Below you will find pages that utilize the taxonomy term “CV”
April 29, 2025
EfficientNet
传统的模型缩放:
任意增加 CNN 的深度或宽度,或使用更大的输入图像分辨率进行训练和评估。
缺点:通常需要长时间的手动调优,并且仍然会经常产生次优的性能。
- 提出了一种新的模型缩放方法和 AutoML 技术,使用使用简单但高效的复合系数,均匀缩放深度/宽度/分辨率的所有维度。
- 使用神经架构搜索来设计一个新的基线网络,并将其扩展以获得一系列模型,称为 EfficientNets。
优点:更小、更快。
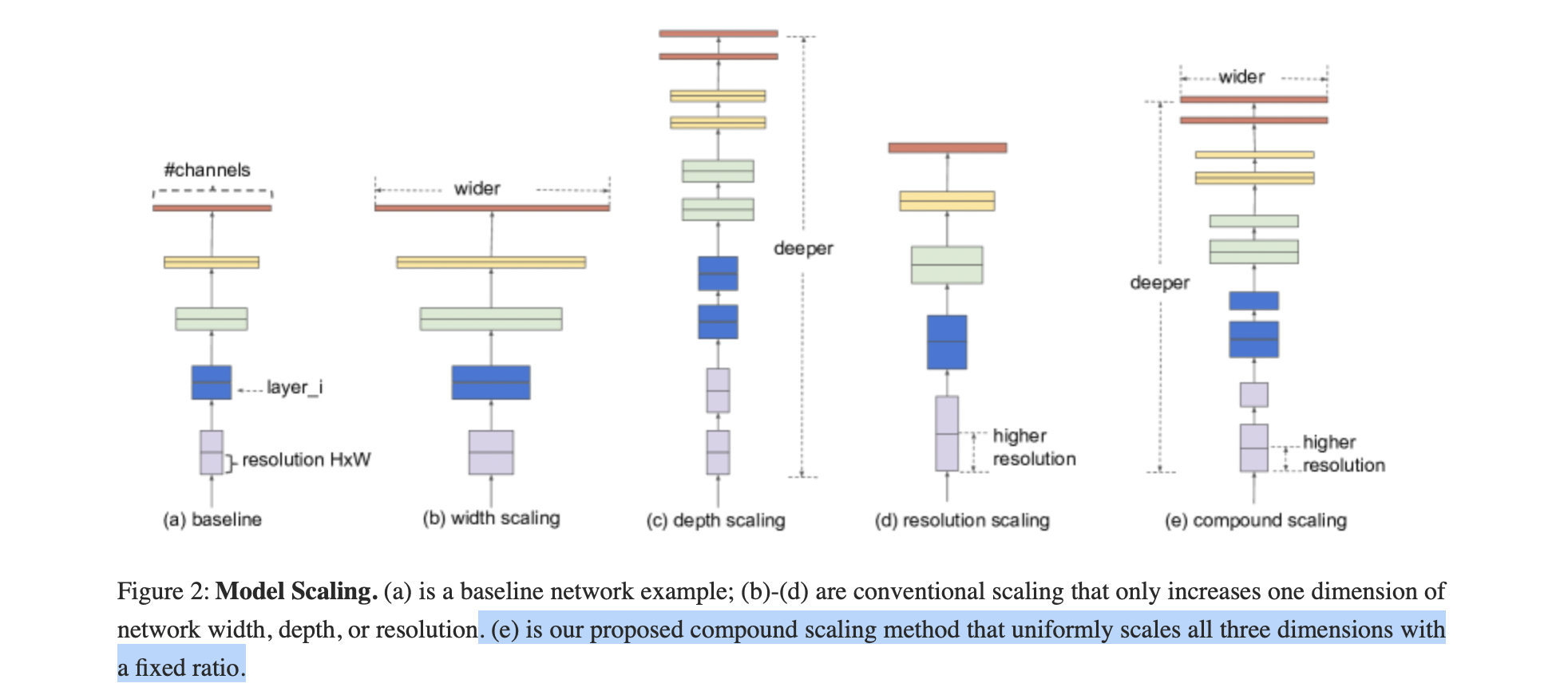
复合模型放缩
1. 概述
目的:找到在固定资源约束下,基线网络的不同缩放维度之间的关系。
April 14, 2025
LSS代码
文章搬运,自用。
论文:Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
官方源码:lift-splat-shoot
Lift, Splat, Shoot图像BEV安装与模型代码详解
对于任意数量不同相机帧的图像直接提取场景的BEV表达;主要由三部分实现:
- Lift:将每一个相机的图像帧根据相机的内参转换提升到 frustum(锥形)形状的点云空间中。
- splate:将所有相机转换到锥形点云空间中的特征根据相机的内参 K 与相机相对于 ego 的外参T映射到栅格化的 3D 空间(BEV)中来融合多帧信息。
- shoot:根据上述 BEV 的检测或分割结果来生成规划的路径 proposal;从而实现可解释的端到端的路径规划任务。
注:LSS在训练的过程中并不需要激光雷达的点云来进行监督。
March 27, 2025
Lift-splat-shoot
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
简单来说,Lift就是预测了一个深度值分布D,以及提取的特征c,然后将两种进行外积操作,实现了增维操作。
**Splat(拍扁)**操作则是使用了一种特殊的“求和池化”操作(z累加,压平),实现降维。
最后的Shooting,则是将预测的一组轨迹投射出来,选取最优的轨迹作为预测结果。
1. 关键:Lift
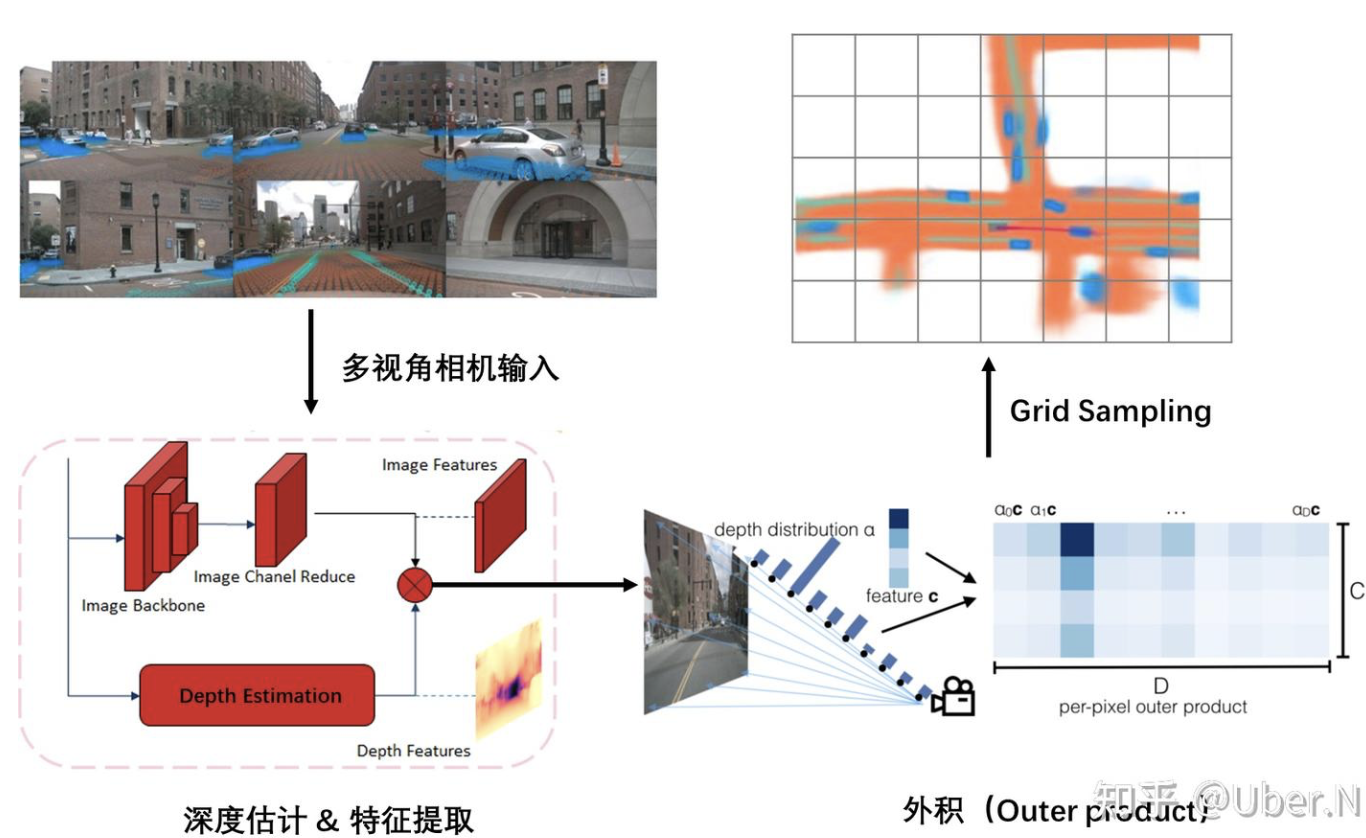
特征提取&深度估计
多视角相机输入后,进行特征提取与深度估计
外积(Outer product)—— 最核心的操作
无法确定每个 pixel 的特征投影 BEV 视角下的具体位置;对于每个 pixel 特征,使用的是“all possible depths”。
使用外积操作,将 Image feature (H * W * C) 和 Depth feature (H * W * D)构造成一个(H * W * D * C) 的 Frustum feature。
February 17, 2025
BEV 论文学习
Vision-Centric BEV Perception: A Survey
许多方法被提出以解决从透视视图(Perspective View, PV)到 BEV 的转换问题,本文将它们分为基于几何、基于深度、基于 MLP 和基于 Transformer 的四类方法。
此外,本文还探讨了 BEV 感知的扩展应用,如多任务学习、多模态融合和语义占据预测等。
1. 背景介绍
BEV 感知的核心任务是将 PV 中的图像序列转换为BEV特征,并在BEV空间中进行感知任务(如3D目标检测和语义地图生成),能够提供精确的定位和绝对尺度信息,便于多视图、多模态和时间序列数据的融合。
但由于摄像头通常安装在车辆上,捕捉到的图像是透视视图,如何将 PV 转换为 BEV 仍然是一个具有挑战性的问题。
3. 主要方法分类
基于几何的方法
- 优势:这类方法主要依赖于逆透视映射(IPM),通过几何变换将 PV 图像转换为 BEV 图像。
- 缺陷:但 IPM 假设地面是平坦的,因此在复杂场景中(如存在高度变化的物体)会产生失真。为了减少失真,一些方法引入了语义信息或使用 GAN 。
基于深度的方法
通过深度估计将 2D 特征提升到 3D 空间,然后通过降维得到 BEV 表示。深度估计可以是显式的(如通过深度图)或隐式的(如通过任务监督)。
- 点云方法:将深度图转换为伪 LiDAR 点云,然后使用 LiDAR 检测器进行 3D 检测
- 体素方法:将 2D 特征映射到 3D 体素空间,并通过体素特征进行 BEV 感知
基于MLP的方法
- 优势:MLP 方法不依赖于摄像头的几何参数,而是通过学习隐式表示来完成视图转换。
- 缺陷:尽管 MLP 具有通用逼近能力,但由于缺乏深度信息和遮挡问题,视图转换仍然具有挑战性。
基于Transformer的方法:
February 9, 2025
MLLM
1基础
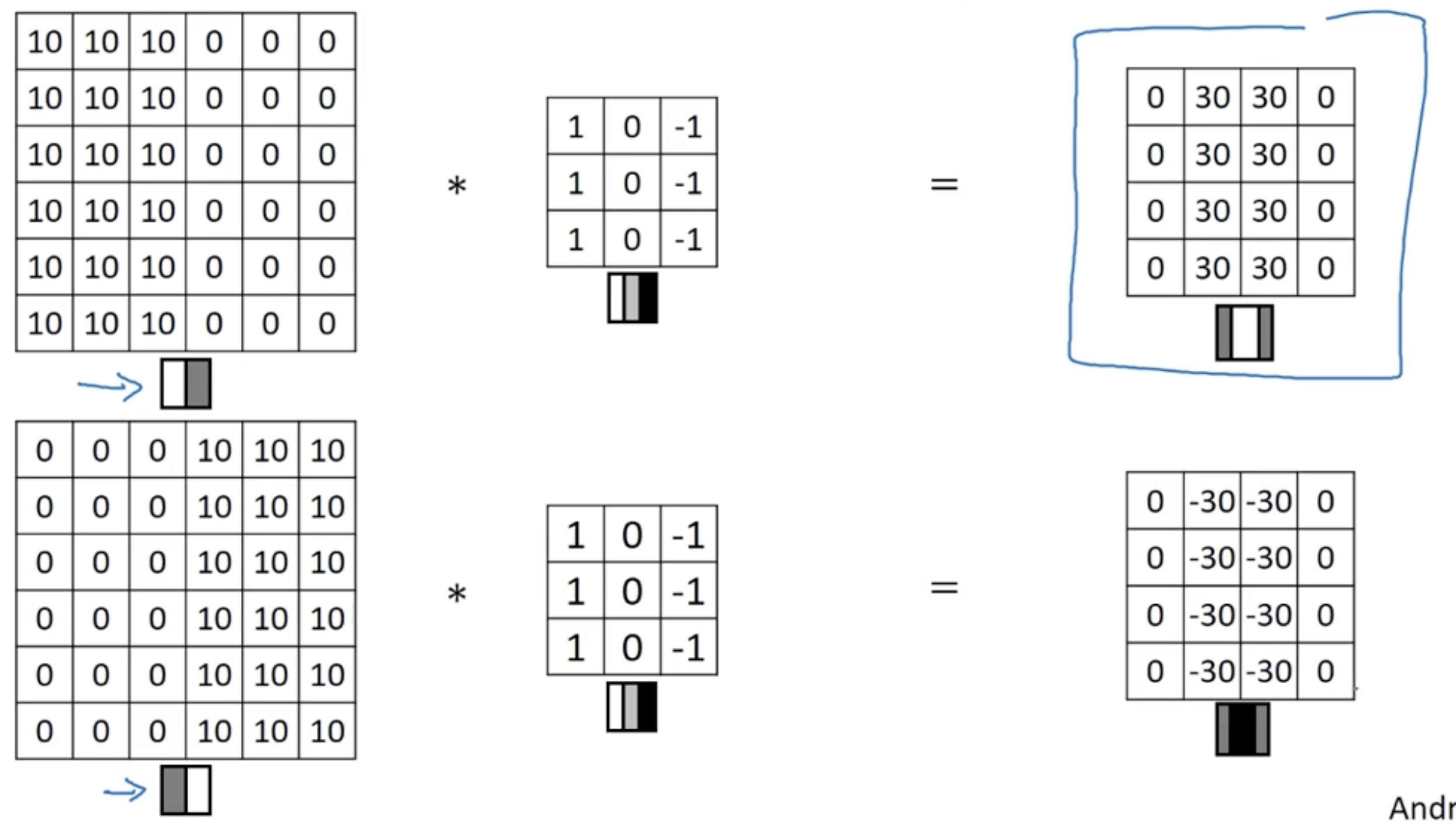
1. 特征提取
一、CV中的特征提取
1. 传统方法(手工设计特征)
(1) 低级视觉特征:颜色、纹理、 边缘与形状…
(2) 中级语义特征:SIFT(尺度不变特征变换)、SURF(加速鲁棒特征)、LBP(局部二值模式)…
2. 深度学习方法(自动学习特征)
(1) 卷积神经网络(CNN)
核心思想:通过卷积层提取局部特征,池化层降低维度,全连接层进行分类。
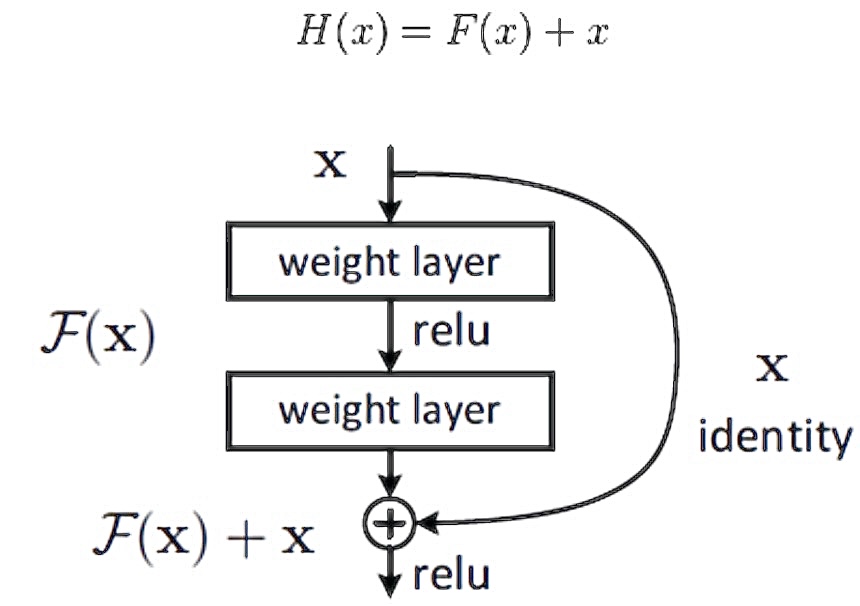
经典模型:LeNet-5、AlexNet、VGGNet、ResNet(使用残差可以训练更深的网络)…

(2) 视觉Transformer(ViT)
- 核心思想:将图像分割为小块(patches),通过自注意力机制建模全局关系。
- 优势:无需局部卷积先验,直接建模长距离依赖; 在ImageNet等任务上超越传统CNN。
January 31, 2025
目标检测
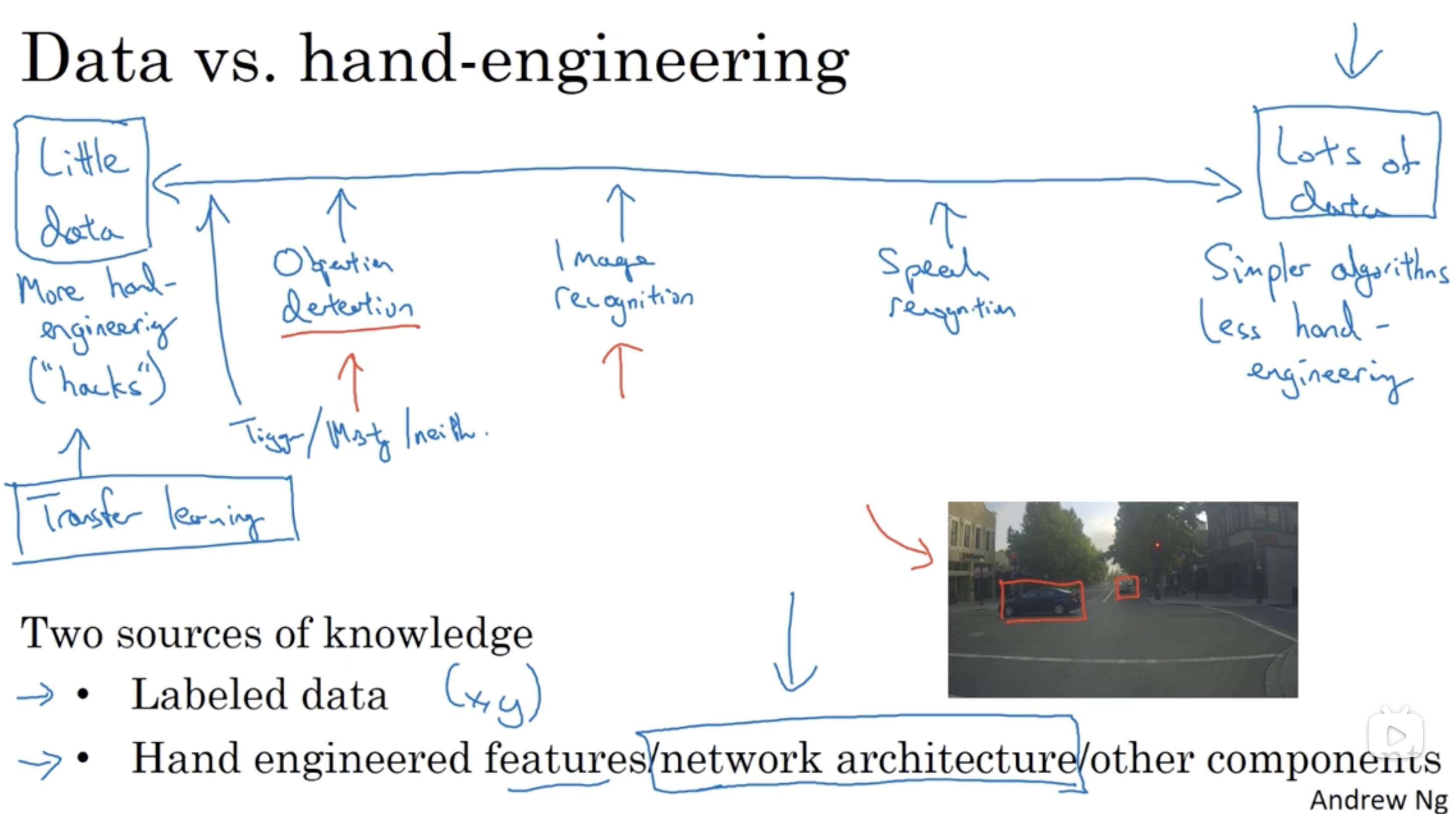
技巧
Ensembling:Train several networks independently and average their outputs Multi-crop at test time:Run classifier on multiple versions of test images and average results
定位
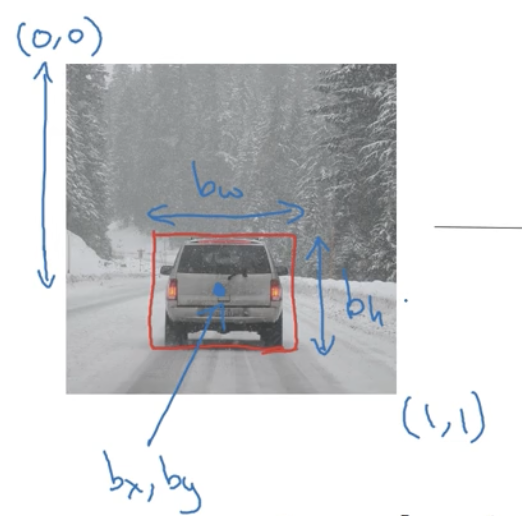
Need to output bx, by, bn, bw, class label (1-4)

需人工标注特征点的坐标
基于滑动窗口的目标检测算法
- 先训练卷积网络识别物体
- 滑动+放大窗口+再次滑动
问题:计算效率大,慢