Below you will find pages that utilize the taxonomy term “Data Processing”
April 17, 2025
工具链-PyTorch
1. 处理数据
PyTorch 有两个用于处理数据的基元: torch.utils.data.DataLoader 和 torch.utils.data.Dataset。
Dataset 存储样本及其相应的标签,DataLoader 将 Dataset 包装成一个迭代器。
下面以 TorchVision 库模块里的 FashionMNIST 数据集为例:
每个 TorchVision
Dataset都包含两个参数:transform和target_transform分别修改样本和标签
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
将 Dataset 作为参数传递给 DataLoader ,将一个可迭代对象包装在数据集上,支持自动批处理、采样、洗牌和多进程数据加载。
定义了一个 batch size 为 64,即 dataloader 迭代器中的每个元素将返回一个 64 features and labels 的 batch。
April 11, 2025
数据集-NuSences
内容
nuScenes 包含 1000 个场景,大约 1.4M 的相机图像、390k LIDAR 扫描、1.4M 雷达扫描和 40k 关键帧中的 1.4M 对象边界框。
nuScenes-lidarseg 包含 40000 个点云和 1000 个场景(850 个用于训练和验证的场景,以及 150 个用于测试的场景)中的 14 亿个注释点。
数据采集
车辆设置
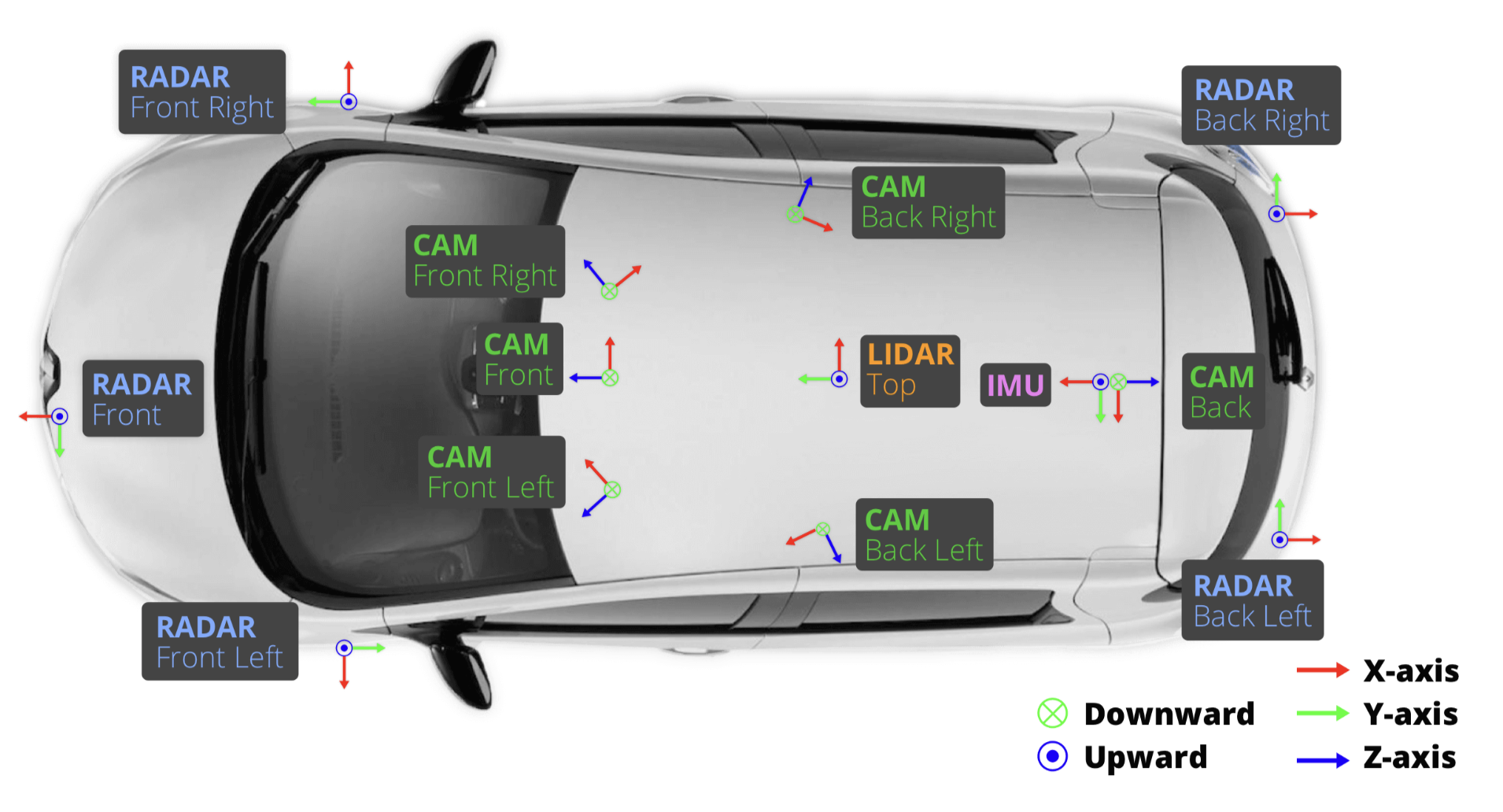
- 1 个旋转激光雷达 (Velodyne HDL32E)
- 5 个远程雷达传感器 (Continental ARS 408-21)
- 6 个相机 (Basler acA1600-60gc)
- 1个 IMU & GPS (高级导航空间版)
Sensor(传感器)校准 - 内外参
- LIDAR extrinsics
- 相机 extrinsics
- RADAR extrinsics
- 相机 intrinsic 校准
Sensor(传感器)同步
实现跨模态数据对齐:当顶部 LIDAR 扫描相机 FOV 的中心时,会触发相机的曝光