Below you will find pages that utilize the taxonomy term “Inference”
July 19, 2025
SGLang
优势:后端运行快速、前端语言灵活、模型支持广泛、社区活跃。
SGLang 的核心是通过其 Python API 构建和执行 Language Model Program。
启动服务器
import sglang as sgl
# 配置 SGLang 运行时
# 如果在本地运行服务,这里指定服务地址和端口
# 如果直接在 Python 进程中加载模型 (需要安装 sglang[srt]),可以使用 sgl.init("model_path")
# 假设此时服务已在本地 30000 端口启动,并加载了模型:
sgl.init("http://127.0.0.1:30000")
# 或者,如果在 Python 进程中直接加载模型(需要足够的显存)
# sgl.init("meta-llama/Llama-3.1-8B-Instruct") # 使用 Hugging Face ID
# 或者
# sgl.init("/path/to/your/model_dir") # 使用本地模型路径
定义和运行一个简单的生成任务
sgl.Runtime()是 LM 程序的入口。import sglang as sgl # 假设已经通过 sgl.init(...) 初始化了运行时 # 定义一个 LM Program @sgl.function def simple_gen(s, query): s += f"用户问:{query}\n" # 使用 sgl.gen() 进行文本生成 s += "回答:" + sgl.gen("answer", max_tokens=64) # 使用 sgl.gen() 进行文本生成
July 19, 2025
vLLM
vLLM 是一个专门用于高效运行大语言模型的 Python 库。
KV Cache
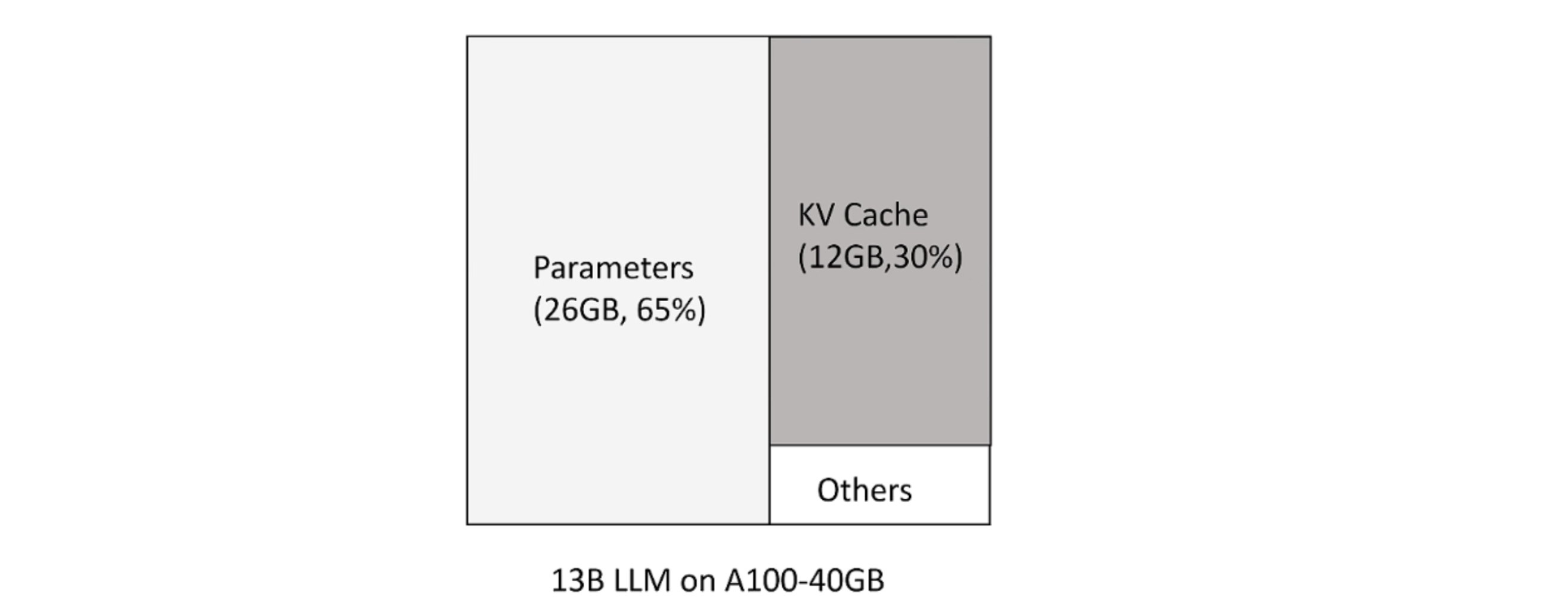
大模型推理时 huggingface 按照可生成最长序列长度分配显存。但这造成三种类型的浪费:
- 预分配最大的 token 数,但不会用到。
- 剩下的 token 还尚未用到,但现存已被预分配占用。
- 显存之间的间隔碎片,因为 prompt 之间不同,显存不足以预分配给下一个文本生成。
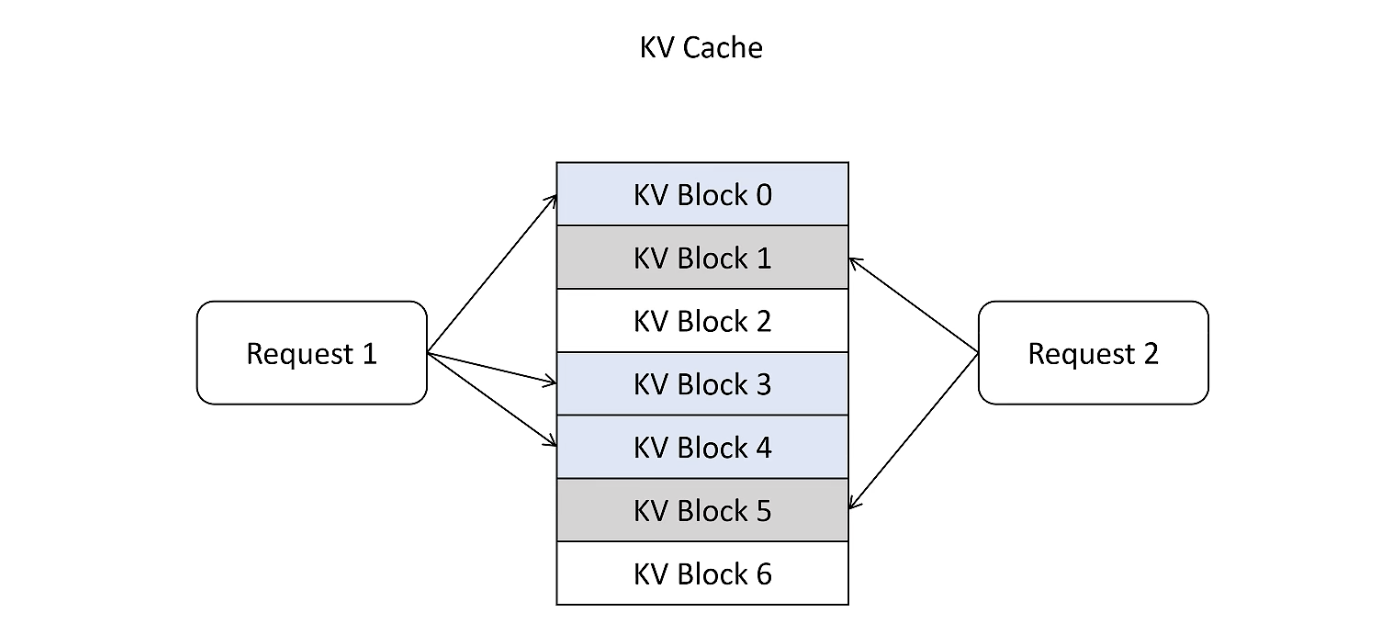
新 token 只用到前面 token 的 kv 向量,事实上只需保存之前的 kv 向量。
Page Attention
借鉴 OS 中的虚拟内存和页管理技术,把显存划分为 KVBlock,显存按照 KVBlock 来管理 KVCache,不用提前分配。