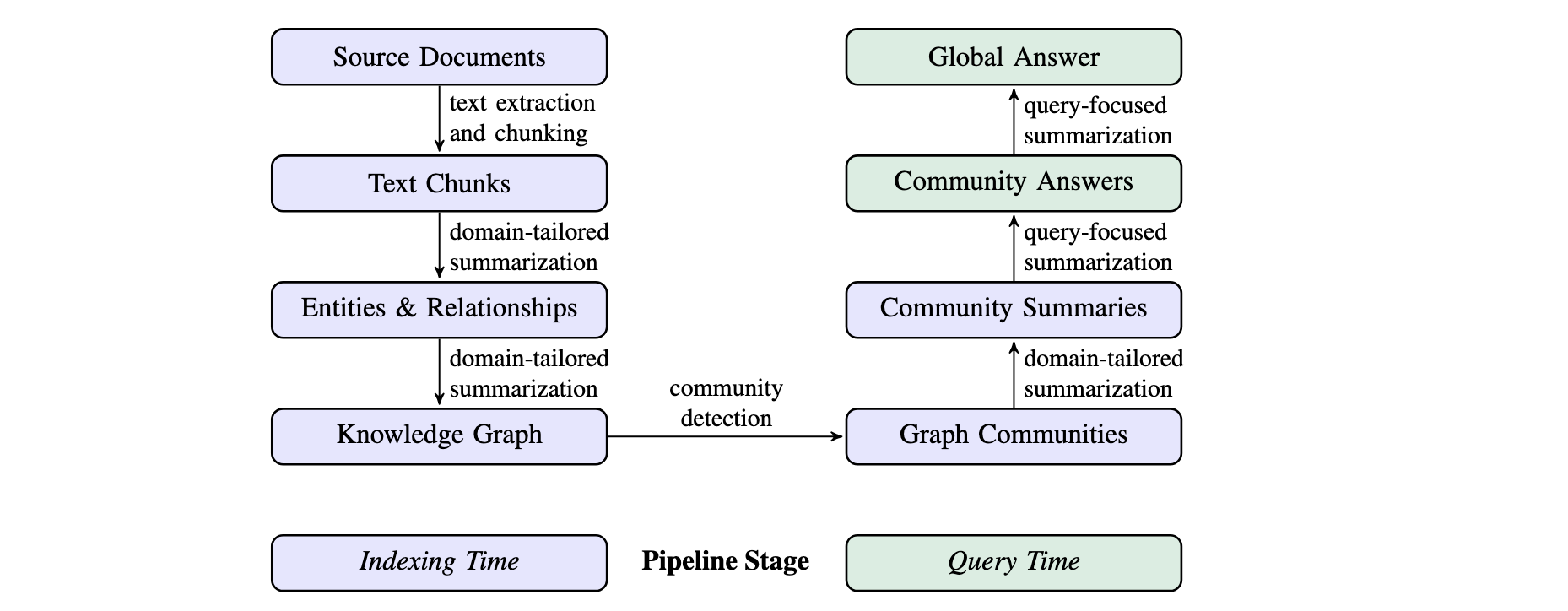
1 索引 (Indexing) 过程
将原始文档转化为知识图谱
「论文阅读」Triton LLM
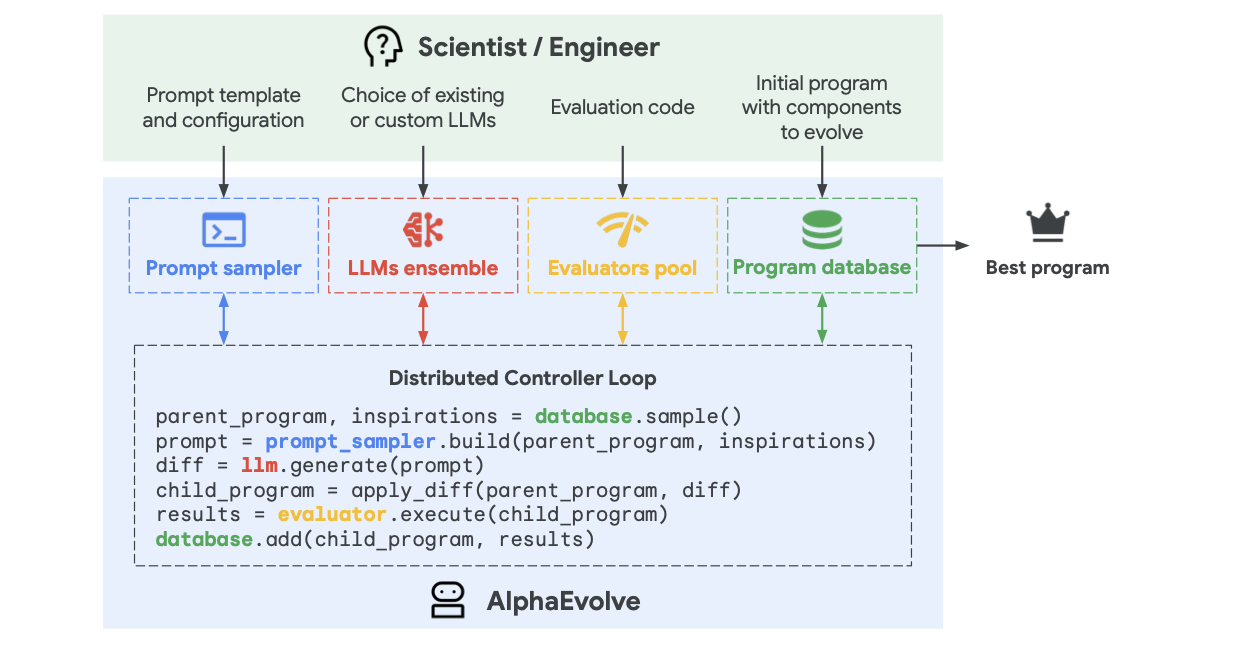
AlphaEvolve: A coding agent for scientific and algorithmic discovery
AlphaEvolve 使用进化方法,不断接收来自一个或多个评估者的反馈,迭代改进算法,从而有可能带来新的科学和实践发现。
Introduction
AlphaEvolve represents the candidates (for example, new mathematical objects or practical heuristics) as algorithms and uses a set of LLMs to generate, critique, and evolve a pool of such algorithms.

AlphaEvolve
「论文阅读」Kimi-Researcher
这篇技术报告提出了完全通过端到端 agentic reinforcement learning 进行训练的自主智能体 Kimi-Researcher,旨在通过多步骤规划、推理和工具使用来解决复杂问题。
—— End-to-end agentic RL is promising but challenging
传统 agent
- 基于工作流:需要随着模型或环境的变化而频繁手动更新,缺乏可扩展性和灵活性。
- 使用监督微调 (SFT)进行模仿学习:在数据标记方面存在困难;特定的工具版本紧密耦合。
Kimi-Researcher:给定一个查询,agent 探索大量可能的策略,获得正确解决方案的奖励 —— 所有技能(规划、感知和工具使用)都是一起学习的,无需手工制作的rule/workflow。
建模
给定状态观察(如系统提示符、工具声明和用户查询),Kimi-Researcher 会生成 think和action (action 可以是工具调用,也可以是终止轨迹的指示)。

Approach
主要利用三个工具:a)并行、实时、内部的 search tool; b) 用于交互式 Web 任务的基于文本的 browser tool; c)用于自动执行代码的 coding tool.
「论文阅读」Augmented Knowledge Graph Querying leveraging LLMs
这篇论文引入了一个名为 SparqLLM 的框架,通过结合 RAG 与 LLM,实现了从自然语言到 SPARQL 查询的自动生成,以简化知识图谱的查询过程。
1 Introduction
背景:非技术员工不懂 SPARQL;KG + LLMs 无法生成精确高效的 SPARQL 查询,且存在幻觉问题。
SparqLLM:被设计为 RAG 框架,可自动从自然语言问题生成 SPARQL 查询,同时生成最适当的数据可视化以返回获得的结果。
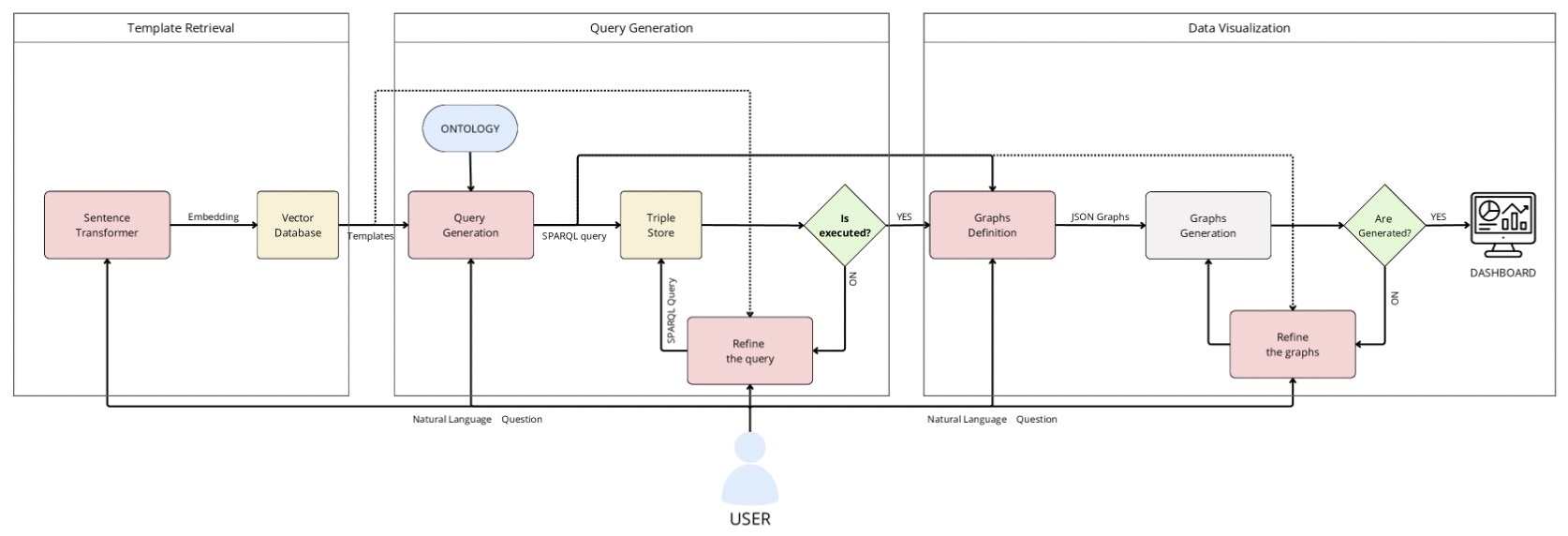
目标:提高 KG 的准确性、可用性和可靠性,实现与语义数据的更直观和有效的交互。
2 Related Work
自然语言接口 (NLI):将非结构化输入转换为 SPARQL 等正式查询语言,使非技术用户更容易访问基于 RDF 的知识图谱。
LLMs:利用它们处理和生成复杂文本的能力,为自动生成查询提供了一个强大的框架,减少了人工干预的需要,使非专家用户也能访问知识图谱。
基于模板的方法:通过为查询生成提供确定性框架来补充上述方法。
「论文阅读」Generate-on-Graph: Treat LLM as both Agent and KG for Incomplete Knowledge Graph Question Answering
这篇论文提出了一种称为 Generate-on-Graph(GoG) 的免训练方法,它可以在探索 KG 时,生成新的事实三元组。
具体来说,在不完全知识图谱(IKGQA) 中,GoG 通过 Thinking-Searching-Generating 框架进行推理,它将 LLM 同时视为 Agent 和 KG。
1 Introduction
Tag: Data
JSON
JSON Types
Strings:“Hello World” “Kyle”
Numbers:10 1.5 -30 1.2e10
Booleans:true false
null:null
Arrays:[1, 2, 3] [“Hello”, “World”]
Objects:{ “key”: “value” }: {“age”: 30}
可嵌套
{
"name": "Kyle"
"favoriteNumber": 3,
"isProgrammer": true,
"hobbies": ["Weight Lifting",
"Bowling"],
"friends": [{
"name": "Joey",
"favoriteNumber": 100,
"isProgrammer": false,
"friends": [...]
}]
}
Tag: Inference
SGLang
优势:后端运行快速、前端语言灵活、模型支持广泛、社区活跃。
SGLang 的核心是通过其 Python API 构建和执行 Language Model Program。
启动服务器
import sglang as sgl
# 配置 SGLang 运行时
# 如果在本地运行服务,这里指定服务地址和端口
# 如果直接在 Python 进程中加载模型 (需要安装 sglang[srt]),可以使用 sgl.init("model_path")
# 假设此时服务已在本地 30000 端口启动,并加载了模型:
sgl.init("http://127.0.0.1:30000")
# 或者,如果在 Python 进程中直接加载模型(需要足够的显存)
# sgl.init("meta-llama/Llama-3.1-8B-Instruct") # 使用 Hugging Face ID
# 或者
# sgl.init("/path/to/your/model_dir") # 使用本地模型路径
定义和运行一个简单的生成任务
sgl.Runtime()是 LM 程序的入口。import sglang as sgl # 假设已经通过 sgl.init(...) 初始化了运行时 # 定义一个 LM Program @sgl.function def simple_gen(s, query): s += f"用户问:{query}\n" # 使用 sgl.gen() 进行文本生成 s += "回答:" + sgl.gen("answer", max_tokens=64) # 使用 sgl.gen() 进行文本生成
vLLM
vLLM 是一个专门用于高效运行大语言模型的 Python 库。
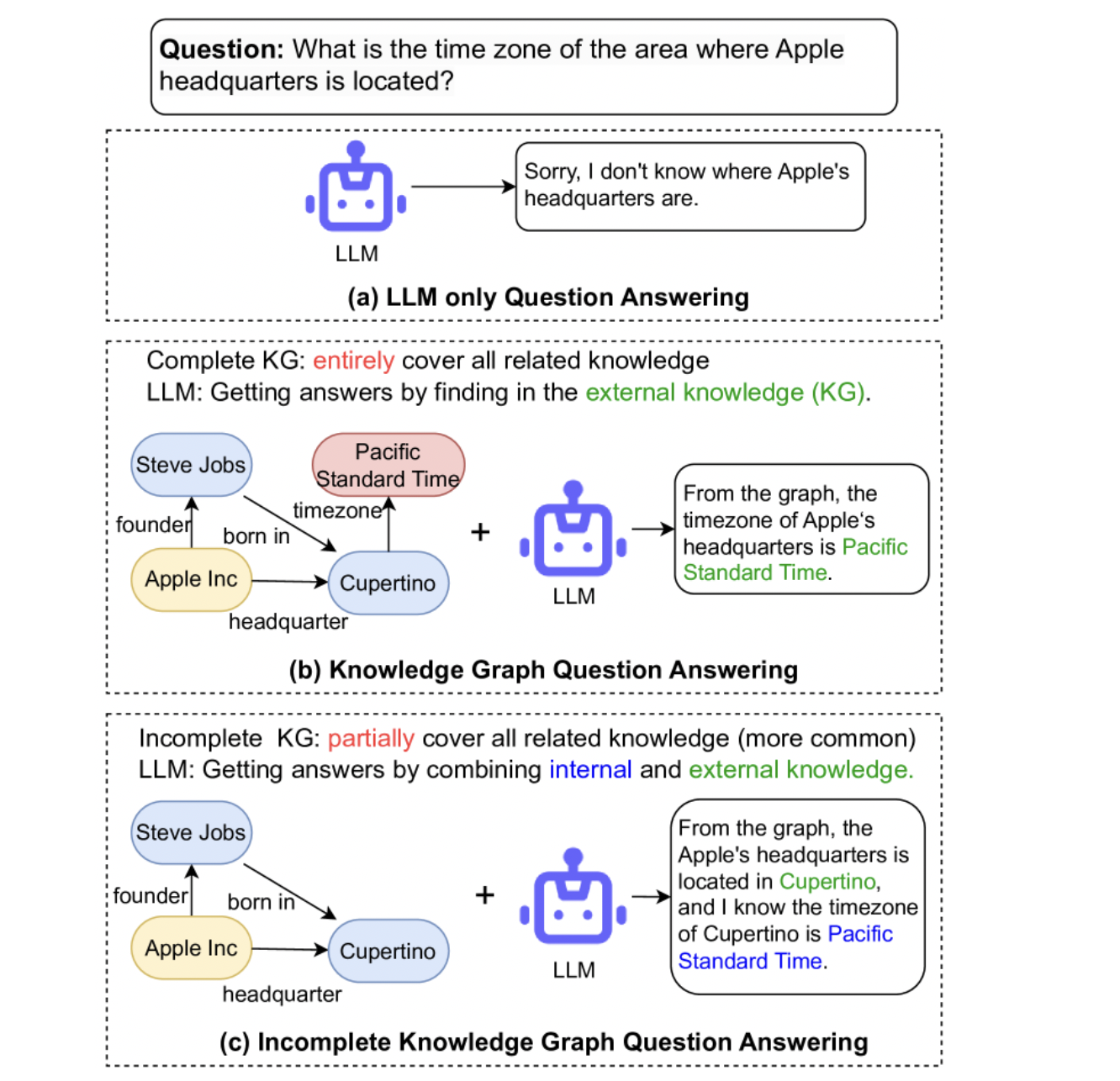
KV Cache
大模型推理时 huggingface 按照可生成最长序列长度分配显存。但这造成三种类型的浪费:
- 预分配最大的 token 数,但不会用到。
- 剩下的 token 还尚未用到,但现存已被预分配占用。
- 显存之间的间隔碎片,因为 prompt 之间不同,显存不足以预分配给下一个文本生成。
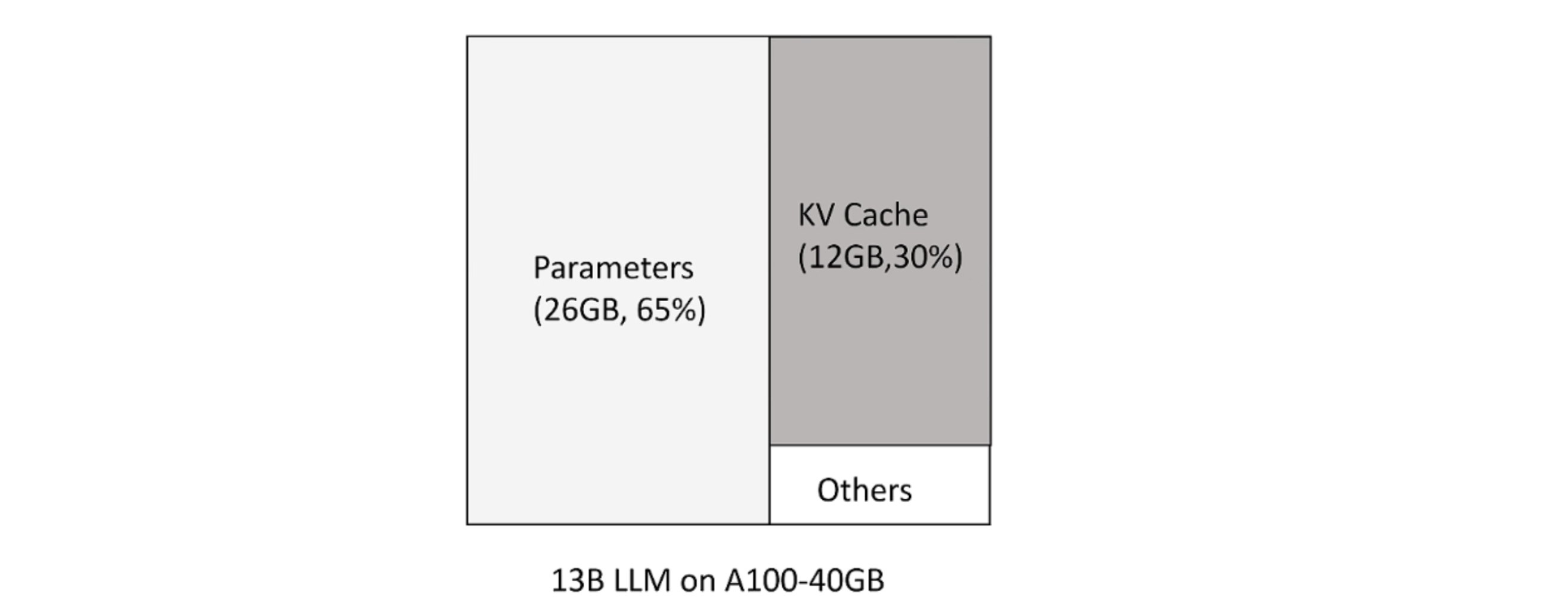
新 token 只用到前面 token 的 kv 向量,事实上只需保存之前的 kv 向量。
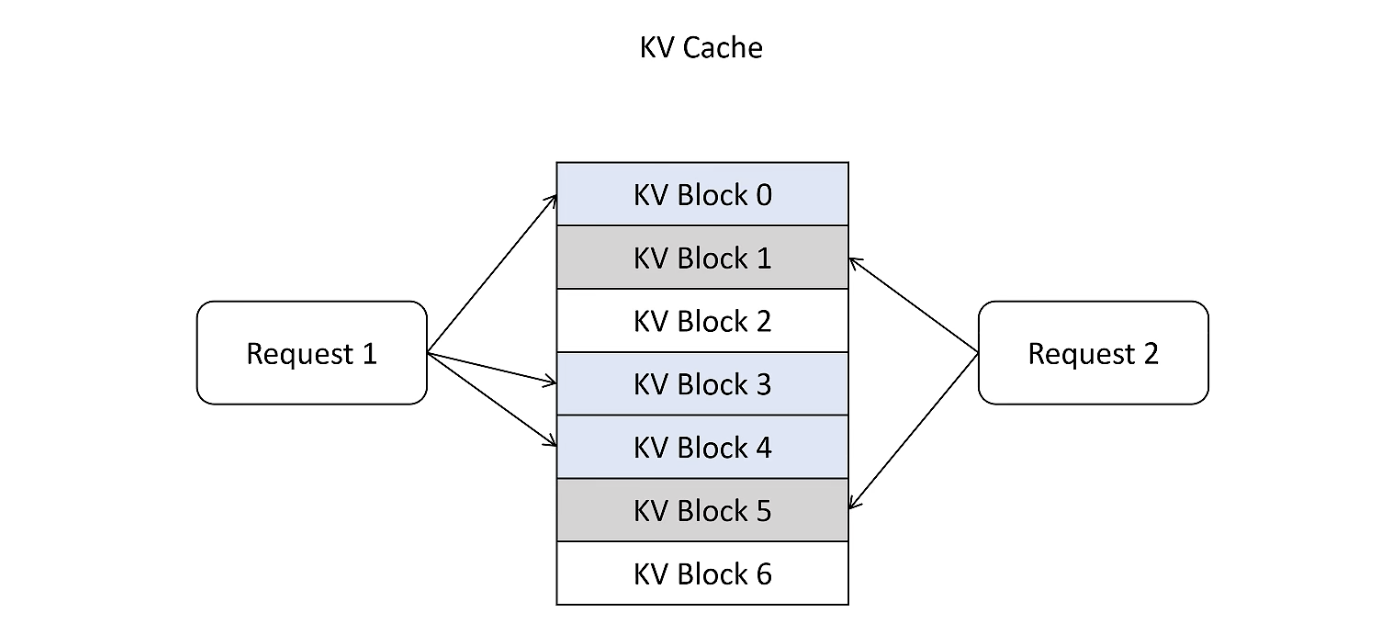
Page Attention
借鉴 OS 中的虚拟内存和页管理技术,把显存划分为 KVBlock,显存按照 KVBlock 来管理 KVCache,不用提前分配。
Tag: AI Infra
分布式并行训练 - FSDP
Fully Sharded Data Parallel
DDP 回顾
名词解释
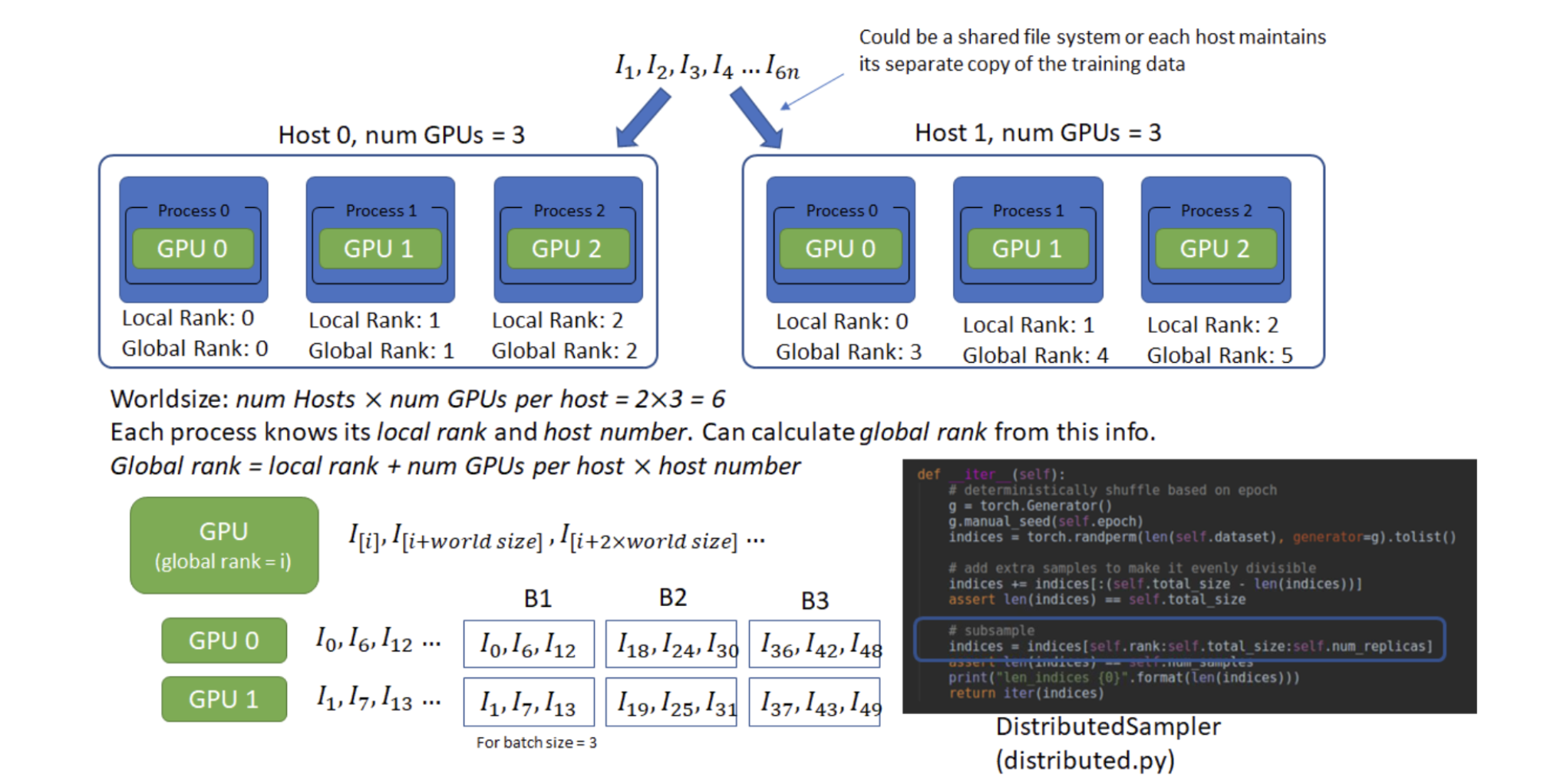
Host:可以理解为⼀台主机,每个主机有⾃⼰的IP地址,⽤于通信。
Local Rank:每个主机上,对不同GPU设备的编。
Global Rank:全局的GPU设备编号,Global Rank = Host * num GPUs per host + Local Rank。
Worldsize:总的GPU个数。num Hosts * num GPUs per host
DDP 参数更新过程
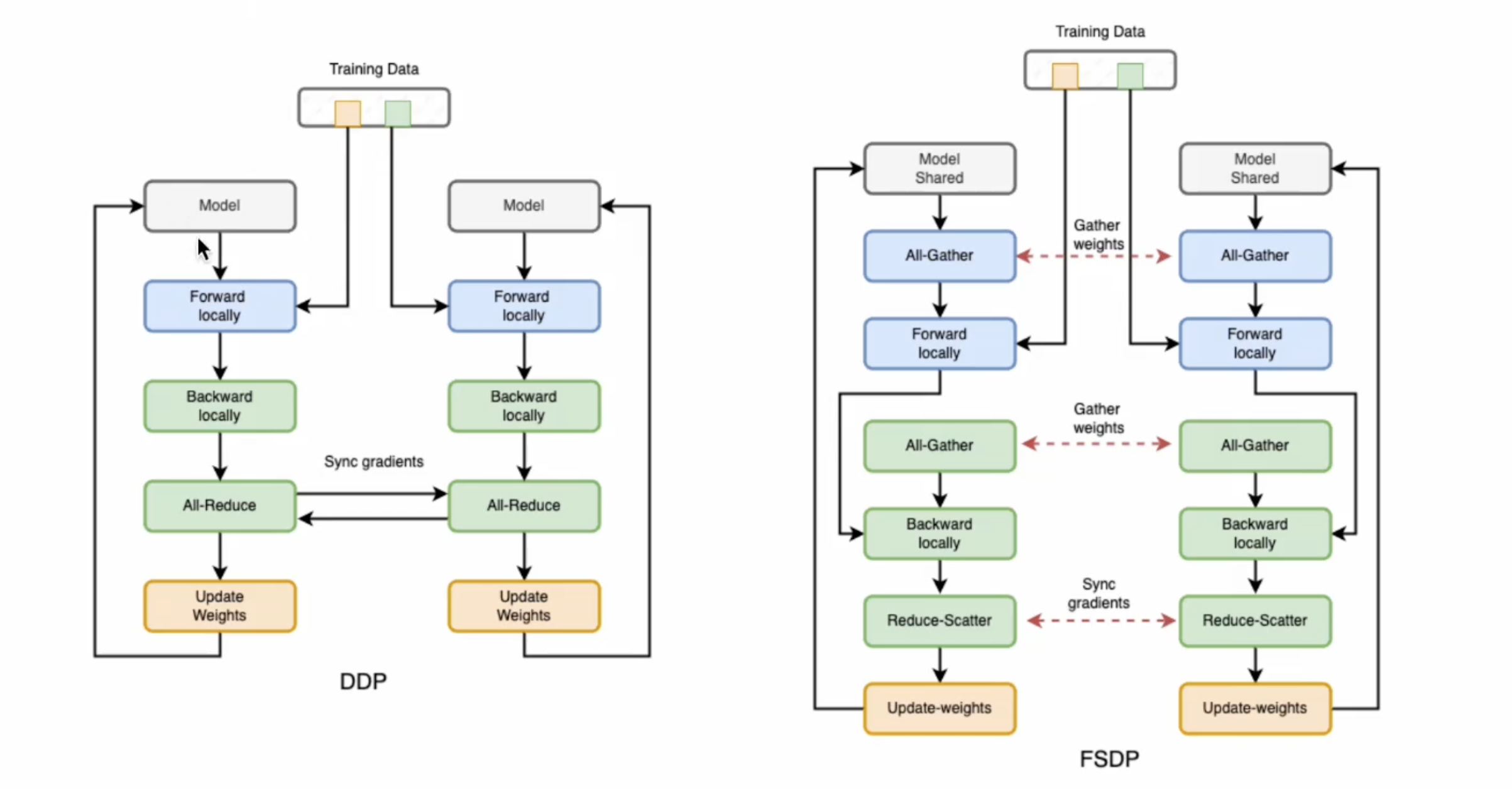
分布式并行训练 - DDP
分布式训练将训练工作负载分散到多个工作节点,因此可以显著提高训练速度和模型准确性。
Distributed Data Parallel
- 为什么用 Distributed Training? 节约时间、增加计算量、模型更快。
- 如何实现?
- 在同一机器上使用多个 GPUs
- 在集群上使用多个机器
什么是DDP?
即在训练过程中内部保持同步:每个 GPU 进程仅数据不同。
模型在所有设备上复制。DistributedSampler 确保每个设备获得不重叠的输入批次,从而处理 n 倍数据。

模型接受不同输入的数据后,在本地运行前向传播和后向传播。
pytorch 基础
数据
PyTorch 有两个用于处理数据的基元: torch.utils.data.DataLoader 和 torch.utils.data.Dataset
Dataset 存储样本及其相应的标签,DataLoader 则将一个可迭代对象封装在 Dataset 周围
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
PyTorch 提供特定于域的库,例如 TorchText、TorchVision 和 TorchAudio,所有这些库都包含数据集。以 TorchVision) 中的 FashionMNIST 数据集为例:
每个 TorchVision Dataset 都包含两个参数:transform 和 target_transform,分别用于修改样本和标签:
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
Tag: Pytorch
分布式并行训练 - FSDP
Fully Sharded Data Parallel
DDP 回顾
名词解释
Host:可以理解为⼀台主机,每个主机有⾃⼰的IP地址,⽤于通信。
Local Rank:每个主机上,对不同GPU设备的编。
Global Rank:全局的GPU设备编号,Global Rank = Host * num GPUs per host + Local Rank。
Worldsize:总的GPU个数。num Hosts * num GPUs per host
DDP 参数更新过程
分布式并行训练 - DDP
分布式训练将训练工作负载分散到多个工作节点,因此可以显著提高训练速度和模型准确性。
Distributed Data Parallel
- 为什么用 Distributed Training? 节约时间、增加计算量、模型更快。
- 如何实现?
- 在同一机器上使用多个 GPUs
- 在集群上使用多个机器
什么是DDP?
即在训练过程中内部保持同步:每个 GPU 进程仅数据不同。
模型在所有设备上复制。DistributedSampler 确保每个设备获得不重叠的输入批次,从而处理 n 倍数据。
模型接受不同输入的数据后,在本地运行前向传播和后向传播。
pytorch 基础
数据
PyTorch 有两个用于处理数据的基元: torch.utils.data.DataLoader 和 torch.utils.data.Dataset
Dataset 存储样本及其相应的标签,DataLoader 则将一个可迭代对象封装在 Dataset 周围
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
PyTorch 提供特定于域的库,例如 TorchText、TorchVision 和 TorchAudio,所有这些库都包含数据集。以 TorchVision) 中的 FashionMNIST 数据集为例:
每个 TorchVision Dataset 都包含两个参数:transform 和 target_transform,分别用于修改样本和标签:
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
Tag: AIInfra
Tag: ML
machine learning
好久没碰又忘了…😣 复习复习!!!
logistic 逻辑回归模型
1. sigmoid function (logistic function)
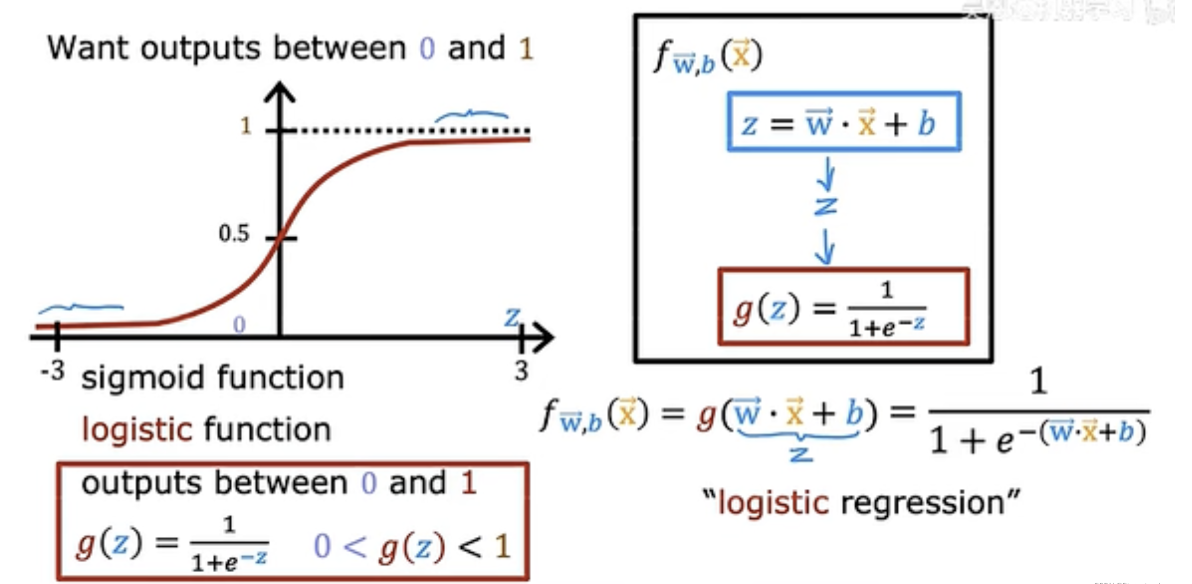
输出$f_{w,b}(x) = P(y=1|x;w,b)$:y 等于 1 的概率
[!NOTE]
如何理解?
When is $f_{w,b}(x) ≥ 0.5$
g(z) ≥ 0.5
z ≥ 0
w*x + b ≥ 0
决策边界: z = w*x+b = 0
Tag: Agent
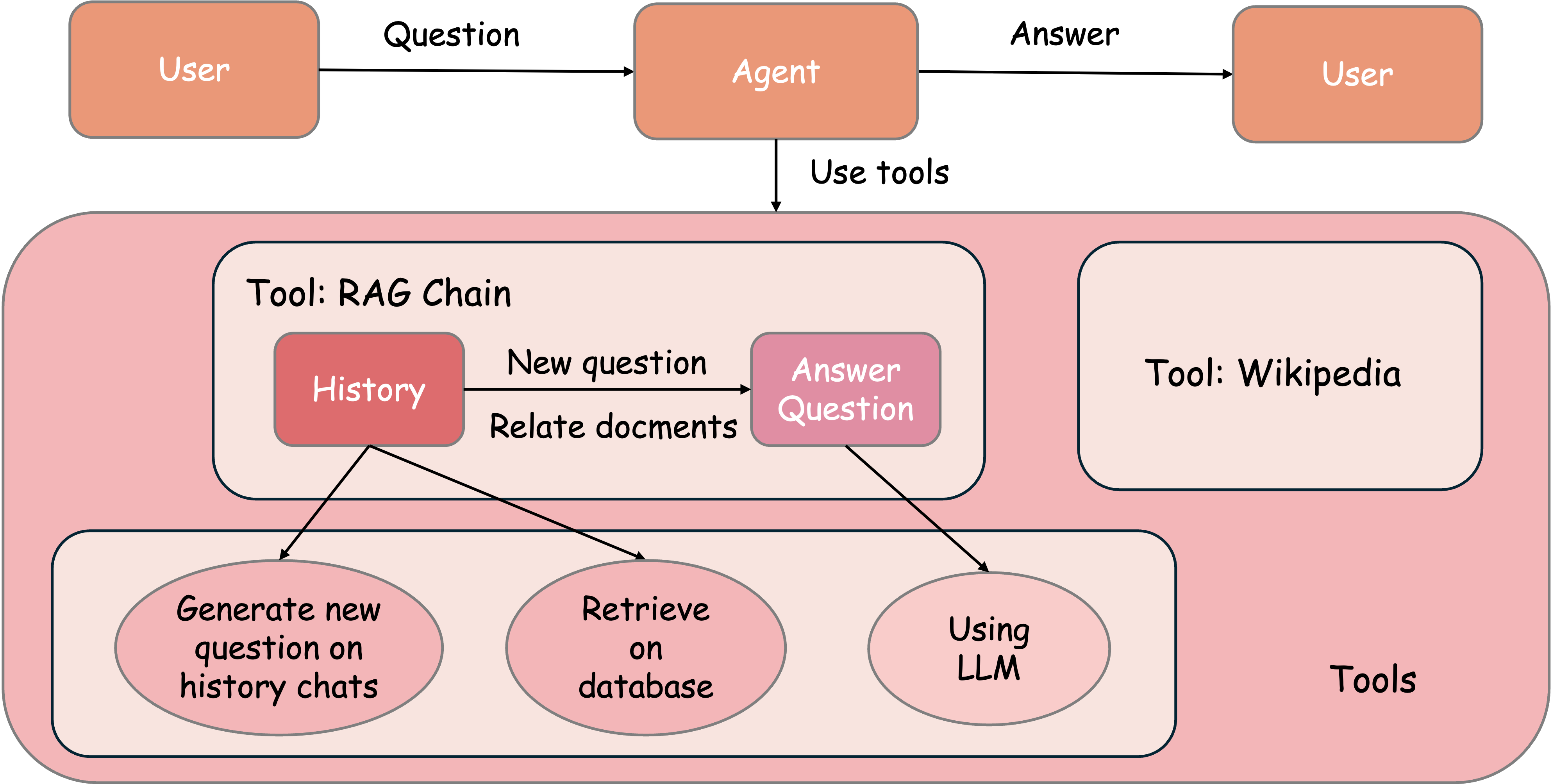
dify - Agent
基础实现
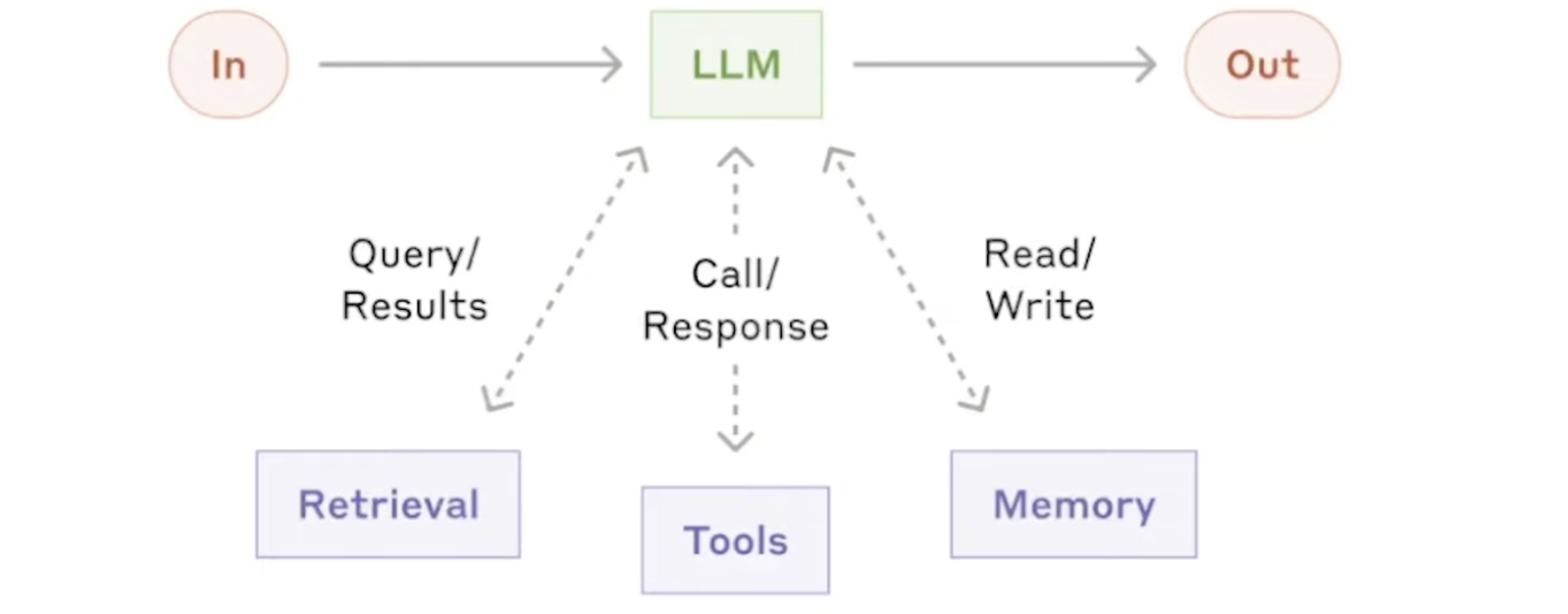
举例:WikiAgent
prompt
***xmi ‹instruction> - The Al Agent should be knowledgeable about the TV show "The Office". - If the question asked is not related to "The Office" or if the Al does not know the answer, it should search for the answer using the Google search tool. - The output should not contain any XML tags. <example> - If asked "Who is the regional manager in 'The Office'?", the Al should provide the correct answer. - If asked "What year did 'The Office' first premiere?", the Al should provide the correct answer or search for it if unknown.
Agent Workflow
Prompt Chaining
将任务分解为关键步骤,用gate来验证前面的输出是否符合后续处理的条件。
Tag: LLM
dify - Agent
基础实现
举例:WikiAgent
prompt
***xmi ‹instruction> - The Al Agent should be knowledgeable about the TV show "The Office". - If the question asked is not related to "The Office" or if the Al does not know the answer, it should search for the answer using the Google search tool. - The output should not contain any XML tags. <example> - If asked "Who is the regional manager in 'The Office'?", the Al should provide the correct answer. - If asked "What year did 'The Office' first premiere?", the Al should provide the correct answer or search for it if unknown.
Agent Workflow
Prompt Chaining
将任务分解为关键步骤,用gate来验证前面的输出是否符合后续处理的条件。
langchain - 混合搜索
先通过BM25快速筛选关键字,再用Reranker对候选文档进行精细排序。
def keyword_and_reranking_search(query, top_k=3, num_candidates=10):
print("Input question:", query)
##### BM25 search (lexical search) #####
bm25_scores = bm25.get_scores(bm25_tokenizer(query))
top_n = np.argpartition(bm25_scores, -num_candidates)[-num_candidates:] # 选取分数最高的 num_candidates 个文档
bm25_hits = [{'corpus_id': idx, 'score': bm25_scores[idx]} for idx in top_n]
bm25_hits = sorted(bm25_hits, key=lambda x: x['score'], reverse=True)
print(f"Top-3 lexical search (BM25) hits")
for hit in bm25_hits[0:top_k]:
print("\t{:.3f}\t{}".format(hit['score'], texts[hit['corpus_id']].replace("\n", " ")))
#Add re-ranking
docs = [texts[hit['corpus_id']] for hit in bm25_hits]
print(f"\nTop-3 hits by rank-API ({len(bm25_hits)} BM25 hits re-ranked)")
results = co.rerank(query=query, documents=docs, top_n=top_k, return_documents=True)
for hit in results.results:
print("\t{:.3f}\t{}".format(hit.relevance_score, hit.document.text.replace("\n", " ")))
bm25
基于词频和逆文档频率,计算每个文档与查询的关键词匹配分数。

Prompting Guide
可以在 langchainhub 上找 prompt
1. Agentic Workflows
System Prompt Reminders
在提示中包含三种关键类型的提醒:
持久性
确保模型理解它正在进入多消息轮次,并防止它过早地将控制权交还给用户。示例如下:
You are an agent - please keep going until the user’s query is completely resolved, before ending your turn and yielding back to the user. Only terminate your turn when you are sure that the problem is solved.工具调用
鼓励模型充分利用其工具,并降低其产生幻觉或猜测答案的可能性。示例如下:
If you are not sure about file content or codebase structure pertaining to the user’s request, use your tools to read files and gather the relevant information: do NOT guess or make up an answer.规划 [可选]
可确保模型在文本中明确规划和反映每个工具调用,而不是通过将一系列单独的工具调用链接在一起来完成任务。示例如下:


LLM - 3.指令理解阶段(核心) - 指令微调

指令微调又称有监督微调,旨在使模型具备指令遵循 (Instruction Following)能力。
核心问题:如何构造指令数据?如何高效低成本地进行指令微调训练?如何在语言模型基础上进一步扩大上下文?


BERT
名字来源:美国的一个动画片芝麻街里的主人公
论文:https://arxiv.org/abs/1810.04805
NLP 里的迁移学习
在 bert 之前:使用预训练好的模型来抽取词、句子的特征
- 如用 word2vec 或 语言模型(当作embedding层)
- 不更新预训练好的模型
- 缺点
- 需要构建新的网络来抓取新任务需要的信息
- Word2vec 忽略了时序信息,语言模型只看了一个方向
bert 的动机
基于微调的 NLP 模型
前面的层不用动,改最后一层的 output layer 即可
预训练的模型抽取了足够多的信息,新的任务只需要增加一个简单的输出层
BERT 架构
本质:一个砍掉解码器、只有编码器的 transformer
bert 的工作:证明了效果非常好
两个版本:
Base: #blocks=12, hidden size=768, #heads=12, #parameters=110M
Large: #blocks=24, hidden size=1024, #heads=1, #parameter=340M
在大规模数据上训练>3B词
微调
大模型预训练
1 从零开始的预训练
2 在已有开源模型基础上针对特定任务进行训练
LoRa
通过化简权重矩阵,实现高效微调

将loraA与loraB相乘得到一个lora权重矩阵,将lora权重矩阵加在原始权重矩阵上,就得到了对原始网络的更新。
训练参数量减少,但微调效果基本不变。
两个重要参数:

MLLM
1基础
1. 特征提取
一、CV中的特征提取
1. 传统方法(手工设计特征)
(1) 低级视觉特征:颜色、纹理、 边缘与形状…
(2) 中级语义特征:SIFT(尺度不变特征变换)、SURF(加速鲁棒特征)、LBP(局部二值模式)…
2. 深度学习方法(自动学习特征)
(1) 卷积神经网络(CNN)
核心思想:通过卷积层提取局部特征,池化层降低维度,全连接层进行分类。
经典模型:LeNet-5、AlexNet、VGGNet、ResNet(使用残差可以训练更深的网络)…

(2) 视觉Transformer(ViT)
- 核心思想:将图像分割为小块(patches),通过自注意力机制建模全局关系。
- 优势:无需局部卷积先验,直接建模长距离依赖; 在ImageNet等任务上超越传统CNN。
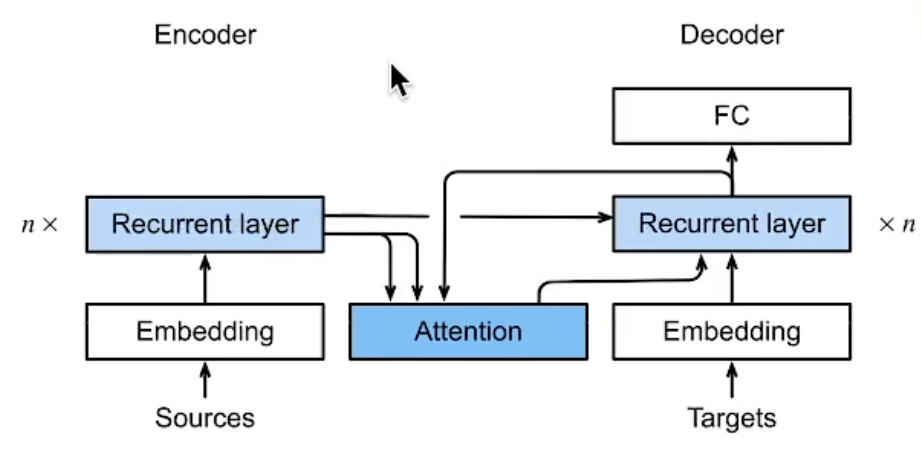
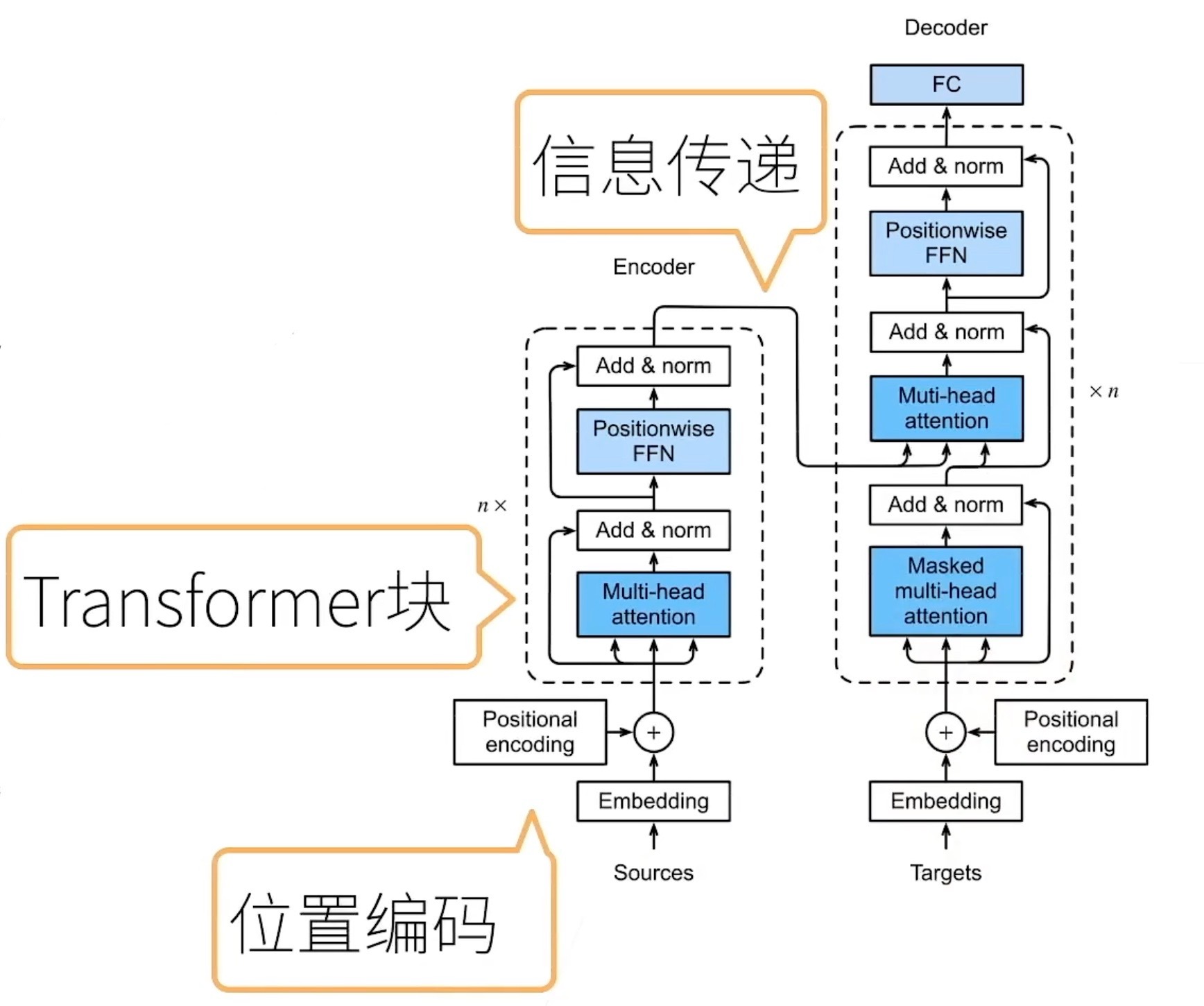
transformer
一、Transformer架构
基于编码器-解码器架构来处理序列对
跟使用注意力的seq2seq不同,Transformer是纯基于注意力
seq2seq
transformer
Tag: Langchain
langchain - 混合搜索
先通过BM25快速筛选关键字,再用Reranker对候选文档进行精细排序。
def keyword_and_reranking_search(query, top_k=3, num_candidates=10):
print("Input question:", query)
##### BM25 search (lexical search) #####
bm25_scores = bm25.get_scores(bm25_tokenizer(query))
top_n = np.argpartition(bm25_scores, -num_candidates)[-num_candidates:] # 选取分数最高的 num_candidates 个文档
bm25_hits = [{'corpus_id': idx, 'score': bm25_scores[idx]} for idx in top_n]
bm25_hits = sorted(bm25_hits, key=lambda x: x['score'], reverse=True)
print(f"Top-3 lexical search (BM25) hits")
for hit in bm25_hits[0:top_k]:
print("\t{:.3f}\t{}".format(hit['score'], texts[hit['corpus_id']].replace("\n", " ")))
#Add re-ranking
docs = [texts[hit['corpus_id']] for hit in bm25_hits]
print(f"\nTop-3 hits by rank-API ({len(bm25_hits)} BM25 hits re-ranked)")
results = co.rerank(query=query, documents=docs, top_n=top_k, return_documents=True)
for hit in results.results:
print("\t{:.3f}\t{}".format(hit.relevance_score, hit.document.text.replace("\n", " ")))
bm25
基于词频和逆文档频率,计算每个文档与查询的关键词匹配分数。
langchain - text_splitter
import os
from langchain.text_splitter import (
CharacterTextSplitter,
RecursiveCharacterTextSplitter,
SentenceTransformersTokenTextSplitter,
TextSplitter,
TokenTextSplitter,
)
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Define the directory containing the text file
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir, "books", "romeo_and_juliet.txt")
db_dir = os.path.join(current_dir, "db")
# Check if the text file exists
if not os.path.exists(file_path):
raise FileNotFoundError(
f"The file {file_path} does not exist. Please check the path."
)
# Read the text content from the file
loader = TextLoader(file_path)
documents = loader.load()
langchain - RAG

import os
from dotenv import load_dotenv
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import Chroma
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Load environment variables from .env
load_dotenv()
# Define the persistent directory
current_dir = os.path.dirname(os.path.abspath(__file__))
persistent_directory = os.path.join(current_dir, "db", "chroma_db_with_metadata")
Tag: LLM"
langchain - text_splitter
import os
from langchain.text_splitter import (
CharacterTextSplitter,
RecursiveCharacterTextSplitter,
SentenceTransformersTokenTextSplitter,
TextSplitter,
TokenTextSplitter,
)
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Define the directory containing the text file
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir, "books", "romeo_and_juliet.txt")
db_dir = os.path.join(current_dir, "db")
# Check if the text file exists
if not os.path.exists(file_path):
raise FileNotFoundError(
f"The file {file_path} does not exist. Please check the path."
)
# Read the text content from the file
loader = TextLoader(file_path)
documents = loader.load()
langchain - RAG
import os
from dotenv import load_dotenv
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import Chroma
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Load environment variables from .env
load_dotenv()
# Define the persistent directory
current_dir = os.path.dirname(os.path.abspath(__file__))
persistent_directory = os.path.join(current_dir, "db", "chroma_db_with_metadata")
Tag: Agent"
Tag: Book
「书籍阅读」《贪婪的多巴胺》利伯曼
- 魅力创造了不能被满足的欲望,因为这种欲望的对象只存在于想象之中。魅力就是一个谎言。
未来不是真实的,它由一系列只存在于我们大脑中的可能性组成。这些可能性往往过于理想化,因为我们通常不会想象一个平庸的结果。在所有可能的世界中,我们倾向于考虑最好的那一个,这使得未来更具吸引力。
而当未来变成了现在,兴奋、热情和充满精力的感觉消散了,多巴胺停止工作了。这样很多人感到失望,他们过于依附于多巴胺能的刺激,让自己逃离了现在,躲在自己想象的舒适世界里。“明天我们做什么?”他们一边咀嚼食物一边问自己,忘记了——他们也曾热切期待着这顿饭,但现在却对它视而不见。充满希望的旅途要比到达目的地更快乐。
「书籍阅读」《鼠疫》加缪
怎么做才能不浪费时间?
在时间的漫长中体验时间。
一场战争爆发时,人们说:“这仗打不长,因为那太愚蠢了。”毫无疑问,战争的确太愚蠢,然而愚蠢并不妨碍它打下去。倘若人不老去想自己,他会发觉蠢事有可能一直坚持干下去。在这方面,他们和大家一样,他们想的是他们自己,他们都是人本主义者:他们不相信天灾。天灾怎么能和人相比!因此大家想,这灾祸不是现实,它只是一场噩梦,很快就会过去。
然而,噩梦不一定会消逝,它们一个接着一个,其间逝去的却是人,首先是那些人本主义者,因为那些人没有采取预防措施。他们的过失并非比别人严重,他们忘记了人应当谦虚,如此而已。
Tag: RAG"
RAG实践
RAG 整体框架
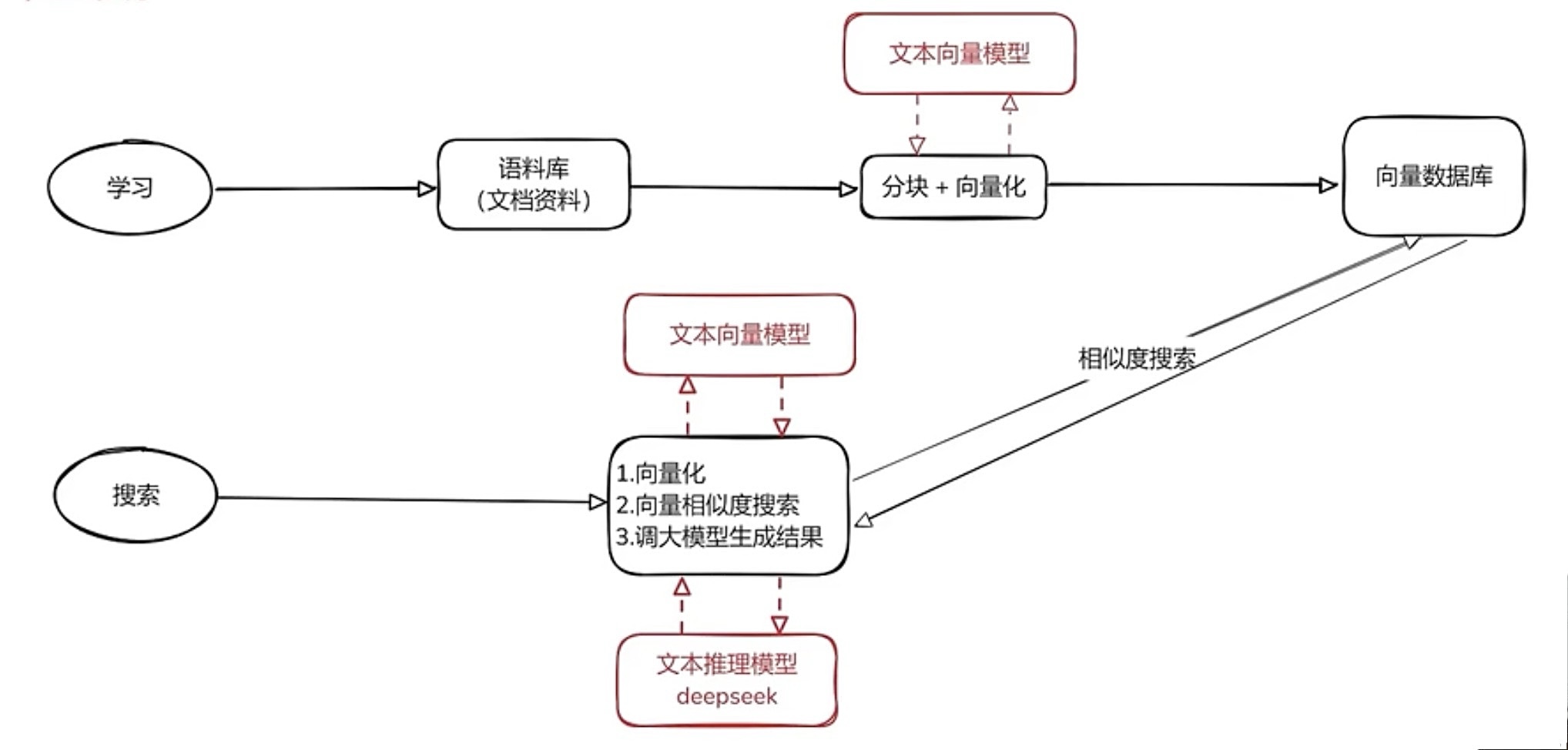
将语料库喂给LLM
- 文字分块向量化(利用LLM),从而基于向量相似度进行搜索
- 将得到的向量存储到向量数据库中
搜索
- 将用户问题进行向量化,在向量数据库中进行搜索,得到相关内容
- 将检索得到的相关内容(不一定相关)和关用户问题 一起传给 LLM
- LLM提取出相关信息,生成正确结果
LLM 常见参数
temperature
控制生成文本的随机性。温度越高,生成的文本越随机和创造性;温度越低,文本越趋向于确定性和重复性。
Tag: Tool
RAG实践
RAG 整体框架
将语料库喂给LLM
- 文字分块向量化(利用LLM),从而基于向量相似度进行搜索
- 将得到的向量存储到向量数据库中
搜索
- 将用户问题进行向量化,在向量数据库中进行搜索,得到相关内容
- 将检索得到的相关内容(不一定相关)和关用户问题 一起传给 LLM
- LLM提取出相关信息,生成正确结果
LLM 常见参数
temperature
控制生成文本的随机性。温度越高,生成的文本越随机和创造性;温度越低,文本越趋向于确定性和重复性。
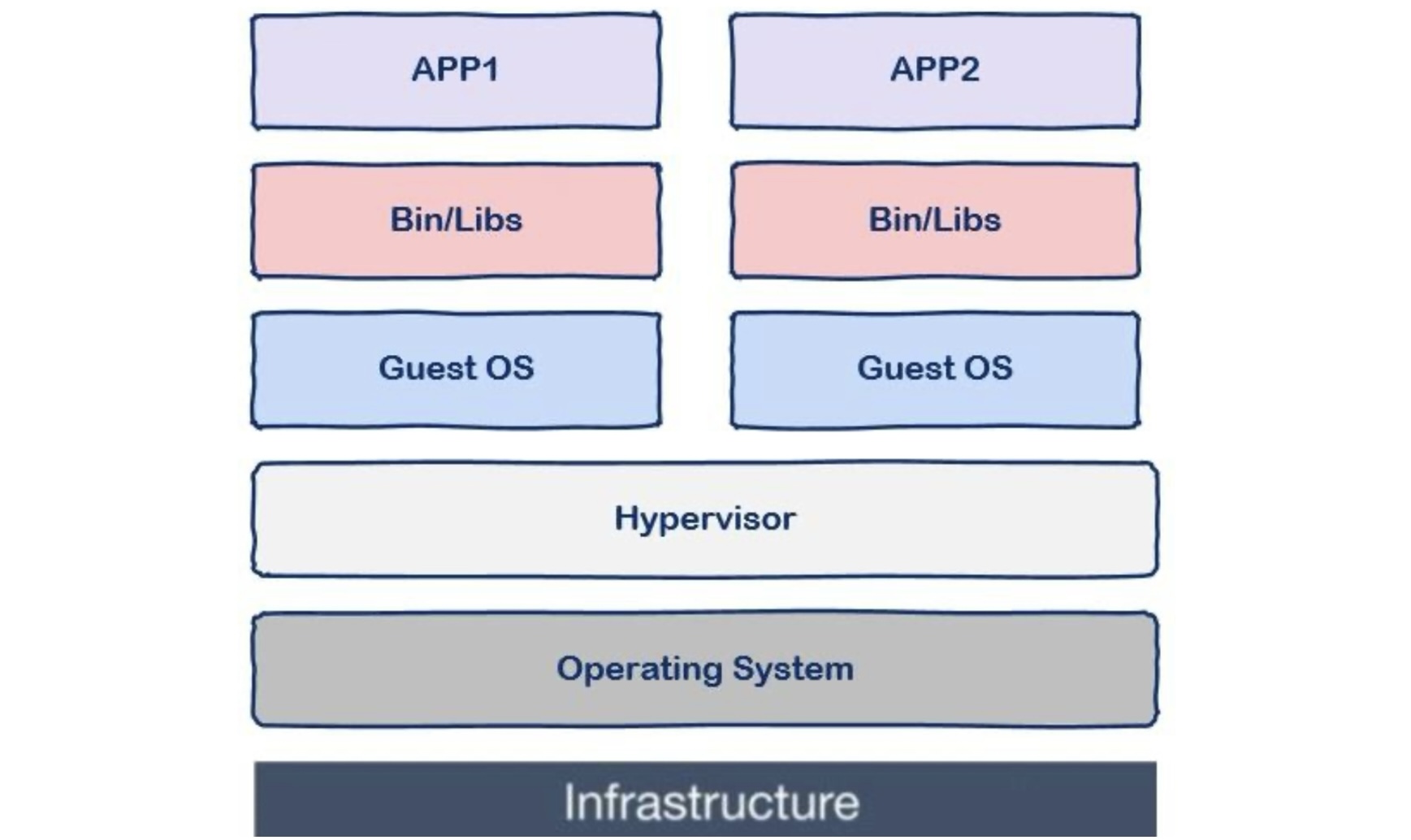
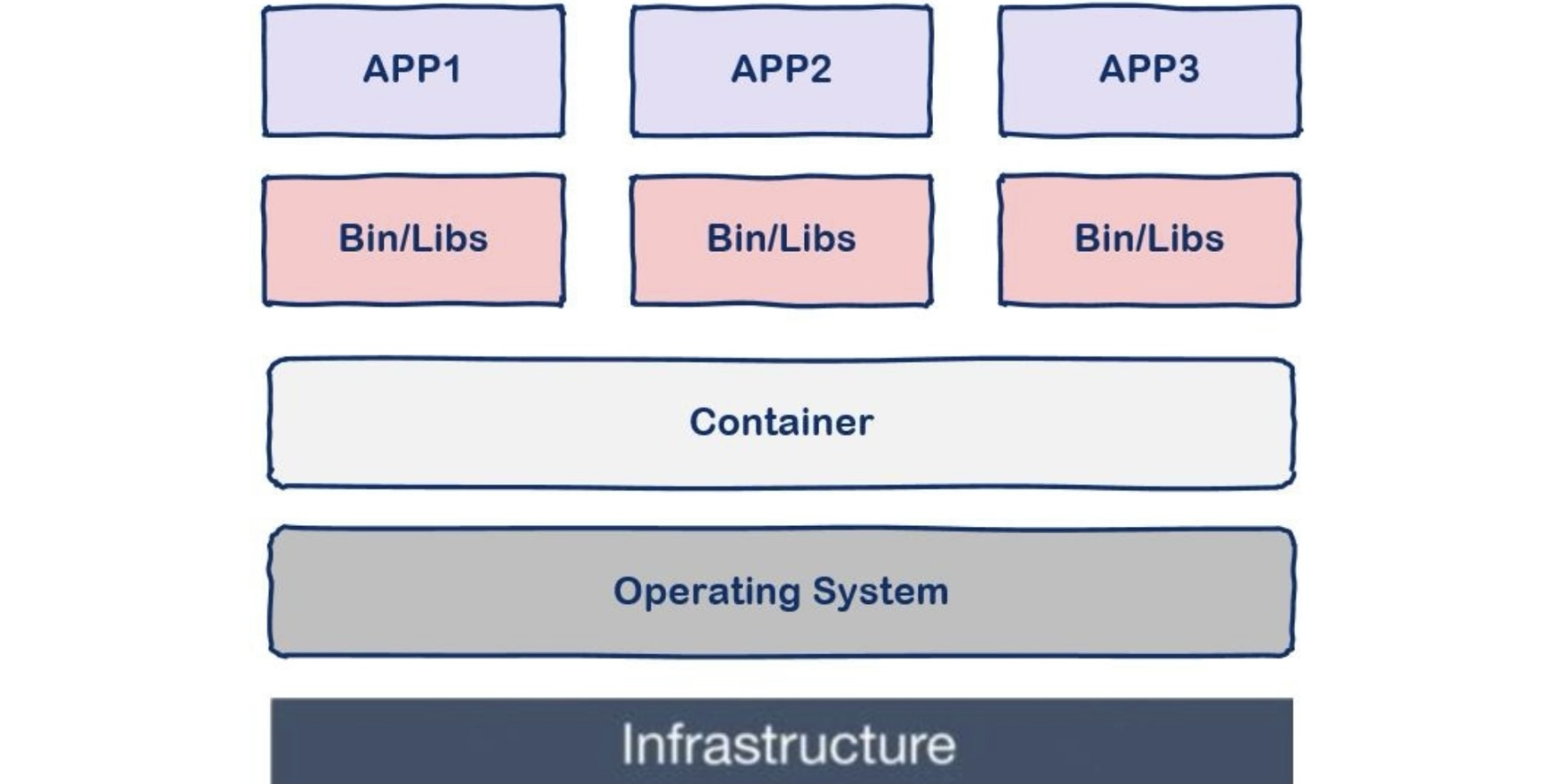
工具链-Carla
官方文档:https://carla.readthedocs.io/en/0.9.9/#getting-started
Carla是一款开源的 自动驾驶 仿真器,它基本可以用来帮助训练自动驾驶的所有模块,包括感知系统,Localization,规划系统等等。许多自动驾驶公司在进行实际路跑前都要在这Carla上先进行训练。
1. 基本架构
Client-Server 的交互形式
Carla主要分为Server与Client两个模块
工具链-PyTorch
1. 处理数据
PyTorch 有两个用于处理数据的基元: torch.utils.data.DataLoader 和 torch.utils.data.Dataset。
Dataset 存储样本及其相应的标签,DataLoader 将 Dataset 包装成一个迭代器。
下面以 TorchVision 库模块里的 FashionMNIST 数据集为例:
每个 TorchVision
Dataset都包含两个参数:transform和target_transform分别修改样本和标签
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
将 Dataset 作为参数传递给 DataLoader ,将一个可迭代对象包装在数据集上,支持自动批处理、采样、洗牌和多进程数据加载。
定义了一个 batch size 为 64,即 dataloader 迭代器中的每个元素将返回一个 64 features and labels 的 batch。
工具链-深度学习
Torch + CUDA + NVIDIA:
安装步骤:
去 Nvidia 官网下载 CUDA 并安装(核心:驱动+CUDA开发环境)
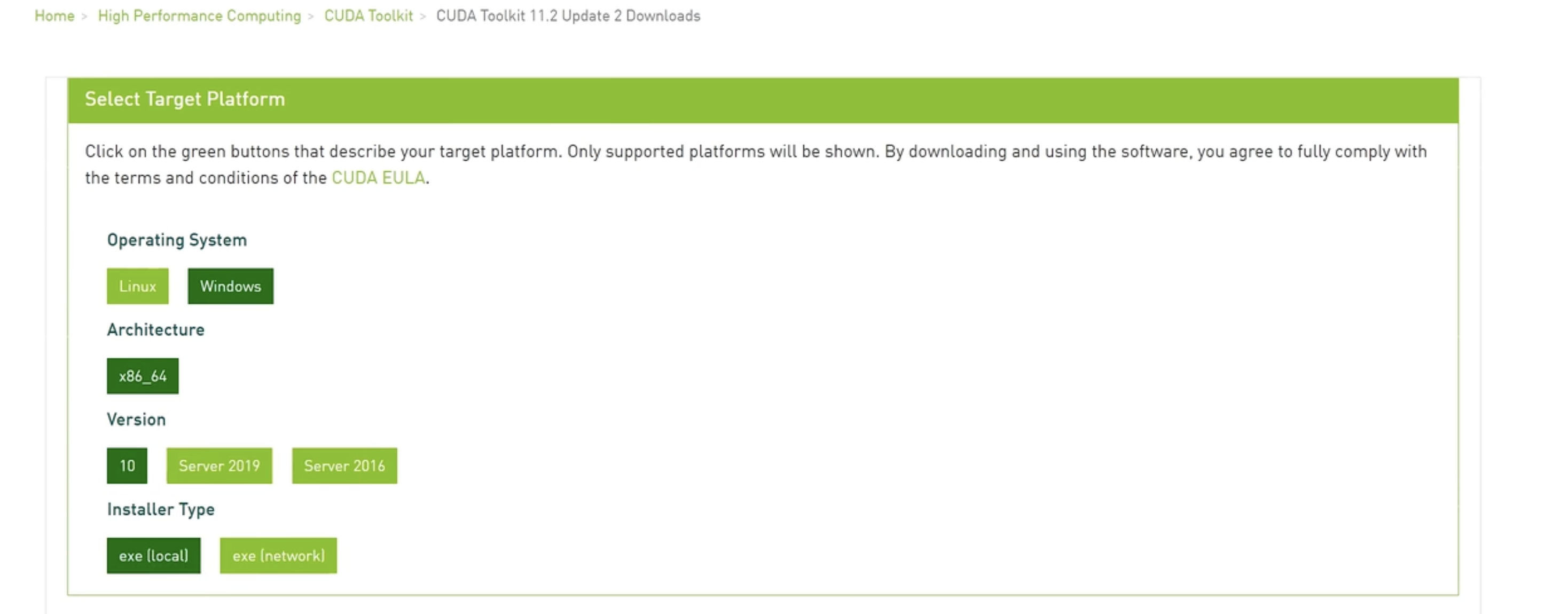
检查:
nvidia-smi指令下载 Anaconda,用于运行 python 环境
下载 GPU 版本的 pytorch

可以开始跑深度学习了!
Torch 是一个深度学习框架,用于构建和训练神经网络,该可以利用CUDA在NVIDIA GPU上加速计算。通过在PyTorch中指定使用CUDA进行训练,可以在处理大数据集时大大提高计算效率。
工具链-强化学习
1. gym
官方文档:https://www.gymlibrary.dev
最小例子
CartPole-v0import gymenv = gym.make('CartPole-v0') env.reset() for _ in range(1000): env.render() env.step(env.action_space.sample()) # take a random action
观测 (Observations)
在 Gym 仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据标志位 done 的状态,来决定是否进行下一次回合。代码表示:
env.step() 函数对每一步进行仿真,返回 4 个参数:
观测 Observation (Object):当前 step 执行后,环境的观测(类型为对象)。例如,从相机获取的像素点,机器人各个关节的角度或棋盘游戏当前的状态等;
奖励 Reward (Float): 执行上一步动作(action)后,智体(agent)获得的奖励,不同的环境中奖励值变化范围也不相同,但是强化学习的目标就是使得总奖励值最大;
完成 Done (Boolen): 表示是否需要将环境重置
env.reset。
Tag: Deep Learning
深度学习基础 - 激活函数和epoch, batch, iteration
写这篇文章有两个原因:一是因为我好久没看Activation Function又忘了,来复习一下;另一个是因为我想赶紧把这个风格的摄影作品用完,开启下一个系列 :)
引入激活函数的目的:加入非线性因素的,解决线性模型所不能解决的问题。通过最优化损失函数的做法,我们能够学习到不断学习靠近能够正确分类的曲线。
1 sigmoid 函数
sigmoid 函数是一个 logistic 函数:输入的每个神经元、节点或激活都会被缩放为一个介于 0 到 1 之间的值。
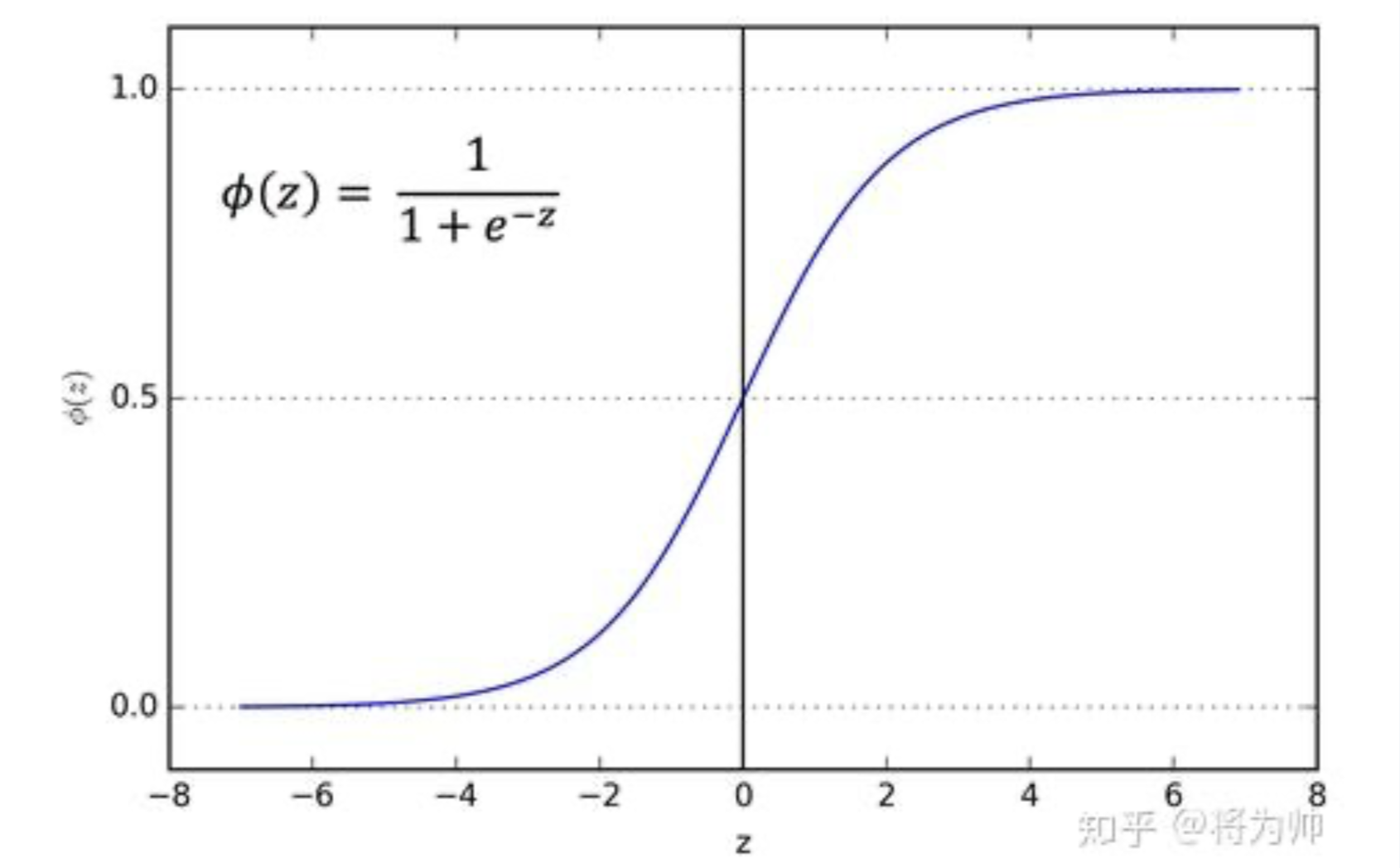
从图像可以看出,函数两个边缘的梯度约为0,梯度的取值范围为(0,0.25):
Quantization
线性量化
量化和去量化
量化指将一个大集合映射到一个较小值集合的过程。

可以量化的内容
- The weights: Neural network parameters
- The activations: Values that propagate through the layers of the neural network
目标检测
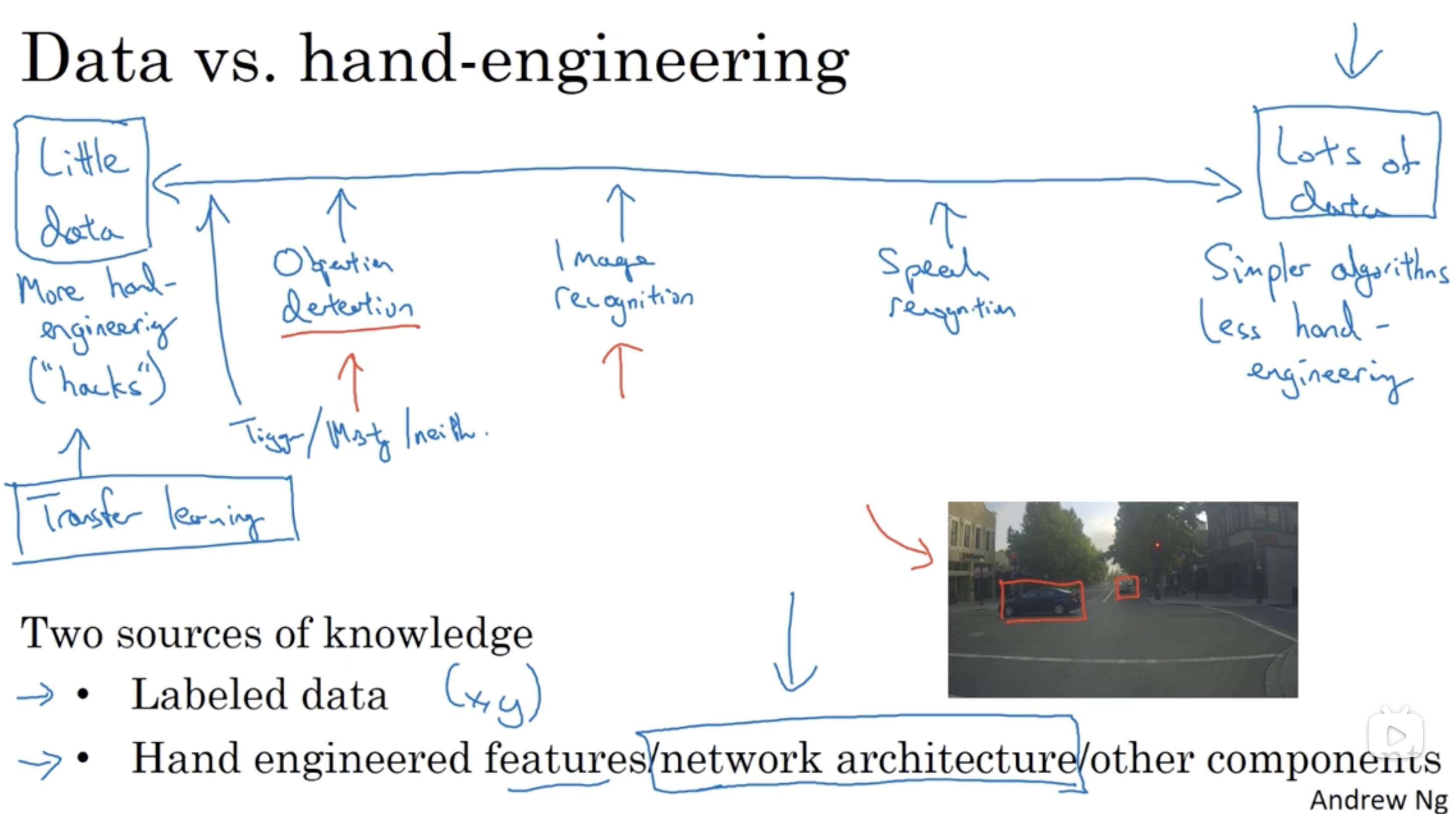
技巧
Ensembling:Train several networks independently and average their outputs Multi-crop at test time:Run classifier on multiple versions of test images and average results
定位
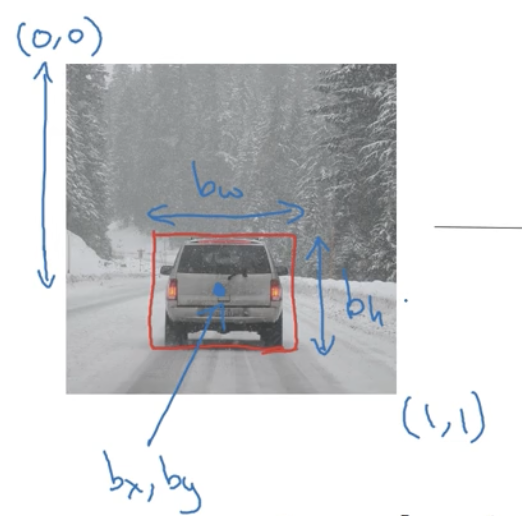
Need to output bx, by, bn, bw, class label (1-4)

需人工标注特征点的坐标
基于滑动窗口的目标检测算法
- 先训练卷积网络识别物体
- 滑动+放大窗口+再次滑动
问题:计算效率大,慢
Tag: Automatic Driving
工具链-Carla
官方文档:https://carla.readthedocs.io/en/0.9.9/#getting-started
Carla是一款开源的 自动驾驶 仿真器,它基本可以用来帮助训练自动驾驶的所有模块,包括感知系统,Localization,规划系统等等。许多自动驾驶公司在进行实际路跑前都要在这Carla上先进行训练。
1. 基本架构
Client-Server 的交互形式
Carla主要分为Server与Client两个模块
LSS代码
文章搬运,自用。
论文:Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
官方源码:lift-splat-shoot
Lift, Splat, Shoot图像BEV安装与模型代码详解
对于任意数量不同相机帧的图像直接提取场景的BEV表达;主要由三部分实现:
- Lift:将每一个相机的图像帧根据相机的内参转换提升到 frustum(锥形)形状的点云空间中。
- splate:将所有相机转换到锥形点云空间中的特征根据相机的内参 K 与相机相对于 ego 的外参T映射到栅格化的 3D 空间(BEV)中来融合多帧信息。
- shoot:根据上述 BEV 的检测或分割结果来生成规划的路径 proposal;从而实现可解释的端到端的路径规划任务。
注:LSS在训练的过程中并不需要激光雷达的点云来进行监督。
Tag: RL
工具链-Carla
官方文档:https://carla.readthedocs.io/en/0.9.9/#getting-started
Carla是一款开源的 自动驾驶 仿真器,它基本可以用来帮助训练自动驾驶的所有模块,包括感知系统,Localization,规划系统等等。许多自动驾驶公司在进行实际路跑前都要在这Carla上先进行训练。
1. 基本架构
Client-Server 的交互形式
Carla主要分为Server与Client两个模块
强化学习-发展趋势
1阶段
RL:一种解决马尔可夫决策过程的方法。
分类:value-based算法(DQN)和 policy-based算法(PPO)。
应用方向:多智能体强化学习, 安全强化学习等等。
2 阶段
强化学习应用的论文描述严格(必须有以下内容):
- 非常准确的状态空间和动作空间定义
- 必须存在状态转移函数,不允许单步决策,也就是一个动作就gameover
- 必须有过程奖励,且需要存在牺牲短期的过程奖励而获取最大累计回报的case案例
应用方向:游戏AI(份额不大)
3 阶段
RL 落地的真正难点在于问题的真实构建,而非近似构建或策略求解等等方面的问题。从原先任务只有求解策略的过程是强化学习,变成了 构建问题+求解策略 统称为强化学习。
典型如 offline model-based RL 和 RLHF,其中核心的模块变成了通过神经网络模拟状态转移函数和奖励函数,策略求解反而在方法论中被一句带过。
这个过程可以被解耦,变成跟强化学习毫无相关的名词概念,例如世界模型概念等。对于RL,没有有效的交互环境下的就没法达到目标,有这种有效交互环境的实际应用场景却非常少。
工具链-强化学习
1. gym
官方文档:https://www.gymlibrary.dev
最小例子
CartPole-v0import gymenv = gym.make('CartPole-v0') env.reset() for _ in range(1000): env.render() env.step(env.action_space.sample()) # take a random action
观测 (Observations)
在 Gym 仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据标志位 done 的状态,来决定是否进行下一次回合。代码表示:
env.step() 函数对每一步进行仿真,返回 4 个参数:
观测 Observation (Object):当前 step 执行后,环境的观测(类型为对象)。例如,从相机获取的像素点,机器人各个关节的角度或棋盘游戏当前的状态等;
奖励 Reward (Float): 执行上一步动作(action)后,智体(agent)获得的奖励,不同的环境中奖励值变化范围也不相同,但是强化学习的目标就是使得总奖励值最大;
完成 Done (Boolen): 表示是否需要将环境重置
env.reset。
PPO
1. 论文详读
Proximal Policy Optimization Algorithms(Proximal:近似)
2. PPO
回顾 TRPO
使用 KL 散度约束 policy 的更新幅度;使用重要性采样
缺点:近似会带来误差(重要性采样的通病);解带约束的优化问题困难
PPO 的改进
TRPO 采用重要性采样 —-> PPO 采用 clip 截断,限制新旧策略差异,避免更新过大。
优势函数 At 选用多步时序差分
自适应的 KL 惩罚项
Critic网络训练:
通过最小化
critic_loss = MSE(critic(states), td_target),让critic的价值估计更准确Actor网络更新:
- TD误差的广义形式(GAE)被用作优势函数,指导策略更新方向
- 优势函数越大,表示该动作比平均表现更好,应被加强
3. PPO-惩罚
PPO-惩罚(PPO-Penalty):用拉格朗日乘数法将 KL 散度的限制放进了目标函数中,使其变成了一个无约束的优化问题,在迭代的过程中不断更新 KL 散度前的系数 beta。
TRPO
基于策略的方法的缺点:当策略网络是深度模型时沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果。
信任区域策略优化(TRPO)算法的核心思想:
信任区域(trust region):在这个区域上更新策略时能够得到某种策略性能的安全性保证。
1. 策略目标


Actor-Critic
Actor-Critic 算法本质上是基于策略的算法,因为这一系列算法的目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好地学习。
Actor-Critic 算法则可以在每一步之后都进行更新,并且不对任务的步数做限制。
更一般形式的策略梯度

1. Actor(策略网络)
Actor 要做的是与环境交互,并在 Critic 价值函数的指导下用策略梯度学习一个更好的策略。
Actor 的更新采用策略梯度的原则。
2. Critic(价值网络)
Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于判断在当前状态什么动作是好的,什么动作不是好的,进而帮助 Actor 进行策略更新。
REINFORCE
Q-learning、DQN 算法都是基于价值(value-based)的方法
- Q-learning 是处理有限状态的算法
- DQN 可以用来解决连续状态的问题
在强化学习中,除了基于值函数的方法,还有一支非常经典的方法,那就是基于策略(policy-based)的方法。
对比 value-based 和 policy-based
- 基于值函数:主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;
- 基于策略:直接显式地学习一个目标策略。策略梯度是基于策略的方法的基础。
1. 策略梯度
将策略参数化:寻找一个最优策略并最大化这个策略在环境中的期望回报,即调整策略参数使平均回报最大化。
策略学习的目标函数

- J(θ) 是策略的目标函数(想要最大化的量);
- πθ 是参数为θ的随机性策略,并且处处可微(可以理解为AI的决策规则);
- Vπθ(s0) 指从初始状态s₀开始遵循策略π能获得的预期总回报;
- Es0 是对所有可能的初始状态求期望。
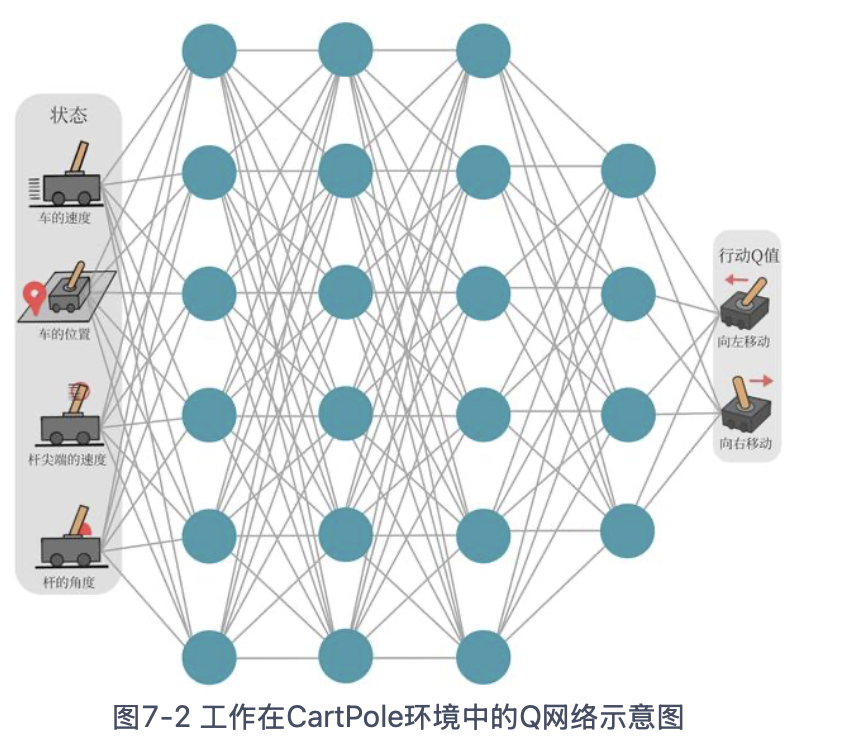
DQN (deep Q network)
Q-learning 算法用表格存储动作价值的做法只在 环境的状态和动作都是离散的,并且空间都比较小 的情况下适用.
DQN:用来解决连续状态下离散动作的问题,是离线策略算法,可以使用ε-贪婪策略来平衡探索与利用。
Q 网络:用于拟合函数Q函数的神经网络
Q 网络的损失函数(均方误差形式)
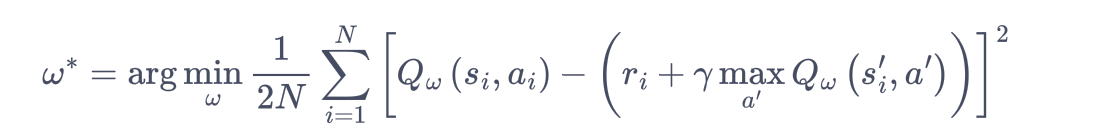
Q-learing
无模型的强化学习:不需要事先知道环境的奖励函数和状态转移函数,而是直接使用和环境交互的过程中采样到的数据来学习。
1. 时序差分方法
时序差分方法核心:对未来动作选择的价值估计来更新对当前动作选择的价值估计。
蒙特卡洛方法(Monte-Carlo methods)
使用重复随机抽样,然后运用概率统计方法来从抽样结果中归纳出我们想求的目标的数值估计。
用蒙特卡洛方法来估计一个策略在一个马尔可夫决策过程中的状态价值函数:用样本均值作为期望值的估计
- 在 MDP 上采样很多条序列,计算从这个状态出发的回报再求其期望
- 一条序列只计算一次回报,也就是这条序列第一次出现该状态时计算后面的累积奖励,而后面再次出现该状态时,该状态就被忽略了。
蒙特卡洛方法对价值函数的增量更新方式
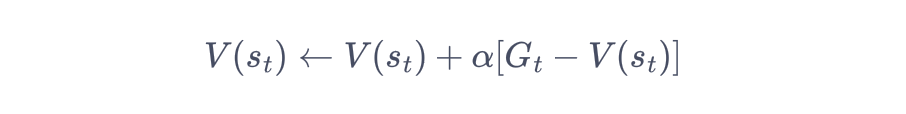
时序差分方法只需要当前步结束即可进行计算
强化学习-易混淆点
GAE 和优势函数
概念 说明 优势函数 A(s,a) Q(s,a)−V(s),衡量动作比平均情况好多少 广义优势估计 GAE 一种计算优势函数方法,用TD误差的加权和估计优势,超参数 λ 控制偏差-方差权衡
状态价值函数 vs 动作价值函数
状态价值函数

动作价值函数

优势函数
在状态 s 下选择动作 a 比平均情况(即遵循当前策略)好多少
A(s,a)=Q(s,a)−V(s)
- 求解优势函数:广义优势估计(GAE)
广义优势估计(GAE)
通过指数加权平均不同步长的优势估计(从1步到无穷步),结合γ和λ的幂次衰减,实现平滑的回报估计。

PPO-直观理解
1. 基础概念
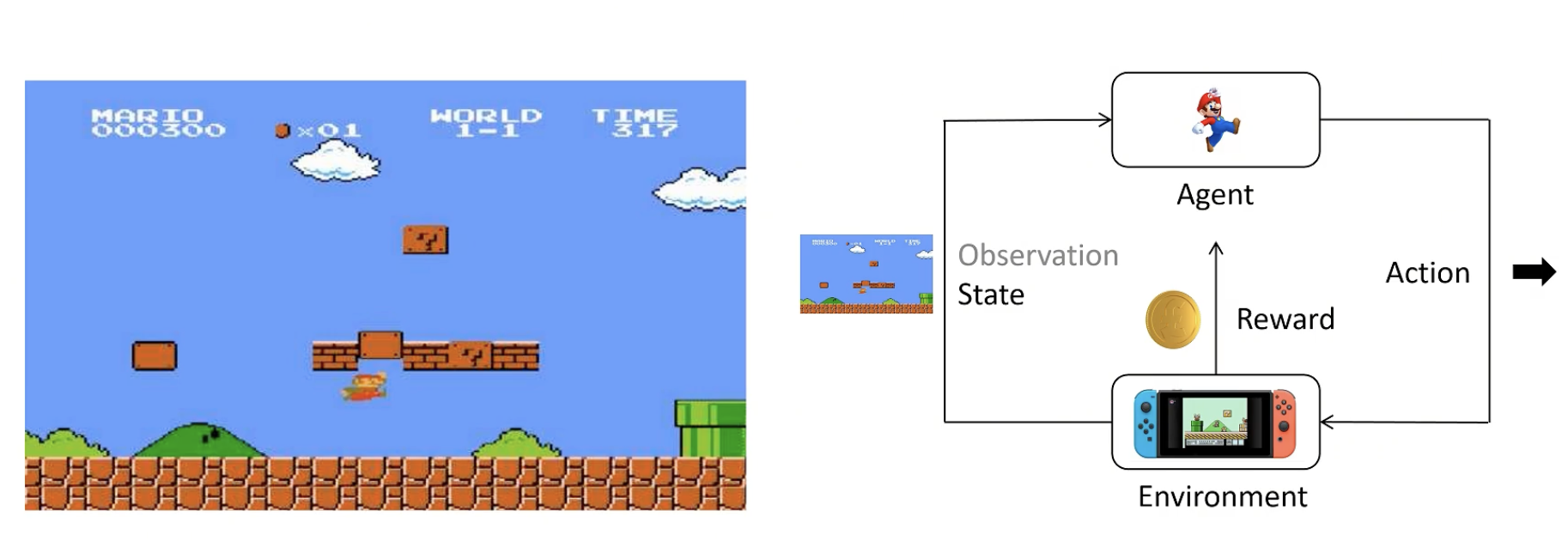
enviroment:看到的画面+看不到的后台画面,不了解细节
agent(智能体):根据策略得到尽可能多的奖励
state:当前状态
observation:state的一部分(有时候agent无法看全)
action:agent做出的动作
reward:agent做出一个动作后环境给予的奖励
action space:可以选择的动作,如上下左右
policy:策略函数,输入state,输出Action的概率分布。一般用π表示。
- 训练时应尝试各种action
- 输出应具有多样性
Trajectory/Episode/Rollout:轨迹,用 t 表示一连串状态和动作的序列。有的状态转移是确定的,也有的是不确定的。
Return:回报,从当前时间点到游戏结束的 Reward 的累积和。
强化学习目标:训练一个Policy神经网络π,在所有状态S下,给出相应的Action,得到Return的期望最大。
微调
大模型预训练
1 从零开始的预训练
2 在已有开源模型基础上针对特定任务进行训练
LoRa
通过化简权重矩阵,实现高效微调
将loraA与loraB相乘得到一个lora权重矩阵,将lora权重矩阵加在原始权重矩阵上,就得到了对原始网络的更新。
训练参数量减少,但微调效果基本不变。
两个重要参数:
强化学习-数学基础
总述
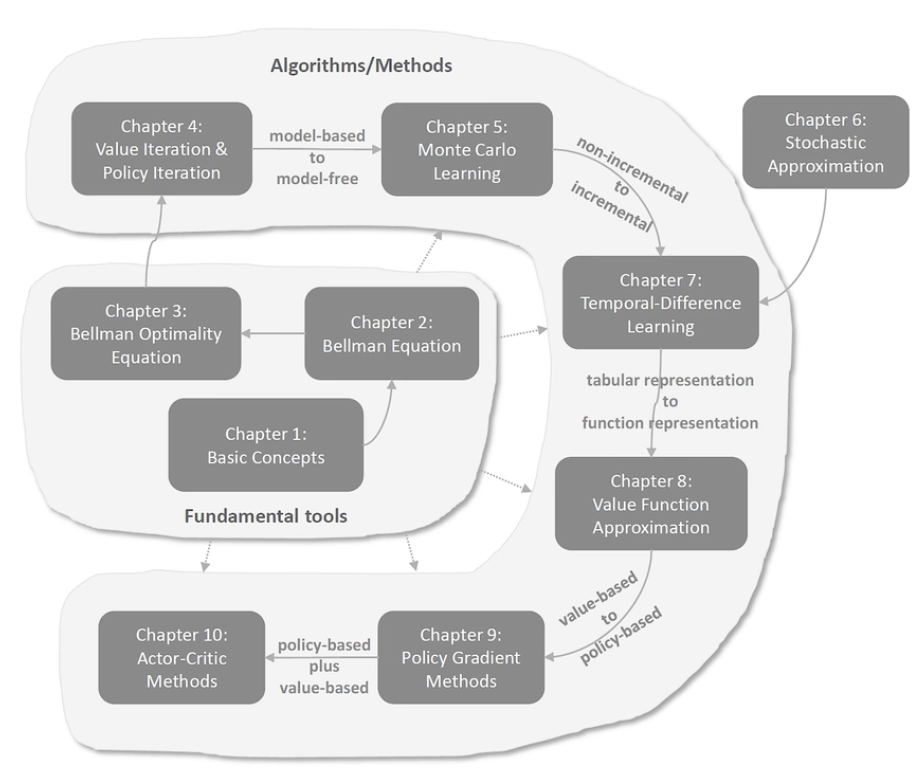
基础工具
- 基本概念:state, action, reward, return, episode, policy, mdp…
- 贝尔曼公式:用于评价策略
- 贝尔曼最优公式:强化学习的最终目标是求解最优策略
算法/方法
- 值迭代、策略迭代—— truncated policy iteration:值和策略update不断迭代
- Monte Carlo Learning:无模型学习
- 随即近似理论:from non-incremental to incremental
- 时序差分方法(TD)
- 值函数估计:tabular representation to function representation,引入神经网络
- Policy Gradient Methods:from value-based to policy-based
- Actor-Critic Methods:policy-based + value-based
强化学习-直观理解
不用告诉该怎么做,而是给定奖励函数,什么时候做好。
回归
增加折现因子
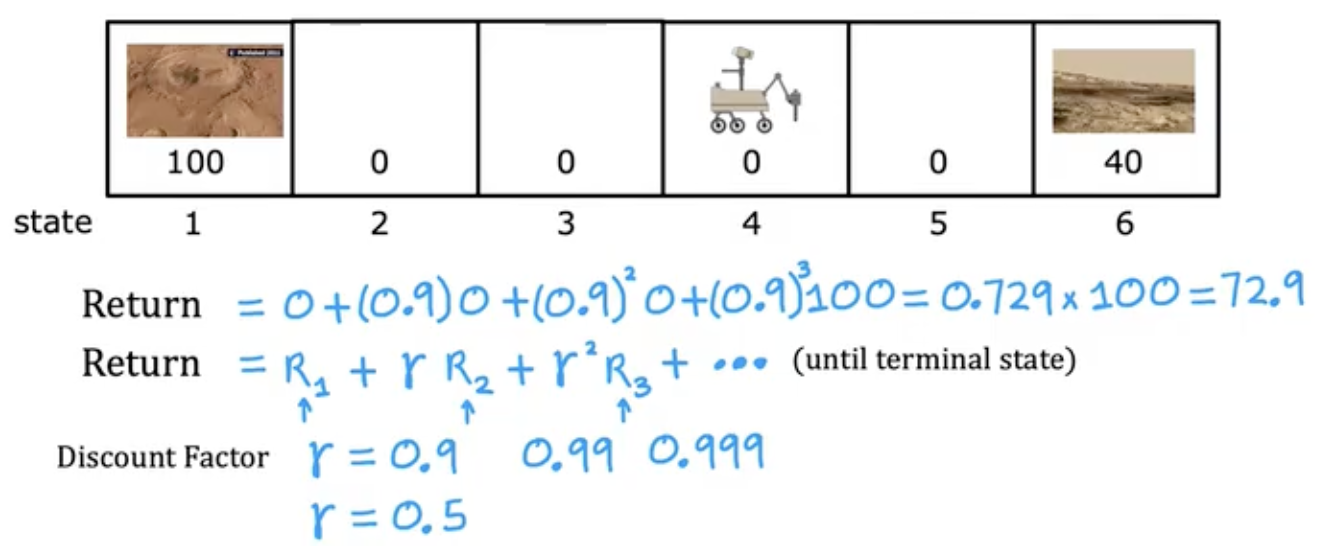
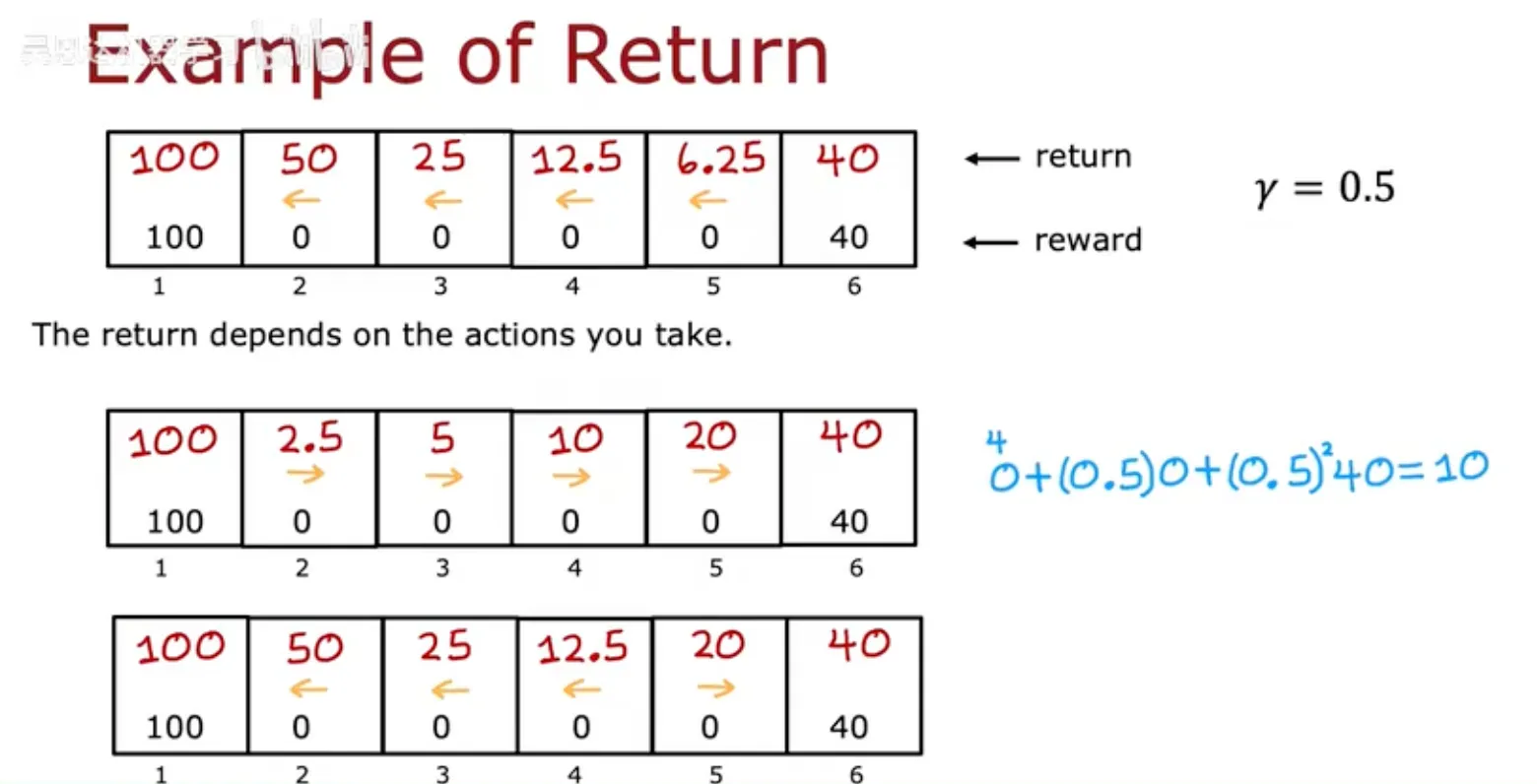
强化学习的形式化
A policy is a function $\pi(s) = a$ mapping from states to actions, that tells you what $action \space a$ to take in a given $state \space s$.
goal: Find a $policy \space \pi$ that tells you what $action (a = (s))$ to take in every $state (s)$ so as to maximize the return.
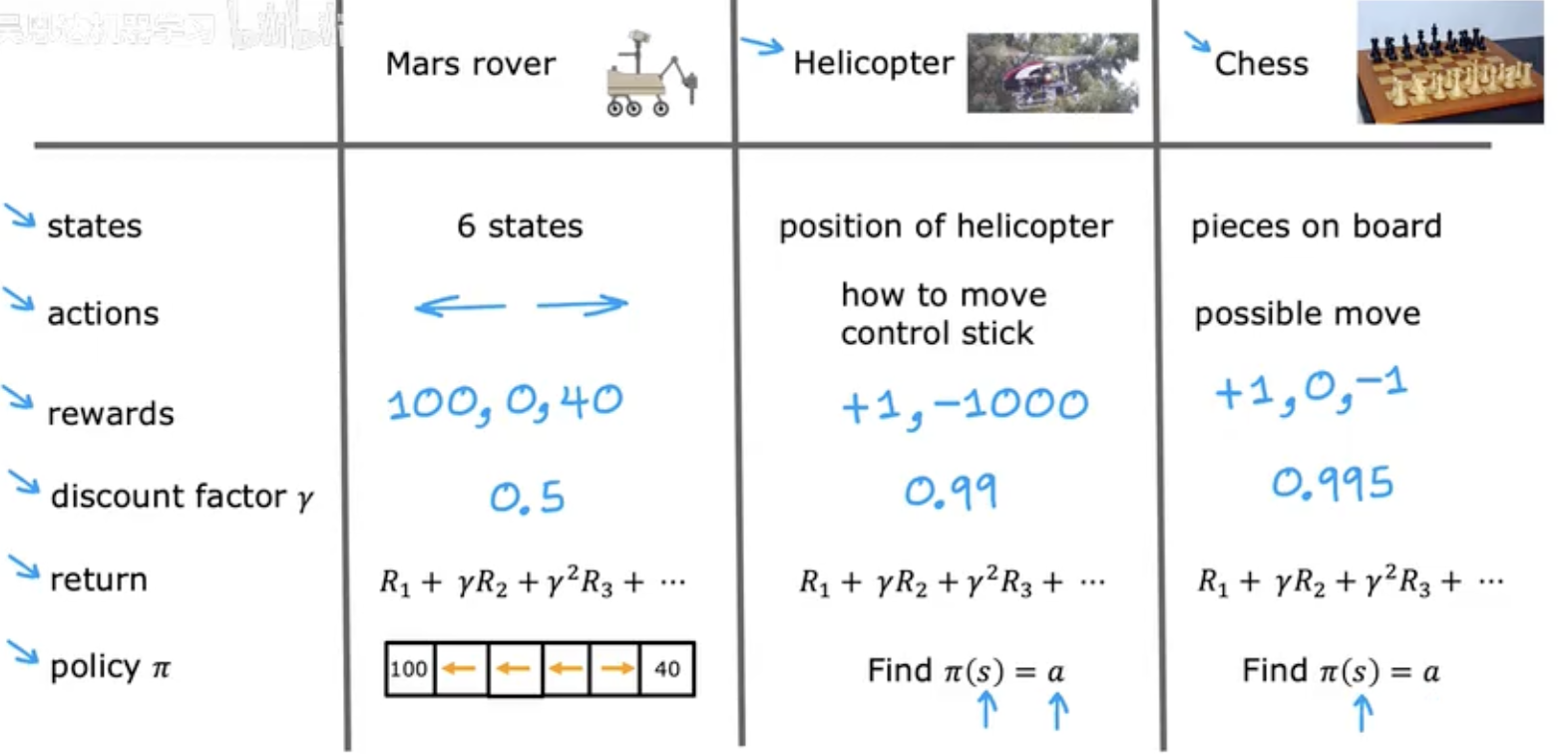
状态动作值函数(Q-Function)
Q(s,a) = Return if you:
- start in state s.
- take action a (once).
- then behave optimally after that.
The best possible return from state s is max$Q(s, a)$. The best possible action in state s is the action a that gives max$Q(s, a)$.
End2End
对于由多个阶段组成的学习系统,端到端学习捕获所有阶段,将其替代为单个神经网络。
- 优点:
- Let the data speak
- Less hand-designing of components needed
- 缺点:
- May need large amount of data
- Excludes potentially useful hand-designed components
关键:是否有足够的数据

Tag: KG
知识图谱
知识图谱于14年出现,之后进入平稳期,23年由于大模型的出现再次火爆。
大模型的“幻觉”问题的解决方式
- 提高LLM的能力
- 框定边界(大量符合逻辑的facts),大模型在边界内通过自身的理解能力,提供回复
- facts 来源于:一些网络/企业内部文档/企业内的数据库/结构化的知识图谱
知识图谱:一种存储facts的方式
采用了“实体&关系”的方法来存储信息
区别于简单的图:包含多种实体和多种关系
知识图谱的优势
- 关系直观
- 抓住重要信息
- 弥补文本到向量直接的关系(GraphRAG:KG与向量数据库融合)
RAG 与知识图谱结合
知识图谱的必要性
e.g:问题:“感冒常用药物的负作用”;数据库存储的是“冲剂” 的描述,对应段落刚好没有出现“感冒” 这个关键词;两者相似度不够高,无法匹配
—— 使用知识图谱找到“感冒”和“冲剂”之间的关系
Tag: 考试
上海创智学院2025PE考试
注意:提示词都是用中文编写,若将中文直接翻译成英文,效果可能下降。
任务理解
给定数据结构如下所示的数据:
val.jsonl中,每⼀条数据的字段说明:
{
"user_id": 5737, // ⽤⼾编号
"item_list": [ // ⽤⼾历史观看电影列表,按时间顺序排列,越靠后表⽰越近期观看
[1836, "Last Days of Disco, The"], // [电影ID, 电影名称]
[3565, "Where the Heart Is"],
// ... 更多历史观看记录,⻓度不定
],
"target_item": [1893, "Beyond Silence"], // ⽤⼾实际观看的下⼀部电影 [电影ID, 电影名称]
"candidates": [ // 推荐系统召回阶段得到的候选电影列表
[2492, "20 Dates"],
[684, "Windows"],
[1893, "Beyond Silence"], // 包含⽤⼾实际观看的下⼀部电影
// ... 更多候选电影,⻓度不定,⼀般为20个左右
]
}
我们需要将candidates列表按照匹配度进行重排序,列表第一个元素是最有可能(最喜欢)观看的电影,列表最后一个是最不可能(最不喜欢)的电影。
「复试」项目
尊敬的各位老师好!我叫yaj,本科就读于北京航空航天大学,计算机科学与技术专业。
在校期间,我掌握了较扎实的数学基础和编程能力,通过查阅期刊论文了解最新科研动向。
除此之外,我积极参与各类比赛并获得奖项,有效提升了我的工程实践能力。在毕业设计中,我独立完成从文献调研到模型实现的全流程工作,并且,该项目被获评为北航校级优秀毕设。
在实践方面,我先后在中国软件与技术服公司、北京航空航天大学和清华大学进行实习。实习期间,我参与了世界模型、时间序列预测、强化学习和目标检测等人工智能相关项目。这些经历使我不仅掌握了深层技术,更形成了"从理论到应用"的完整研发视角。
上海交通大学一直是我向往的学校,很希望能得到在贵校学习的机会。攻读研究生期间,我会专注于理论与实践的双向发展,深入学习技术背后的底层原理。我的目标是成为一名优秀的工程师,为这个行业做出实质性贡献。我深信计算机领域的技术发展,必将将推动社会的下一场变革。
以上是我的自我介绍。非常感谢各位老师的聆听!
「复试」英语口语
Good morning, professors. My name is Yang Aijun. I am from Beihang University, where I majored in Computer Science and Technology. During my undergraduate studies, I built a strong foundation in mathematics and programming, and I try to keep up with the latest developments in computer science by reviewing journal papers. I actively participated in various competitions, and earned awards for my efforts. And my graduation thesis was recognized as one of the most outstanding project at the school level.
Additionally, I have gained practical experience through internships at China Software and Technology Company, Beihang University, and Tsinghua University. During these experiences, I worked on AI-related projects such as world models, time series prediction, reinforcement learning, and object detection. These experiences have greatly enhanced my skills and deepened my passion for computer science.
As for my master studies, I plan to focus on both the theoretical and practical aspects of artificial intelligence, particularly reinforcement learning. My goal is to become an outstanding engineer and contribute meaningfully to this industry. I strongly believe that the progress made in these fields will drive significant changes in technology.
That’s all for my brief introdution. Thank you very much for taking the time to interview me.
不要说自己英文不好,按照自己理解的逻辑即可。主要是靠英文能力,不是考内容。能表达自己听到的问题,流利回答,语速不要太快。有前置语言。所有的问题是没有标准答案的,要自信。
有五到六个考官,面对主考官说即可。眼睛一定要面对老师。就算老师没关注我,也要注视老师,可眼神互动。
不要说,自己可能回答的不够好,要展现自己的自信。
Tag: RAG
Tag: CV
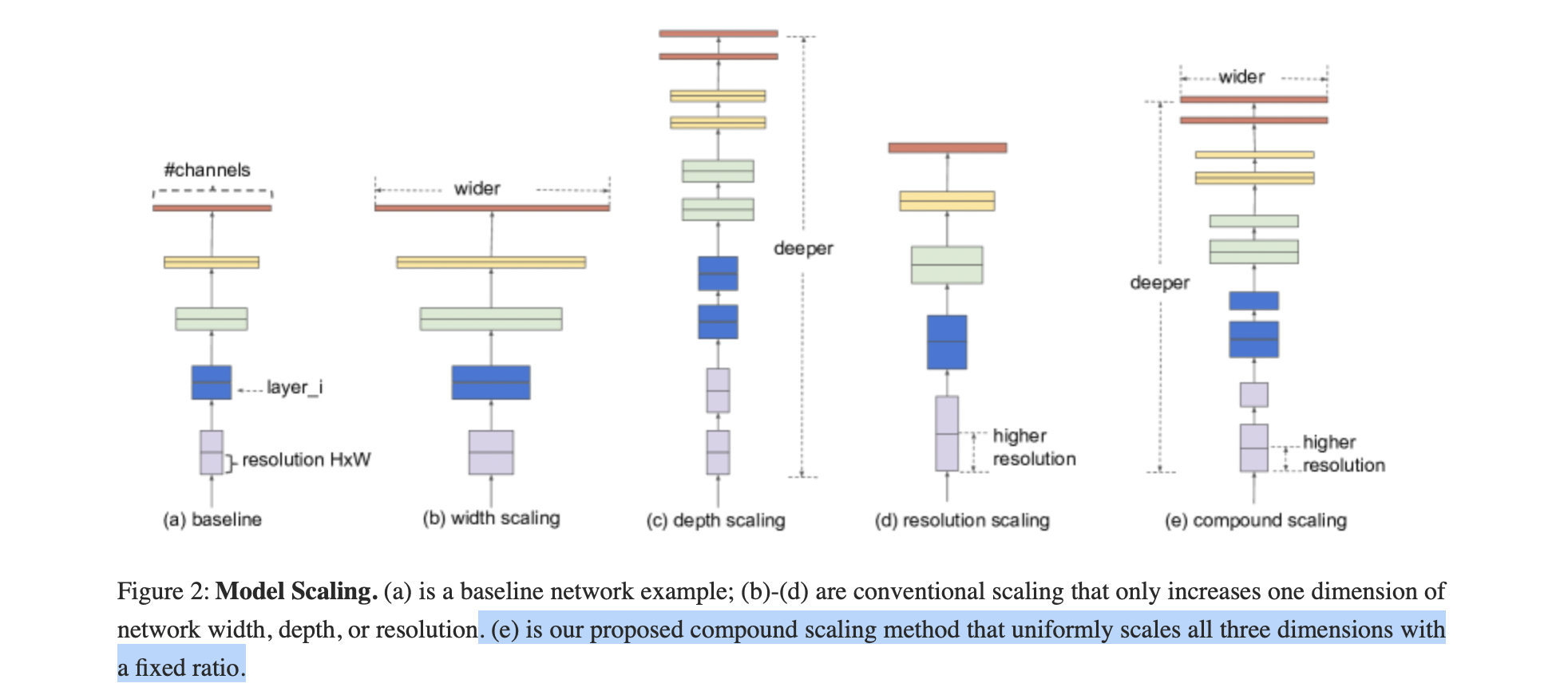
EfficientNet
传统的模型缩放:
任意增加 CNN 的深度或宽度,或使用更大的输入图像分辨率进行训练和评估。
缺点:通常需要长时间的手动调优,并且仍然会经常产生次优的性能。
- 提出了一种新的模型缩放方法和 AutoML 技术,使用使用简单但高效的复合系数,均匀缩放深度/宽度/分辨率的所有维度。
- 使用神经架构搜索来设计一个新的基线网络,并将其扩展以获得一系列模型,称为 EfficientNets。
优点:更小、更快。
复合模型放缩
1. 概述
目的:找到在固定资源约束下,基线网络的不同缩放维度之间的关系。
ResNet18
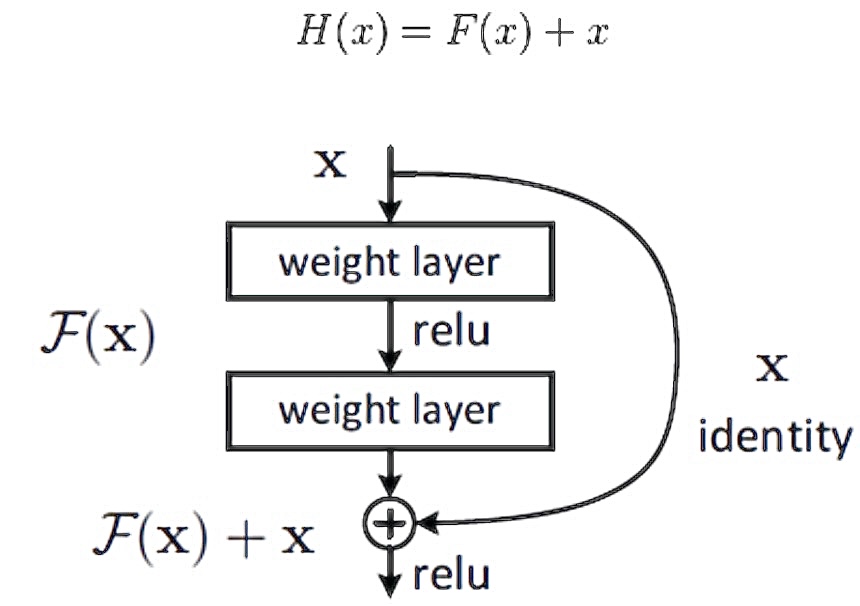
1. 退化现象
ResNet 随着网络层不断的加深,模型的准确率
- 先是不断的提高,达到最大值(准确率饱和),
- 然后随着网络深度的继续增加,模型准确率出现大幅度的降低。
原因:随着网络深度的不断增大,所引入的激活函数也越来越多,数据被映射到更加离散的空间,此时已经难以让数据回到原点。也就是说,神经网络将这些数据映射回原点所需要的计算量,已经远远超过我们所能承受的。
2. 快捷连接
核心思想:通过添加额外的连接来解决深度神经网络训练中的梯度消失和梯度爆炸等问题,从而允许构建非常深的神经网络。
LSS代码
文章搬运,自用。
论文:Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
官方源码:lift-splat-shoot
Lift, Splat, Shoot图像BEV安装与模型代码详解
对于任意数量不同相机帧的图像直接提取场景的BEV表达;主要由三部分实现:
- Lift:将每一个相机的图像帧根据相机的内参转换提升到 frustum(锥形)形状的点云空间中。
- splate:将所有相机转换到锥形点云空间中的特征根据相机的内参 K 与相机相对于 ego 的外参T映射到栅格化的 3D 空间(BEV)中来融合多帧信息。
- shoot:根据上述 BEV 的检测或分割结果来生成规划的路径 proposal;从而实现可解释的端到端的路径规划任务。
注:LSS在训练的过程中并不需要激光雷达的点云来进行监督。
语义分割
语义分割将图片中的每个像素分类到对应的类别。
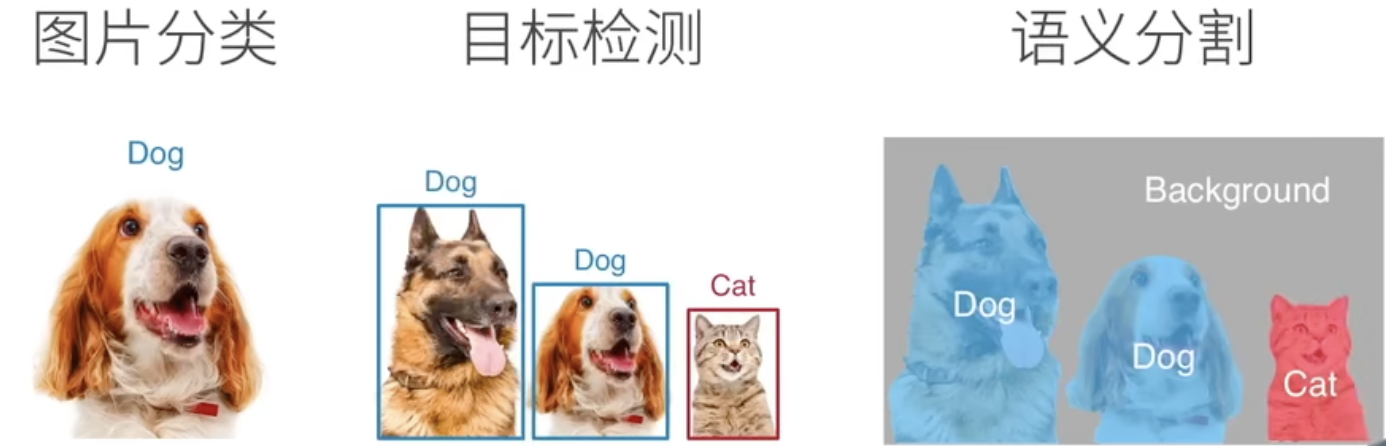
应用:
背景虚化、路面分割、实例分割(会关注具体是哪个个体,如 Mask R-CNN)、全景分割(还要对背景进行分割,如 Panoptic FPN)
常见模型
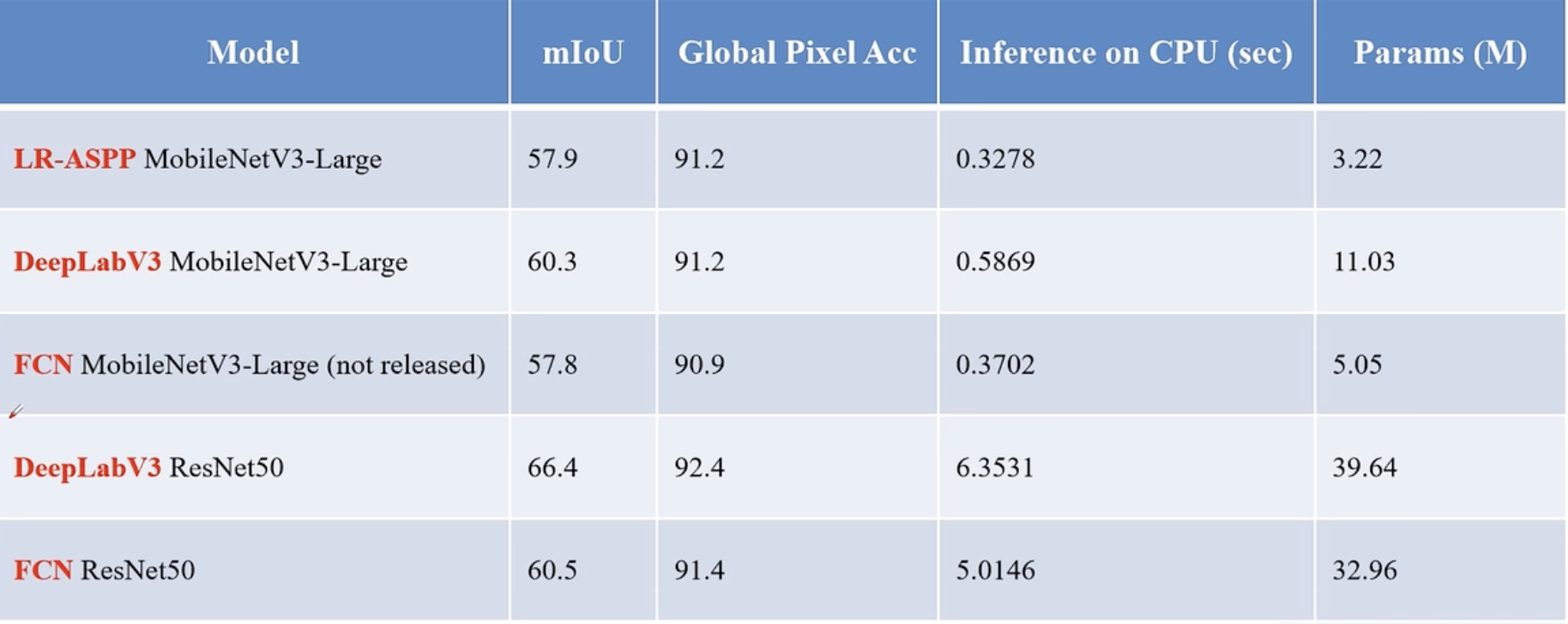
语义分割任务常见的数据集格式
- PASCAL VOC:PNG图片 + 每个像素的类别信息(每个像素都对应一个颜色)
- MS COCO:每个目标都记录了一个多边形坐标,将所有的点连一起,即可得到边缘信息(还可以用于实例分析)
- 语义分割得到的具体形式:单通道图片,加上调色板 mask 蒙版后可以上色(palette),方便可视化。每个像素数值对应类别索引。
Lift-splat-shoot
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
简单来说,Lift就是预测了一个深度值分布D,以及提取的特征c,然后将两种进行外积操作,实现了增维操作。
**Splat(拍扁)**操作则是使用了一种特殊的“求和池化”操作(z累加,压平),实现降维。
最后的Shooting,则是将预测的一组轨迹投射出来,选取最优的轨迹作为预测结果。
1. 关键:Lift
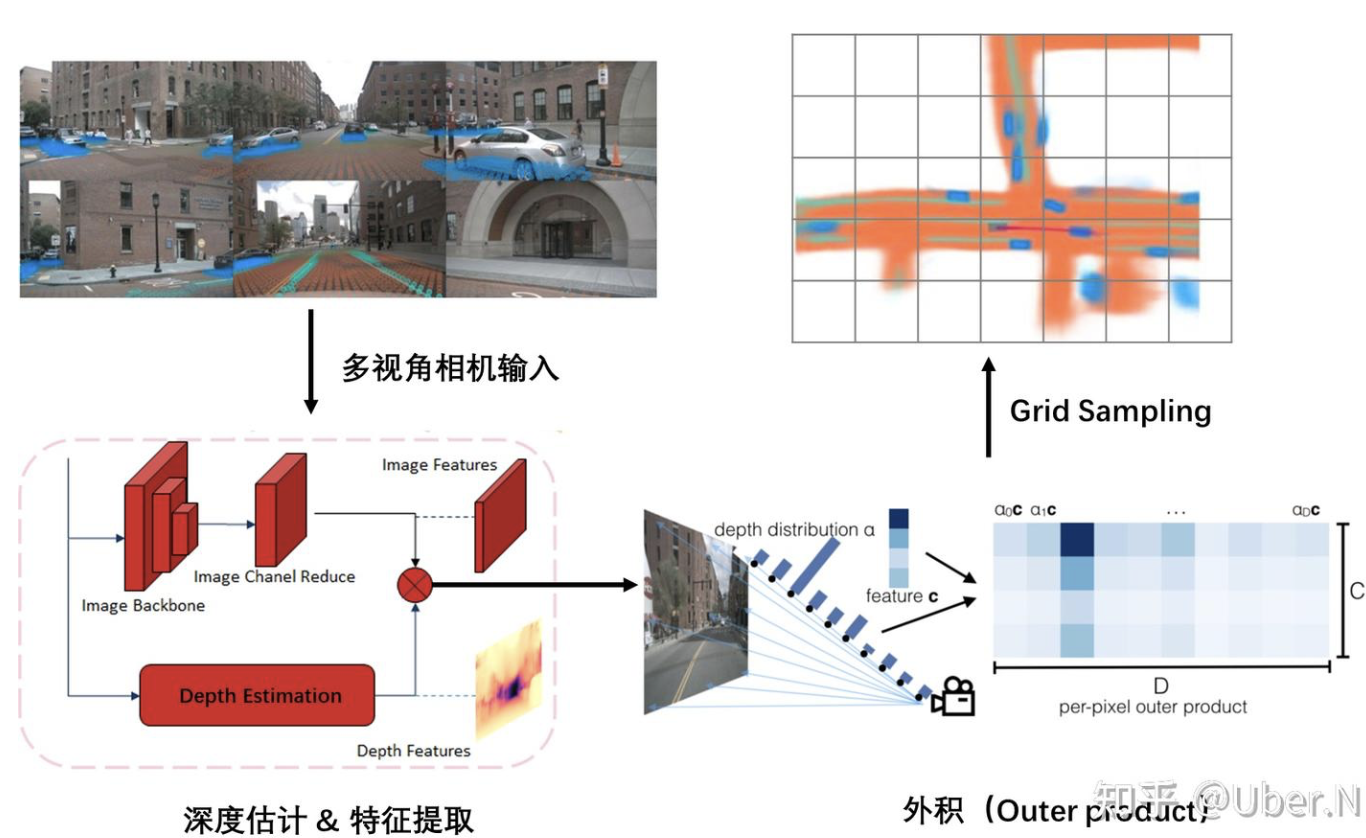
特征提取&深度估计
多视角相机输入后,进行特征提取与深度估计
外积(Outer product)—— 最核心的操作
无法确定每个 pixel 的特征投影 BEV 视角下的具体位置;对于每个 pixel 特征,使用的是“all possible depths”。
使用外积操作,将 Image feature (H * W * C) 和 Depth feature (H * W * D)构造成一个(H * W * D * C) 的 Frustum feature。
BEV 论文学习
Vision-Centric BEV Perception: A Survey
许多方法被提出以解决从透视视图(Perspective View, PV)到 BEV 的转换问题,本文将它们分为基于几何、基于深度、基于 MLP 和基于 Transformer 的四类方法。
此外,本文还探讨了 BEV 感知的扩展应用,如多任务学习、多模态融合和语义占据预测等。
1. 背景介绍
BEV 感知的核心任务是将 PV 中的图像序列转换为BEV特征,并在BEV空间中进行感知任务(如3D目标检测和语义地图生成),能够提供精确的定位和绝对尺度信息,便于多视图、多模态和时间序列数据的融合。
但由于摄像头通常安装在车辆上,捕捉到的图像是透视视图,如何将 PV 转换为 BEV 仍然是一个具有挑战性的问题。
3. 主要方法分类
基于几何的方法
- 优势:这类方法主要依赖于逆透视映射(IPM),通过几何变换将 PV 图像转换为 BEV 图像。
- 缺陷:但 IPM 假设地面是平坦的,因此在复杂场景中(如存在高度变化的物体)会产生失真。为了减少失真,一些方法引入了语义信息或使用 GAN 。
基于深度的方法
通过深度估计将 2D 特征提升到 3D 空间,然后通过降维得到 BEV 表示。深度估计可以是显式的(如通过深度图)或隐式的(如通过任务监督)。
- 点云方法:将深度图转换为伪 LiDAR 点云,然后使用 LiDAR 检测器进行 3D 检测
- 体素方法:将 2D 特征映射到 3D 体素空间,并通过体素特征进行 BEV 感知
基于MLP的方法
- 优势:MLP 方法不依赖于摄像头的几何参数,而是通过学习隐式表示来完成视图转换。
- 缺陷:尽管 MLP 具有通用逼近能力,但由于缺乏深度信息和遮挡问题,视图转换仍然具有挑战性。
基于Transformer的方法:
MLLM
1基础
1. 特征提取
一、CV中的特征提取
1. 传统方法(手工设计特征)
(1) 低级视觉特征:颜色、纹理、 边缘与形状…
(2) 中级语义特征:SIFT(尺度不变特征变换)、SURF(加速鲁棒特征)、LBP(局部二值模式)…
2. 深度学习方法(自动学习特征)
(1) 卷积神经网络(CNN)
核心思想:通过卷积层提取局部特征,池化层降低维度,全连接层进行分类。
经典模型:LeNet-5、AlexNet、VGGNet、ResNet(使用残差可以训练更深的网络)…
(2) 视觉Transformer(ViT)
- 核心思想:将图像分割为小块(patches),通过自注意力机制建模全局关系。
- 优势:无需局部卷积先验,直接建模长距离依赖; 在ImageNet等任务上超越传统CNN。
目标检测
技巧
Ensembling:Train several networks independently and average their outputs Multi-crop at test time:Run classifier on multiple versions of test images and average results
定位
Need to output bx, by, bn, bw, class label (1-4)
需人工标注特征点的坐标
基于滑动窗口的目标检测算法
- 先训练卷积网络识别物体
- 滑动+放大窗口+再次滑动
问题:计算效率大,慢
CV
问题: 处理高分辨率图像时,原始图像的像素数量通常非常庞大。
边缘检测
垂直边缘检测滤波
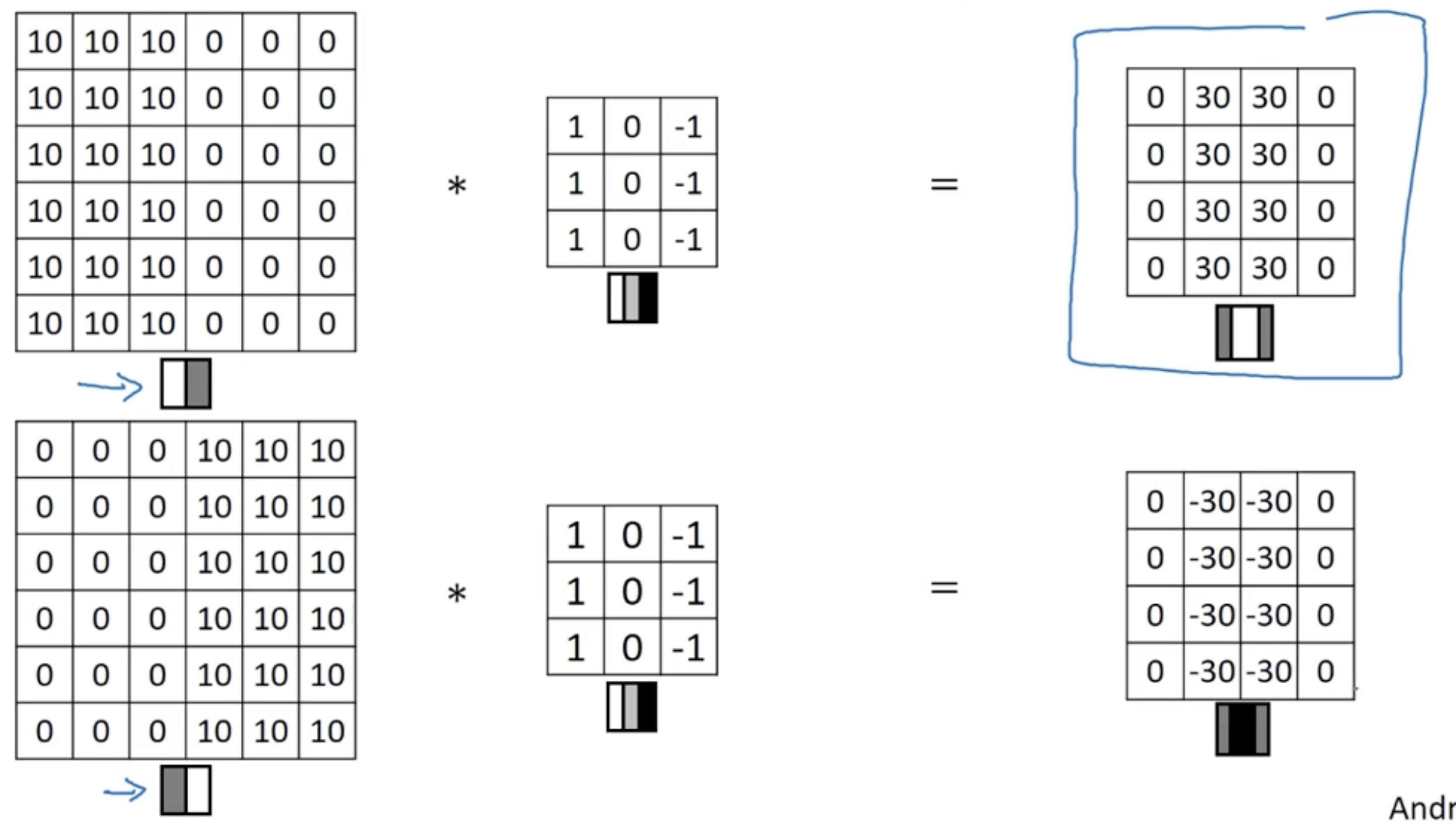
变权
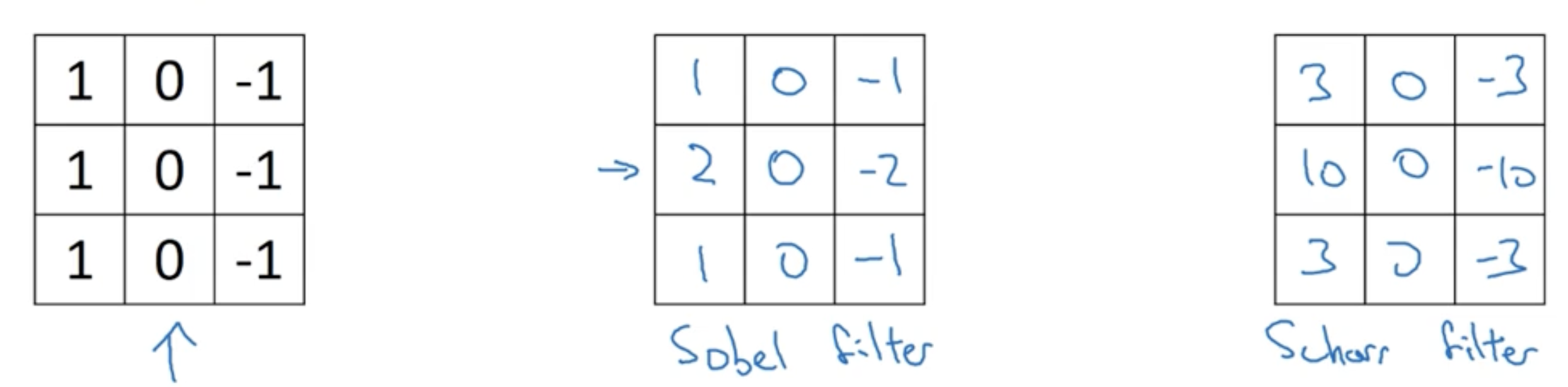
利用反向传播学习
Padding
Padding:外层填充像素
- 存在问题:
- throw away information from edge
- shranky output
解决:外层填充像素
- 存在问题:
填充多少像素?
Valid: (n-f+1) * (n-f+1)
Same: Pad so that output size is the same as the input size.
Tag: Data Processing
工具链-PyTorch
1. 处理数据
PyTorch 有两个用于处理数据的基元: torch.utils.data.DataLoader 和 torch.utils.data.Dataset。
Dataset 存储样本及其相应的标签,DataLoader 将 Dataset 包装成一个迭代器。
下面以 TorchVision 库模块里的 FashionMNIST 数据集为例:
每个 TorchVision
Dataset都包含两个参数:transform和target_transform分别修改样本和标签
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
将 Dataset 作为参数传递给 DataLoader ,将一个可迭代对象包装在数据集上,支持自动批处理、采样、洗牌和多进程数据加载。
定义了一个 batch size 为 64,即 dataloader 迭代器中的每个元素将返回一个 64 features and labels 的 batch。
数据集-NuSences
内容
nuScenes 包含 1000 个场景,大约 1.4M 的相机图像、390k LIDAR 扫描、1.4M 雷达扫描和 40k 关键帧中的 1.4M 对象边界框。
nuScenes-lidarseg 包含 40000 个点云和 1000 个场景(850 个用于训练和验证的场景,以及 150 个用于测试的场景)中的 14 亿个注释点。
数据采集
车辆设置
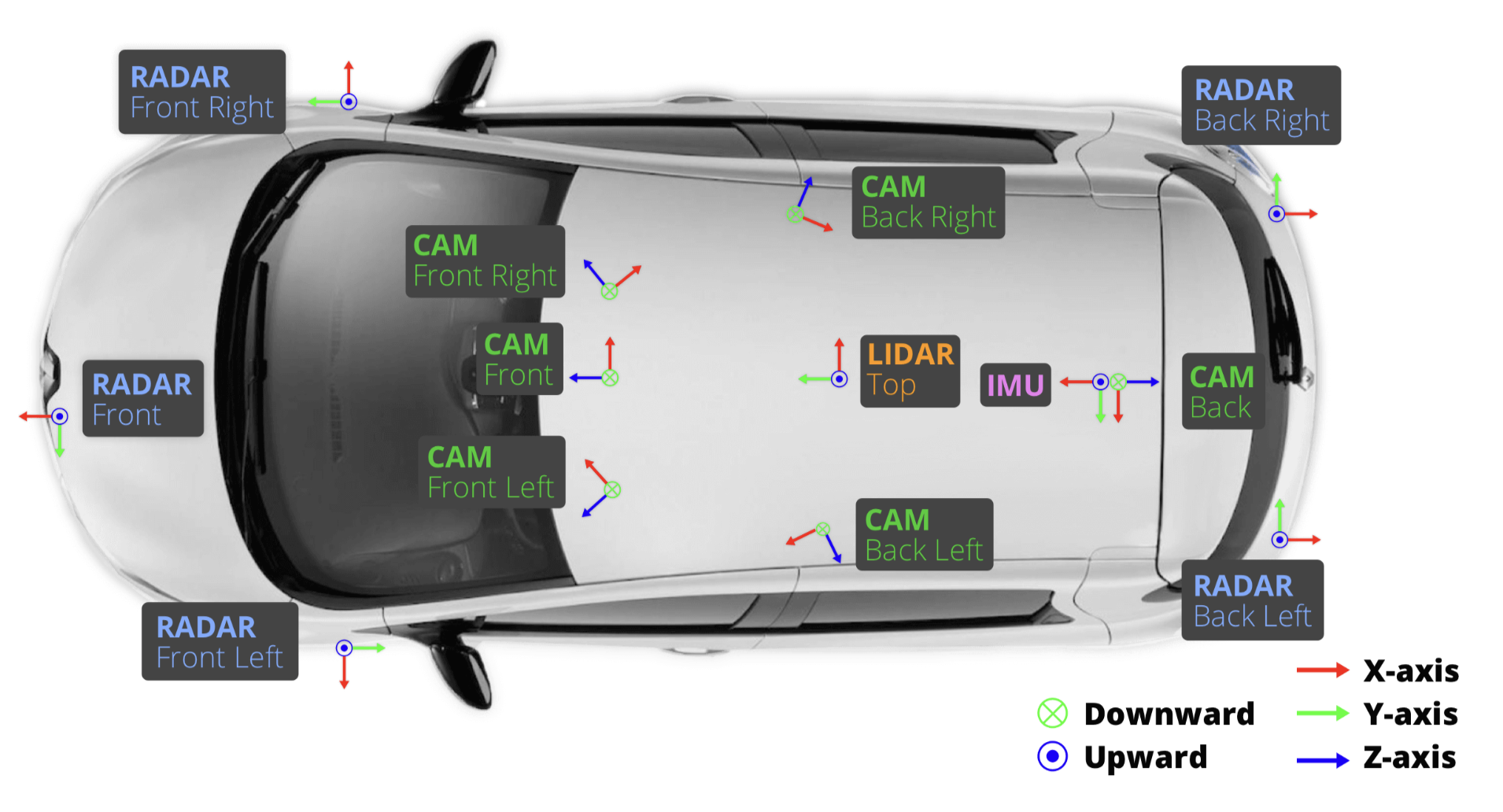
- 1 个旋转激光雷达 (Velodyne HDL32E)
- 5 个远程雷达传感器 (Continental ARS 408-21)
- 6 个相机 (Basler acA1600-60gc)
- 1个 IMU & GPS (高级导航空间版)
Sensor(传感器)校准 - 内外参
- LIDAR extrinsics
- 相机 extrinsics
- RADAR extrinsics
- 相机 intrinsic 校准
Sensor(传感器)同步
实现跨模态数据对齐:当顶部 LIDAR 扫描相机 FOV 的中心时,会触发相机的曝光
Tag: AD
数据集-NuSences
内容
nuScenes 包含 1000 个场景,大约 1.4M 的相机图像、390k LIDAR 扫描、1.4M 雷达扫描和 40k 关键帧中的 1.4M 对象边界框。
nuScenes-lidarseg 包含 40000 个点云和 1000 个场景(850 个用于训练和验证的场景,以及 150 个用于测试的场景)中的 14 亿个注释点。
数据采集
车辆设置
- 1 个旋转激光雷达 (Velodyne HDL32E)
- 5 个远程雷达传感器 (Continental ARS 408-21)
- 6 个相机 (Basler acA1600-60gc)
- 1个 IMU & GPS (高级导航空间版)
Sensor(传感器)校准 - 内外参
- LIDAR extrinsics
- 相机 extrinsics
- RADAR extrinsics
- 相机 intrinsic 校准
Sensor(传感器)同步
实现跨模态数据对齐:当顶部 LIDAR 扫描相机 FOV 的中心时,会触发相机的曝光
Tag: Algorithm
「算法模版」动态规划
「状态」-> 「选择」 -> 定义 dp 数组/函数的含义 ;自底向上进行递推求解。
# 自顶向下递归的动态规划
def dp(状态1, 状态2, ...):
for 选择 in 所有可能的选择:
# 此时的状态已经因为做了选择而改变
result = 求最值(result, dp(状态1, 状态2, ...))
return result
# 自底向上迭代的动态规划
# 初始化 base case
dp[0][0][...] = base case
# 进行状态转移
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 求最值(选择1,选择2...)
核心框架
备忘录 - 斐波那契数
int fib(int n) { if (n == 0 || n == 1) return n; // 分别代表 dp[i - 1] 和 dp[i - 2] int dp_i_1 = 1, dp_i_2 = 0; for (int i = 2; i <= n; i++) { int dp_i = dp_i_1 + dp_i_2; dp_i_2 = dp_i_1; dp_i_1 = dp_i; } return dp_i; }最优子结构 - 零点兑换
c++语法
万能开头:
#include<bits/stdc++.h>
using namespace std;
在 C++ 中,using namespace std;指令允许用户使用 std 命名空间中的所有标识符,而无需在它们前面加上 std::。
标准输入输出
标准输入是 cin, cin用 >> 运算符把输入传给变量。
标准输出是 cout,用 << 运算符把需要打印的内容传递给 cout,endl 是换行符。
#include <bits/stdc++.h>
int a;
cin >> a; // 从输入读取一个整数
// 输出a
std::cout << a << std::endl;
// 可以串联输出
// 输出:Hello, World!
std::cout << "Hello" << ", " << "World!" << std::endl;
string s = "abc";
a = 10;
// 输出:abc 10
std::cout << s << " " << a << std::endl;
算法 - C++STL常用容器
插入函数总结
| 方法 | 适用容器 | 作用 | 性能特性 |
|---|---|---|---|
push | queue、stack、priority_queue | 添加元素到容器末尾或顶部 | 适用于特定容器,性能与容器实现相关 |
push_back | vector、deque、list | 添加元素到容器末尾 | 需要拷贝或移动元素 |
emplace | set、map、unordered_set 等 | 在容器中直接构造元素 | 避免不必要的拷贝或移动 |
emplace_back | vector、deque、list | 在容器末尾直接构造元素 | 避免不必要的拷贝或移动 |
insert | 大多数容器 | 将元素插入到容器的指定位置 | 需要拷贝或移动元素 |
「算法模版」树
层级遍历
while 循环控制⼀层⼀层往下⾛,for 循环利⽤ sz 变量控制从左到右遍历每⼀层⼆叉树节点。
// 输⼊⼀棵⼆叉树的根节点,层序遍历这棵⼆叉树
void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> q = new LinkedList<>();
q.push(root);
int depth = 1;
// 从上到下遍历⼆叉树的每⼀层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每⼀层的每个节点
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
printf("节点 %s 在第 %s 层", cur, depth);
// 将下⼀层节点放⼊队列
if (cur.left != null) {
q.push(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
depth++;
}
}
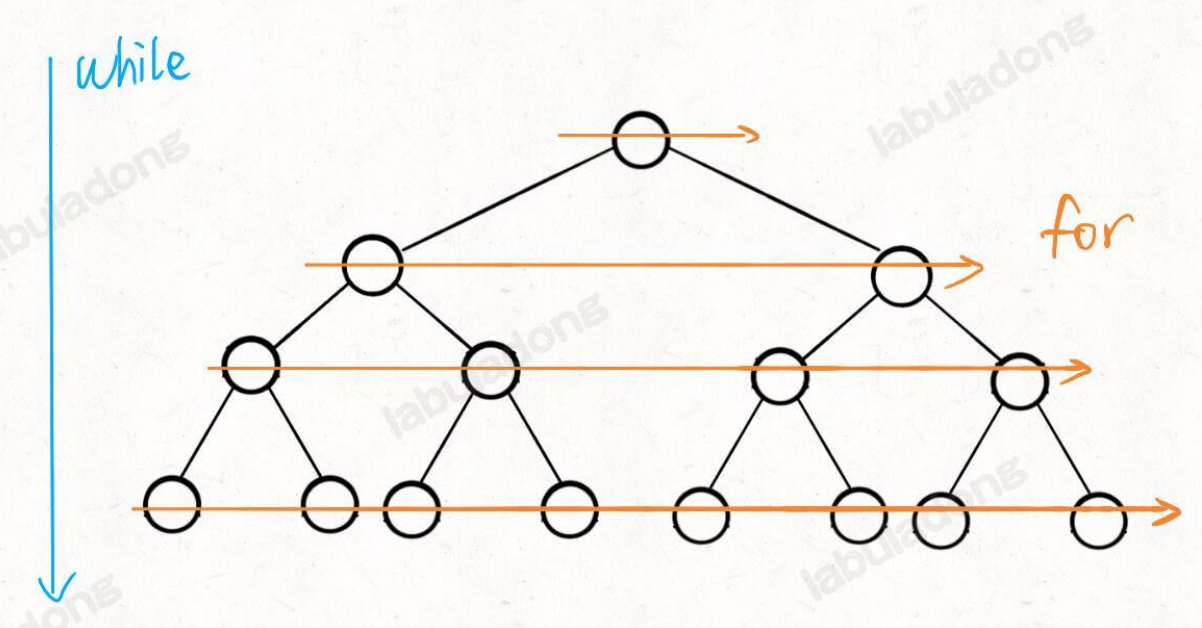
「算法模版」图
存储图
邻接矩阵
邻接表
// 对于每个点k,开一个单链表,存储k所有可以走到的点 // h[k]存储这个单链表的头结点 int h[N], e[N], ne[N], idx; // 添加一条边a->b void add(int a, int b) { e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ; } // 初始化 idx = 0; memset(h, -1, sizeof h);
回溯算法
回溯法:一种通过探索所有可能的候选解来找出所有的解的算法。如果候选解被确认不是一个解(或者至少不是最后一个解),回溯算法会通过在上一步进行一些变化抛弃该解,即回溯并且再次尝试。
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择 : 本层集合中的元素) {
处理节点;
backtracking(路径, 选择列表); // 递归
撤销处理; // 回溯
}
}
「算法模版」基础
- 主要思想
- 代码模版
- 背过:快速默写,调试通过
- 先看模版思想 —— 模版已为我们考虑好了所有边界情况
- 默写一遍(用题目)
- 提高熟练度
- 一道题目重复3-5次
- 背过:快速默写,调试通过
一、排序
1. 快速排序
核心思想 —— 分治
- 确定分界点x
- 调整区间
- 递归处理左右两段
调整区间的暴力做法:选定x,开a,b两数组,遍历q,小于x放a,大于x放b。
优雅做法:用两个指针i、j,分别指向第一和最后一个数,两指针向中间移动,使得i左小于x,j右大于x;否则交换i、所指的数。
「持续更新」算法题笔记
万能开头
#include<bits/stdc++.h>
using namespace std;
在 C++ 中,using namespace std;指令允许用户使用 std 命名空间中的所有标识符,而无需在它们前面加上 std::。
leetcode hot 100
hash
两数之和
题目描述:给定一个整数数组
nums和一个整数目标值target,请你在该数组中找出 和为目标值target的那 两个 整数,并返回它们的数组下标。方法:找数
x,寻找数组中是否存在target - x。使用哈希表,可以将寻找
target - x的时间复杂度降低到从 O(N) 降低到 O(1) —— 创建一个哈希表,对于每一个x,我们首先查询哈希表中是否存在target - x,然后将x插入到哈希表中,即可保证不会让x和自己匹配。
二叉树
二叉树
二叉树的实现方式
最常见的二叉树就是类似链表那样的链式存储结构,每个二叉树节点有指向左右子节点的指针
class TreeNode { public: int val; TreeNode* left; TreeNode* right; // 构造函数,参数是int x, :后面的部分是初始化列表,{} 是构造函数的函数体为空,即不需要额外的操作。 TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} }; // 你可以这样构建一棵二叉树: TreeNode* root = new TreeNode(1); root->left = new TreeNode(2); root->right = new TreeNode(3); root->left->left = new TreeNode(4); root->right->left = new TreeNode(5); root->right->right = new TreeNode(6); // 构建出来的二叉树是这样的: // 1 // / \ // 2 3 // / / \ // 4 5 6public用法总结:public关键字用于指定类成员的访问权限,允许外部代码直接访问这些成员。- 如果不加
public,这些成员默认是private的,外部代码无法直接访问它们。
在
TreeNode的构造函数中,初始化列表的作用是:
数组链表
1. 动态数组
动态数组底层还是静态数组,只是自动帮我们进行数组空间的扩缩容,并把增删查改操作进行了封装。
// 创建动态数组
// 不用显式指定数组大小,它会根据实际存储的元素数量自动扩缩容
ArrayList<Integer> arr = new ArrayList<>();
for (int i = 0; i < 10; i++) {
// 在末尾追加元素,时间复杂度 O(1)
arr.add(i);
}
// 在中间插入元素,时间复杂度 O(N)
// 在索引 2 的位置插入元素 666
arr.add(2, 666);
// 在头部插入元素,时间复杂度 O(N)
arr.add(0, -1);
// 删除末尾元素,时间复杂度 O(1)
arr.remove(arr.size() - 1);
// 删除中间元素,时间复杂度 O(N)
// 删除索引 2 的元素
arr.remove(2);
// 根据索引查询元素,时间复杂度 O(1)
int a = arr.get(0);
// 根据索引修改元素,时间复杂度 O(1)
arr.set(0, 100);
// 根据元素值查找索引,时间复杂度 O(N)
int index = arr.indexOf(666);
Tag: C++
c++语法
万能开头:
#include<bits/stdc++.h>
using namespace std;
在 C++ 中,using namespace std;指令允许用户使用 std 命名空间中的所有标识符,而无需在它们前面加上 std::。
标准输入输出
标准输入是 cin, cin用 >> 运算符把输入传给变量。
标准输出是 cout,用 << 运算符把需要打印的内容传递给 cout,endl 是换行符。
#include <bits/stdc++.h>
int a;
cin >> a; // 从输入读取一个整数
// 输出a
std::cout << a << std::endl;
// 可以串联输出
// 输出:Hello, World!
std::cout << "Hello" << ", " << "World!" << std::endl;
string s = "abc";
a = 10;
// 输出:abc 10
std::cout << s << " " << a << std::endl;
算法 - C++STL常用容器
插入函数总结
| 方法 | 适用容器 | 作用 | 性能特性 |
|---|---|---|---|
push | queue、stack、priority_queue | 添加元素到容器末尾或顶部 | 适用于特定容器,性能与容器实现相关 |
push_back | vector、deque、list | 添加元素到容器末尾 | 需要拷贝或移动元素 |
emplace | set、map、unordered_set 等 | 在容器中直接构造元素 | 避免不必要的拷贝或移动 |
emplace_back | vector、deque、list | 在容器末尾直接构造元素 | 避免不必要的拷贝或移动 |
insert | 大多数容器 | 将元素插入到容器的指定位置 | 需要拷贝或移动元素 |
unordered_map
unordered_map | unordered_set | |
|---|---|---|
| 存储内容 | 键值对 (std::pair<const Key, T>) | 仅存储键 (Key) |
| 是否允许重复键 | 键唯一(重复键会覆盖) | 键唯一(重复插入无效) |
| 主要用途 | 快速通过键查找值 | 快速判断键是否存在 |
| 典型操作 | map[key] = value、map.find(key) | set.insert(key)、set.count(key) |
| 内存占用 | 更高(需存储键和值) | 更低(仅存储键) |
1. 创建 unordered_map 对象
#include <unordered_map>
#include <string>
int main() {
// 默认构造函数
std::unordered_map<std::string, int> map1;
// 初始化列表构造函数
std::unordered_map<std::string, int> map2 = {{"apple", 1}, {"banana", 2}};
// 拷贝构造函数
std::unordered_map<std::string, int> map3(map2);
return 0;
}
2. 插入
insert插入一个键值对
map1.insert({"orange", 3}); map1.insert(std::make_pair("grape", 4));operator[]通过键插入或访问值。如果键不存在,会插入一个默认值。
map1["apple"] = 10; // 插入或修改 int value = map1["apple"]; // 访问
3. 访问元素
at访问指定键的值,如果键不存在会抛出
std::out_of_range异常。int value = map1.at("apple");operator[]访问或插入指定键的值。
int value = map1["apple"];
Tag: BEV
BEV 论文学习
Vision-Centric BEV Perception: A Survey
许多方法被提出以解决从透视视图(Perspective View, PV)到 BEV 的转换问题,本文将它们分为基于几何、基于深度、基于 MLP 和基于 Transformer 的四类方法。
此外,本文还探讨了 BEV 感知的扩展应用,如多任务学习、多模态融合和语义占据预测等。
1. 背景介绍
BEV 感知的核心任务是将 PV 中的图像序列转换为BEV特征,并在BEV空间中进行感知任务(如3D目标检测和语义地图生成),能够提供精确的定位和绝对尺度信息,便于多视图、多模态和时间序列数据的融合。
但由于摄像头通常安装在车辆上,捕捉到的图像是透视视图,如何将 PV 转换为 BEV 仍然是一个具有挑战性的问题。
3. 主要方法分类
基于几何的方法
- 优势:这类方法主要依赖于逆透视映射(IPM),通过几何变换将 PV 图像转换为 BEV 图像。
- 缺陷:但 IPM 假设地面是平坦的,因此在复杂场景中(如存在高度变化的物体)会产生失真。为了减少失真,一些方法引入了语义信息或使用 GAN 。
基于深度的方法
通过深度估计将 2D 特征提升到 3D 空间,然后通过降维得到 BEV 表示。深度估计可以是显式的(如通过深度图)或隐式的(如通过任务监督)。
- 点云方法:将深度图转换为伪 LiDAR 点云,然后使用 LiDAR 检测器进行 3D 检测
- 体素方法:将 2D 特征映射到 3D 体素空间,并通过体素特征进行 BEV 感知
基于MLP的方法
- 优势:MLP 方法不依赖于摄像头的几何参数,而是通过学习隐式表示来完成视图转换。
- 缺陷:尽管 MLP 具有通用逼近能力,但由于缺乏深度信息和遮挡问题,视图转换仍然具有挑战性。
基于Transformer的方法:
Tag: Algorithm"
unordered_map
unordered_map | unordered_set | |
|---|---|---|
| 存储内容 | 键值对 (std::pair<const Key, T>) | 仅存储键 (Key) |
| 是否允许重复键 | 键唯一(重复键会覆盖) | 键唯一(重复插入无效) |
| 主要用途 | 快速通过键查找值 | 快速判断键是否存在 |
| 典型操作 | map[key] = value、map.find(key) | set.insert(key)、set.count(key) |
| 内存占用 | 更高(需存储键和值) | 更低(仅存储键) |
1. 创建 unordered_map 对象
#include <unordered_map>
#include <string>
int main() {
// 默认构造函数
std::unordered_map<std::string, int> map1;
// 初始化列表构造函数
std::unordered_map<std::string, int> map2 = {{"apple", 1}, {"banana", 2}};
// 拷贝构造函数
std::unordered_map<std::string, int> map3(map2);
return 0;
}
2. 插入
insert插入一个键值对
map1.insert({"orange", 3}); map1.insert(std::make_pair("grape", 4));operator[]通过键插入或访问值。如果键不存在,会插入一个默认值。
map1["apple"] = 10; // 插入或修改 int value = map1["apple"]; // 访问
3. 访问元素
at访问指定键的值,如果键不存在会抛出
std::out_of_range异常。int value = map1.at("apple");operator[]访问或插入指定键的值。
int value = map1["apple"];
Tag: NLP
MLLM
1基础
1. 特征提取
一、CV中的特征提取
1. 传统方法(手工设计特征)
(1) 低级视觉特征:颜色、纹理、 边缘与形状…
(2) 中级语义特征:SIFT(尺度不变特征变换)、SURF(加速鲁棒特征)、LBP(局部二值模式)…
2. 深度学习方法(自动学习特征)
(1) 卷积神经网络(CNN)
核心思想:通过卷积层提取局部特征,池化层降低维度,全连接层进行分类。
经典模型:LeNet-5、AlexNet、VGGNet、ResNet(使用残差可以训练更深的网络)…
(2) 视觉Transformer(ViT)
- 核心思想:将图像分割为小块(patches),通过自注意力机制建模全局关系。
- 优势:无需局部卷积先验,直接建模长距离依赖; 在ImageNet等任务上超越传统CNN。
Tag: Generative AI
Tag: Machine Learning
Decision Tree
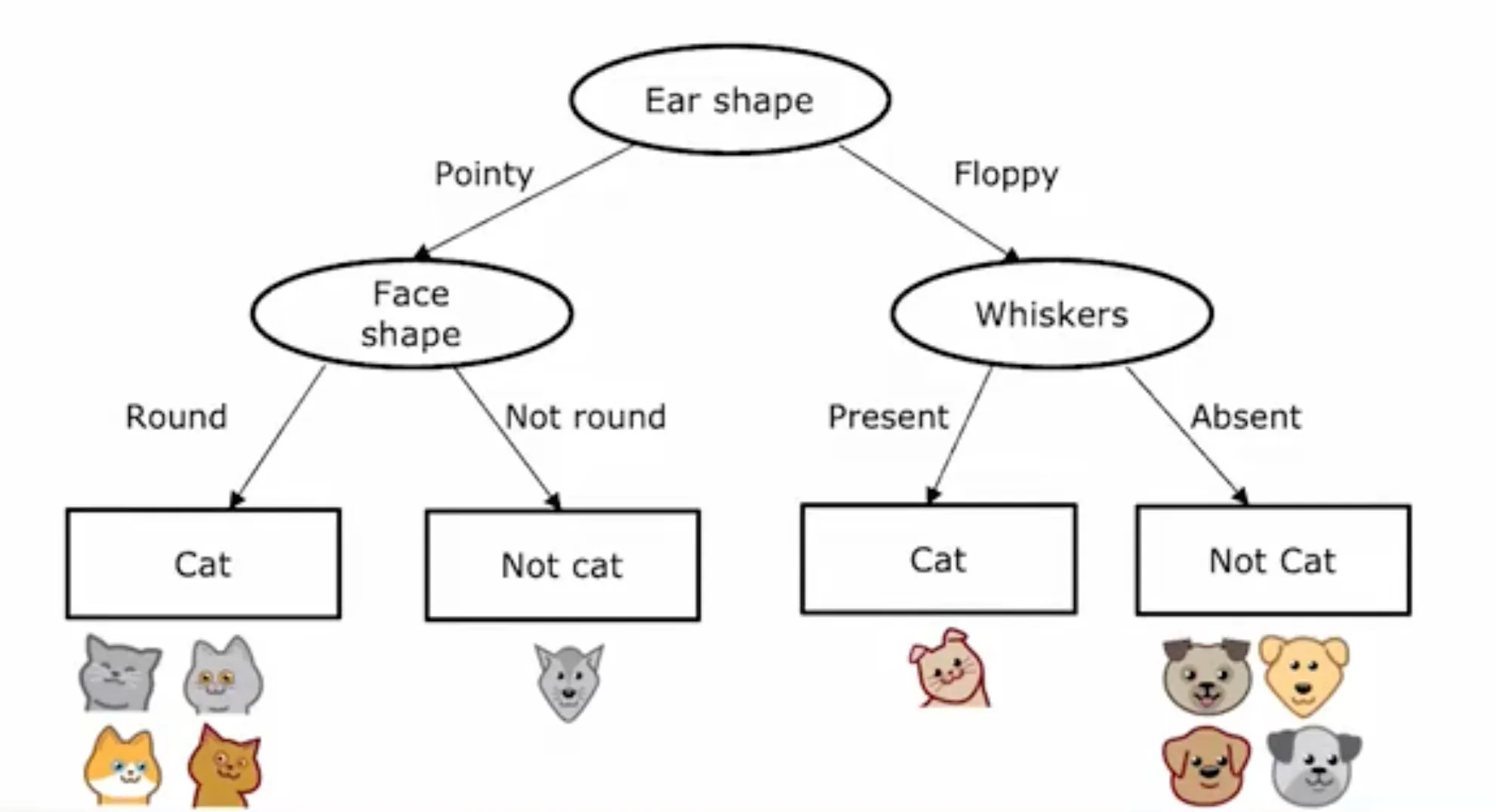
熵和信息增益
Measuring purity
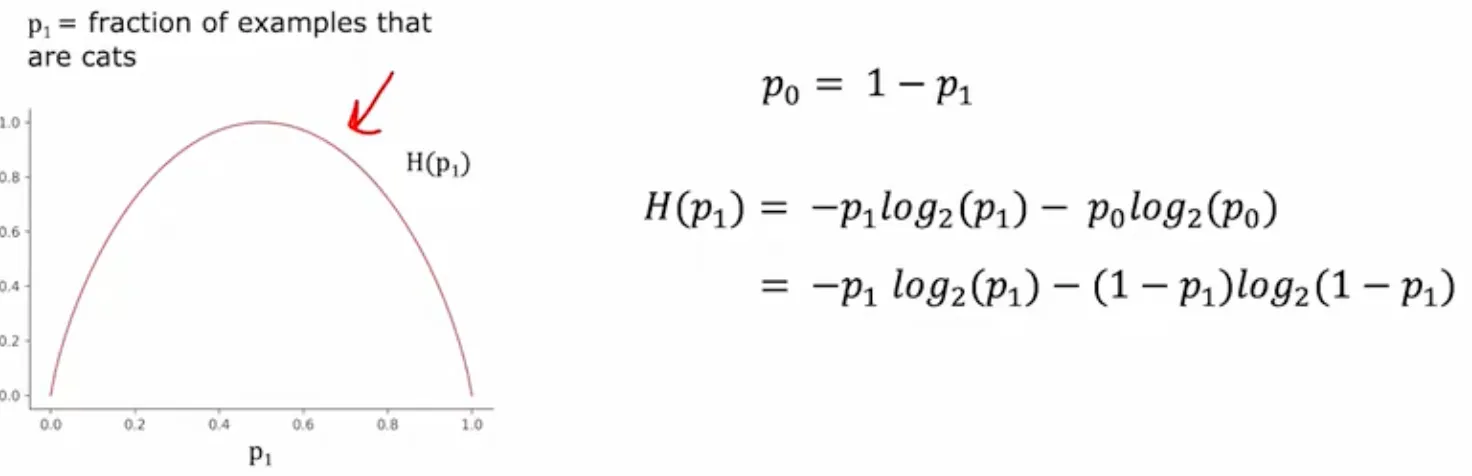
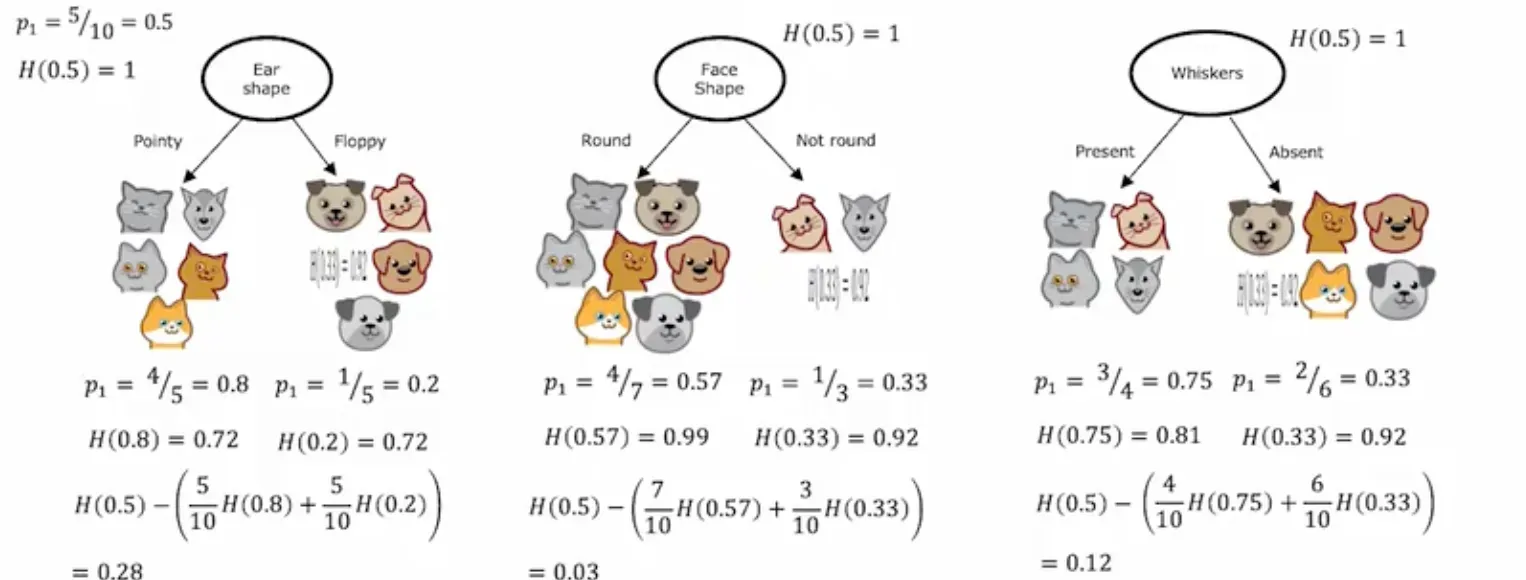
选择信息增益更大的分裂特征

决策树训练(递归)
- Start with all examples at the root node
- Calculate information gain for all possible features, and pick the one with the highest information gain
- Split dataset according to selected feature, and create left and right branches of the tree
- Keep repeating splitting process until stopping criteria is met:
- When a node is 100% one class
- When splitting a node will result in the tree exceeding a maximum depth
- Information gain from additional splits is less than threshold
- When number of examples in a node is below a threshold