Below you will find pages that utilize the taxonomy term “Langchain”
June 24, 2025
langchain - 混合搜索
先通过BM25快速筛选关键字,再用Reranker对候选文档进行精细排序。
def keyword_and_reranking_search(query, top_k=3, num_candidates=10):
print("Input question:", query)
##### BM25 search (lexical search) #####
bm25_scores = bm25.get_scores(bm25_tokenizer(query))
top_n = np.argpartition(bm25_scores, -num_candidates)[-num_candidates:] # 选取分数最高的 num_candidates 个文档
bm25_hits = [{'corpus_id': idx, 'score': bm25_scores[idx]} for idx in top_n]
bm25_hits = sorted(bm25_hits, key=lambda x: x['score'], reverse=True)
print(f"Top-3 lexical search (BM25) hits")
for hit in bm25_hits[0:top_k]:
print("\t{:.3f}\t{}".format(hit['score'], texts[hit['corpus_id']].replace("\n", " ")))
#Add re-ranking
docs = [texts[hit['corpus_id']] for hit in bm25_hits]
print(f"\nTop-3 hits by rank-API ({len(bm25_hits)} BM25 hits re-ranked)")
results = co.rerank(query=query, documents=docs, top_n=top_k, return_documents=True)
for hit in results.results:
print("\t{:.3f}\t{}".format(hit.relevance_score, hit.document.text.replace("\n", " ")))
bm25
基于词频和逆文档频率,计算每个文档与查询的关键词匹配分数。
June 23, 2025
langchain - text_splitter
import os
from langchain.text_splitter import (
CharacterTextSplitter,
RecursiveCharacterTextSplitter,
SentenceTransformersTokenTextSplitter,
TextSplitter,
TokenTextSplitter,
)
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Define the directory containing the text file
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir, "books", "romeo_and_juliet.txt")
db_dir = os.path.join(current_dir, "db")
# Check if the text file exists
if not os.path.exists(file_path):
raise FileNotFoundError(
f"The file {file_path} does not exist. Please check the path."
)
# Read the text content from the file
loader = TextLoader(file_path)
documents = loader.load()

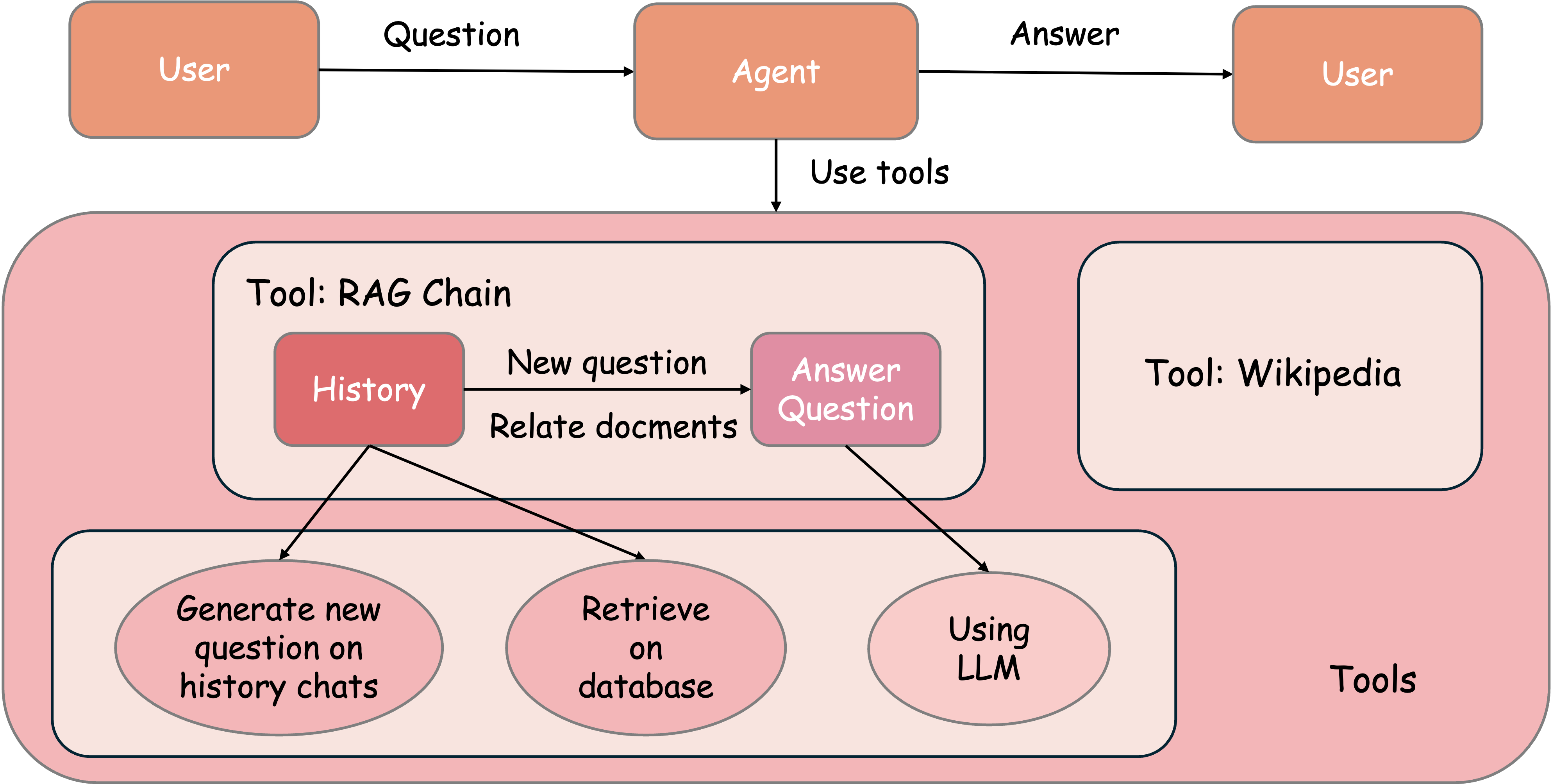
June 19, 2025
langchain - RAG

import os
from dotenv import load_dotenv
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import Chroma
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Load environment variables from .env
load_dotenv()
# Define the persistent directory
current_dir = os.path.dirname(os.path.abspath(__file__))
persistent_directory = os.path.join(current_dir, "db", "chroma_db_with_metadata")