Below you will find pages that utilize the taxonomy term “Paper”
July 27, 2025
「论文阅读」RAG 文献调研
评估
RagChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Introduction
评估 RAG 系统的难点
- 模块化复杂
- 指标限制
- 检索器:传统指标(如 recall@k 和 MRR)依于 带注释的分块 和 严格的分块方式,忽视了知识库的完整语义范围
- 生成器:典型度量(如,基于 n-gram 的方法(如BLEU 和 ROUGE)、基于嵌入的方法(例如,BERTScore)和基于 LLM 的方法等)等可处理简单回答,但无法在较长的响应中检测到更精细的区别。
- 指标可靠性
对比其他(RAGAS、TruLens、ARES、RGB、RECALL、NoMIRAC),RagChecker 能 从人类角度评估 RAG 系统质量和可靠性方面的有效性,对错误来源做分析。
Related Work
现有评估可分为两种方法:仅评估 generators 的基本功能 和 评估 RAG 系统的端到端性能。
July 27, 2025
Triton Prompt
AutoTriton
TritonBench Infer Prompt
SYS_INSTRUCTION = """Use triton language write a kernel and wrapper according to the following instruction:
"""
INSTRUCTION_EXTRA = """The wrapper function should have same input and output as in instruction, and written with 'def xxx' DIRECTLY, do not wrap the wrapper inside a class. You may write it as:
```python
@triton.jit
def kernel([parameters]):
# your implementation
def wrapper ([parameters]):
# your implementation
```
"""
prompt = f"""{SYS_INSTRUCTION}
{ORIGINAL_INSTRUCTION}
{INSTRUCTION_EXTRA}
"""
KernelBench Infer Prompt
PROBLEM_STATEMENT = """You are given a pytorch function, and your task is to write the same triton implementation for it.
The triton implementation should change the name from Model to ModelNew, and have same input and output as the pytorch function."""
PROBLEM_INSTRUCTION = """Optimize the architecture with custom Triton kernels! Name your optimized output architecture ModelNew. Output the new code in codeblocks. Please generate real code, NOT pseudocode, make sure the code compiles and is fully functional. Just output the new model code, no input and init function, no other text, and NO testing code! **Remember to Name your optimized output architecture ModelNew, do not use Model again!**"""
prompt = f"""{PROBLEM_STATEMENT}
{PROBLEM_INSTRUCTION}
Now, you need to write the triton implementation for the following pytorch code:
```
{arc_src}
```
"""
CUDA- L1
SFT
Task for CUDA Optimization
You are an expert in CUDA programming and GPU kernel optimization. Now you’re tasked with developing a
high-performance cuda implementation of Softmax. The implementation must:
• Produce identical results to the reference PyTorch implementation.
• Demonstrate speed improvements on GPU.
• Maintain stability for large input values.
Reference Implementation (exact copy)
import torch
import torch.nn as nn
class Model(nn.Module):
"""
Simple model that performs a Softmax activation.
"""
def __init__(self):
super(Model, self).__init__()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Applies Softmax activation to the input tensor.
Args:
x (torch.Tensor): Input tensor of shape (batch_size, num_features).
Returns:
torch.Tensor: Output tensor with Softmax applied, same shape as input.
"""
return torch.softmax(x, dim=1)
batch_size = 16
dim = 16384
def get_inputs():
x = torch.randn(batch_size, dim)
return [x]
def get_init_inputs():
RL
July 27, 2025
显卡
1. 消费级显卡(GeForce RTX系列)
适合个人研究者、小规模训练或微调,性价比较高,但显存较小,不适合超大规模模型。
- RTX 4090
- CUDA核心:16,384
- 显存:24GB GDDR6X
- 适合:单卡训练中等规模模型(如LLaMA-7B/13B微调)。
- RTX 4080/4080 Super
- 显存:16GB GDDR6X
- 适合:小规模模型或推理。
- RTX 3090/3090 Ti
- 显存:24GB GDDR6X(二手市场常见,性价比高)。
- RTX 6000 Ada Generation(工作站级)
- 显存:48GB GDDR6(ECC支持),适合需要大显存的场景。
注意:消费级显卡通常无ECC显存校验,且多卡并行效率低于专业卡。
2. 专业级显卡(NVIDIA RTX/Tesla系列)
针对数据中心和企业级训练,支持多卡高速互联(NVLink)、ECC显存等特性。
- RTX 5000/6000 Ada
- 显存:32GB~48GB GDDR6,支持NVLink,适合中等规模训练。
- Tesla V100(Volta架构)
- 显存:16GB/32GB HBM2(32GB版更受欢迎)。
- 支持Tensor Core(混合精度训练),曾是早期Transformer模型的标配。
- Tesla A100(Ampere架构)
- 显存:40GB/80GB HBM2e(带宽1555GB/s)。
- 支持NVLink 3.0(多卡互联带宽600GB/s),适合大规模分布式训练。
- Tesla H100(Hopper架构)
- 显存:80GB HBM3(带宽3TB/s)。
- 支持Transformer引擎(加速LLM训练),性能较A100提升数倍。
3. 数据中心级显卡(计算加速卡)
专为AI训练和HPC设计,通常需搭配服务器使用。
- A100 80GB
- 行业标杆,支持多实例GPU(MIG),可分割为多个计算单元。
- H100
- PCIe版和SXM版(后者性能更强),适合LLM训练(如GPT-4级别模型)。
- B100/B200(2024年发布)
- 下一代AI加速卡,预计性能较H100再提升。
4. 特殊用途显卡
- DGX系统:英伟达预配置的AI服务器,如DGX A100(8×A100)、DGX H100。
- Grace Hopper超级芯片:CPU+GPU集成设计,针对超大规模AI优化。
选择建议
- 入门/个人学习:RTX 3090/4090(24GB显存可微调中小模型)。
- 中小团队:A100 40GB(二手)或RTX 6000 Ada(48GB)。
- 企业级训练:H100集群或A100/H100多卡服务器(需NVLink支持)。
关键参数对比
| 显卡型号 | 架构 | 显存容量 | 显存类型 | NVLink支持 | 典型用途 |
|---|---|---|---|---|---|
| RTX 4090 | Ada | 24GB | GDDR6X | 无 | 个人研究/小规模训练 |
| A100 80GB | Ampere | 80GB | HBM2e | 是 | 大规模分布式训练 |
| H100 80GB | Hopper | 80GB | HBM3 | 是 | LLM训练/超算 |
| RTX 6000 Ada | Ada | 48GB | GDDR6 | 是 | 工作站级训练 |
如果需要更具体的推荐(如预算、模型规模),可以进一步补充信息!
July 20, 2025
「源码阅读」KernelBench
任务描述
构建 KernelBench 有 4 个级别的任务:
- Level 1 🧱: 单核算子(100 个问题),如卷积、矩阵乘法、层归一化
- Level 2 🔗: 简单融合模式(100 个问题),如 Conv + Bias + ReLU,Matmul + Scale + Sigmoid
- Level 3 ⚛️: 端到端全模型架构(50个问题),如MobileNet、VGG、MiniGPT、Mamba)
- Level 4 🤗: Hugging Face 优化过的整个模型架构
评估方法
正确性检查✅:确保模型生成的 kernel 在功能上与参考实现(如 PyTorch 的官方算子)完全一致。进行
n_correctness次测试。性能评估⏱️:验证生成的 kernel 是否比参考实现更高效。重复
n_trial次消除偶然误差。指标是加速比。
实现代码位于: src/eval.py
评估脚本: scripts/run_and_check.py
总基准指标
fast_p:既正确又加速大于阈值的任务的分数p。提高加速阈值p可使任务更具挑战性。加速比:PyTorch 参考实现运行时间 与 生成的内核时间 之比。
计算整体基准测试性能脚本: scripts/greedy_analysis.py
July 20, 2025
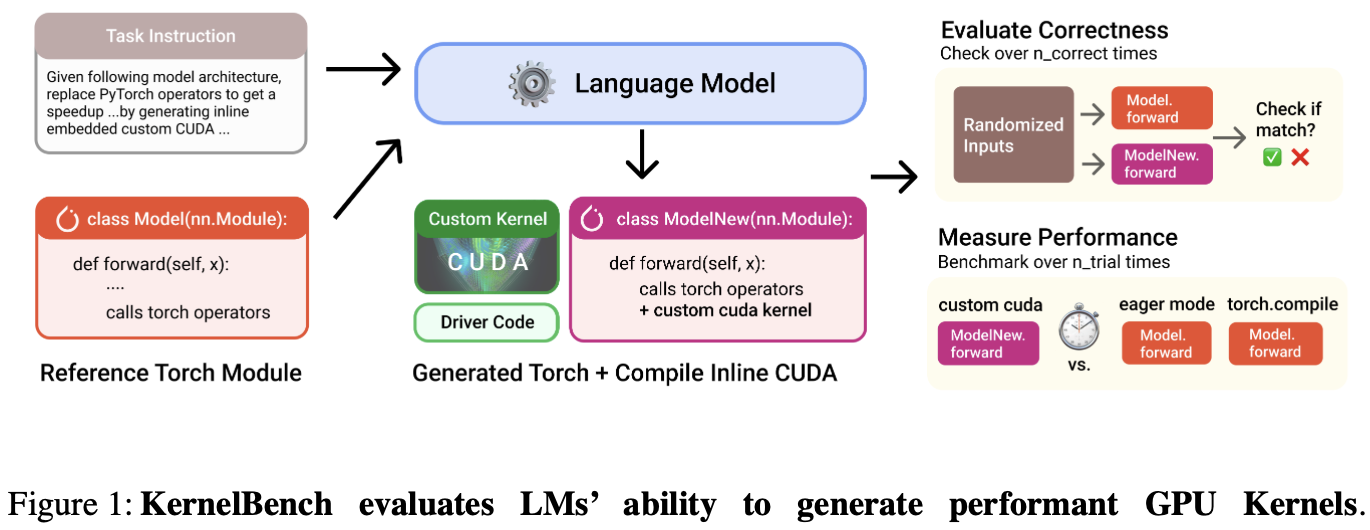
「论文阅读」KernelBench
KernelBench 是一个评估 LLMs 在生成高性能 GPU 内核代码上能力的基准测试框架。论文引入了新评估指标 fast_p:衡量生成的 正确、且速度提升超过阈值p 的内核的比例。
Introduction
背景:每个硬件都有不同的规格和指令集,跨平台移植算法是痛点。
论文核心探讨:LM 可以帮助编写正确和优化的内核吗?
KernelBench 的任务:让 LMs 基于给定的 PyTorch 目标模型架构,生成优化的 CUDA 内核;并进行自动评估。
环境要求
自动化 AI 工程师的工作流程。
支持多种 AI 算法、编程语言和硬件平台。
轻松评估 LM 代的性能和功能正确性,并从生成的内核中分析信息。
测试级别
Individual operations::如 AI 运算符、包括矩阵乘法、卷积和损失。
Sequence of operations:评估模型融合多个算子的能力。
端到端架构:Github 上流行 AI 存储库中的架构。
工作流程
July 7, 2025
GraphRAG
特点
- 基于图的检索:GraphRAG 引入知识图谱来捕捉实体、关系及其他重要元数据。
- 层次聚类:GraphRAG 使用 Leiden 技术进行层次聚类,将实体及其关系进行组织。
- 多模式查询:支持多种查询模式。
- 全局搜索:利用社区总结来进行全局性推理。
- 局部搜索:通过扩展相关实体的邻居和关联概念来进行具体实体的推理。
- DRIFT 搜索:结合局部搜索和社区信息,提供更准确和相关的答案。
- 图机器学习:集成图机器学习技术,并提供来自结构化和非结构化数据的深度洞察。
- Prompt 调优:提供调优工具,帮助根据特定数据和需求调整查询提示,提高结果质量。
工作流程
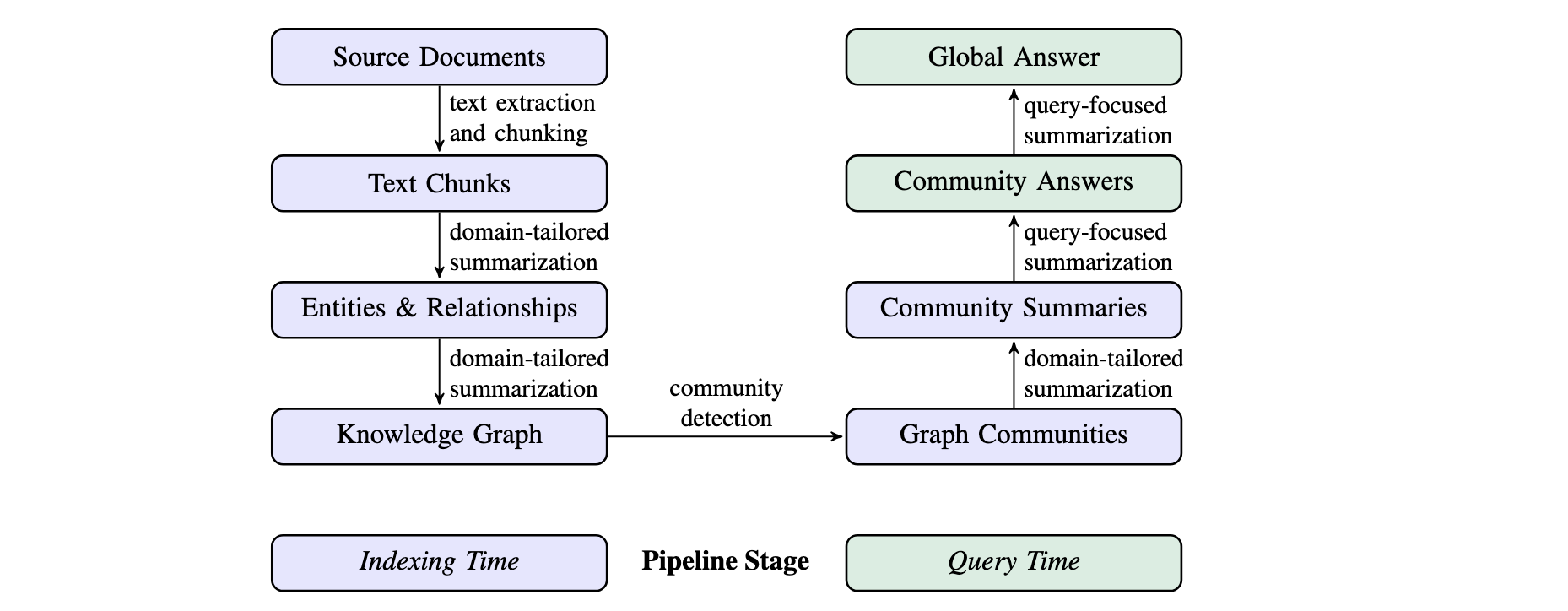
1 索引 (Indexing) 过程
将原始文档转化为知识图谱
July 2, 2025
「论文阅读」Triton LLM
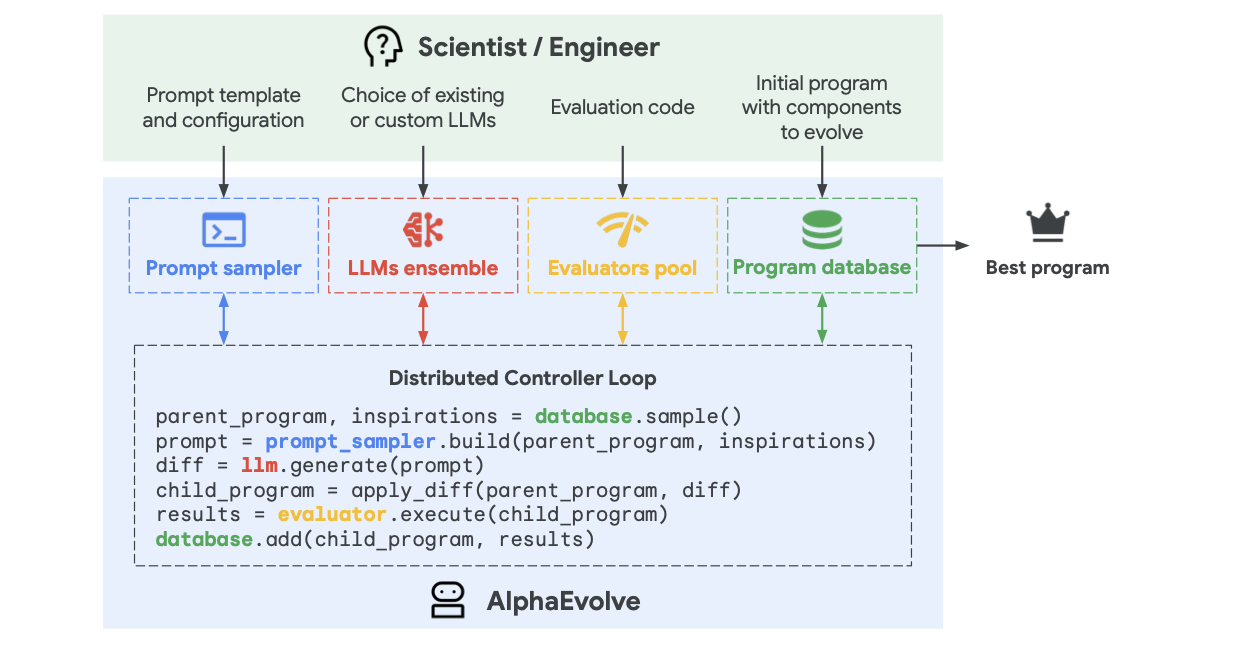
AlphaEvolve: A coding agent for scientific and algorithmic discovery
AlphaEvolve 使用进化方法,不断接收来自一个或多个评估者的反馈,迭代改进算法,从而有可能带来新的科学和实践发现。
Introduction
AlphaEvolve represents the candidates (for example, new mathematical objects or practical heuristics) as algorithms and uses a set of LLMs to generate, critique, and evolve a pool of such algorithms.

AlphaEvolve
June 25, 2025
「论文阅读」Kimi-Researcher
这篇技术报告提出了完全通过端到端 agentic reinforcement learning 进行训练的自主智能体 Kimi-Researcher,旨在通过多步骤规划、推理和工具使用来解决复杂问题。
—— End-to-end agentic RL is promising but challenging
传统 agent
- 基于工作流:需要随着模型或环境的变化而频繁手动更新,缺乏可扩展性和灵活性。
- 使用监督微调 (SFT)进行模仿学习:在数据标记方面存在困难;特定的工具版本紧密耦合。
Kimi-Researcher:给定一个查询,agent 探索大量可能的策略,获得正确解决方案的奖励 —— 所有技能(规划、感知和工具使用)都是一起学习的,无需手工制作的rule/workflow。
建模
给定状态观察(如系统提示符、工具声明和用户查询),Kimi-Researcher 会生成 think和action (action 可以是工具调用,也可以是终止轨迹的指示)。

Approach
主要利用三个工具:a)并行、实时、内部的 search tool; b) 用于交互式 Web 任务的基于文本的 browser tool; c)用于自动执行代码的 coding tool.
May 14, 2025
「论文阅读」Augmented Knowledge Graph Querying leveraging LLMs
这篇论文引入了一个名为 SparqLLM 的框架,通过结合 RAG 与 LLM,实现了从自然语言到 SPARQL 查询的自动生成,以简化知识图谱的查询过程。
1 Introduction
背景:非技术员工不懂 SPARQL;KG + LLMs 无法生成精确高效的 SPARQL 查询,且存在幻觉问题。
SparqLLM:被设计为 RAG 框架,可自动从自然语言问题生成 SPARQL 查询,同时生成最适当的数据可视化以返回获得的结果。
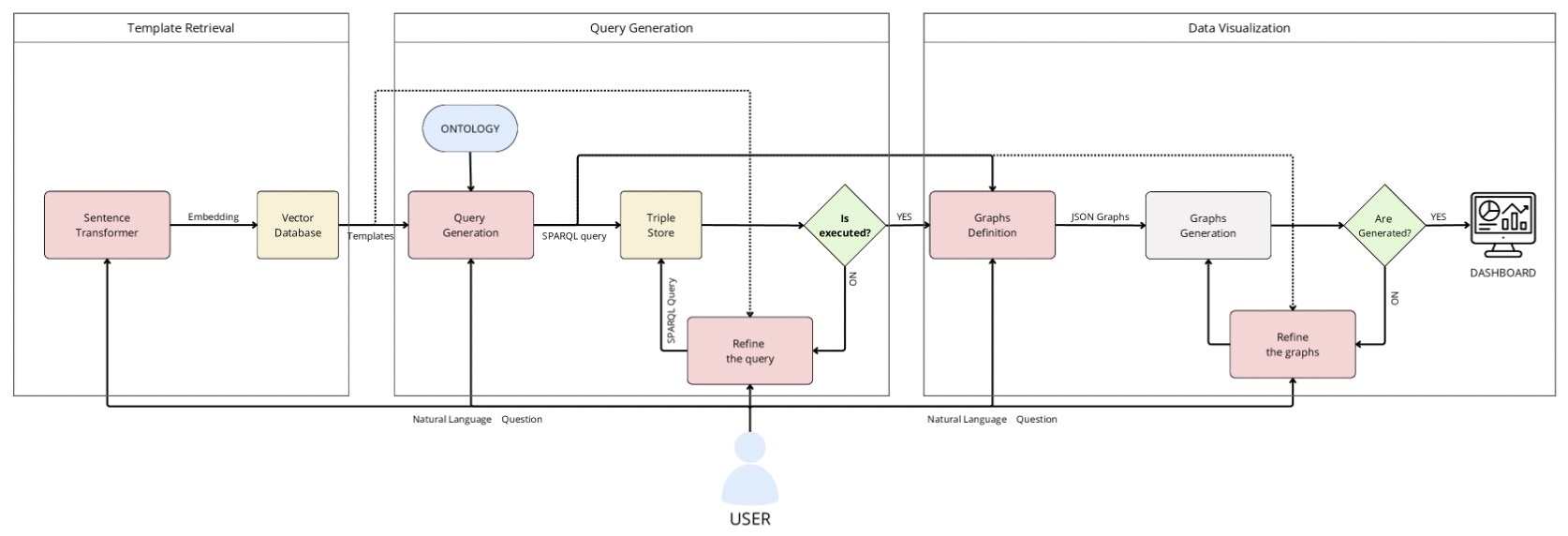
目标:提高 KG 的准确性、可用性和可靠性,实现与语义数据的更直观和有效的交互。
2 Related Work
自然语言接口 (NLI):将非结构化输入转换为 SPARQL 等正式查询语言,使非技术用户更容易访问基于 RDF 的知识图谱。
LLMs:利用它们处理和生成复杂文本的能力,为自动生成查询提供了一个强大的框架,减少了人工干预的需要,使非专家用户也能访问知识图谱。
基于模板的方法:通过为查询生成提供确定性框架来补充上述方法。
May 14, 2025
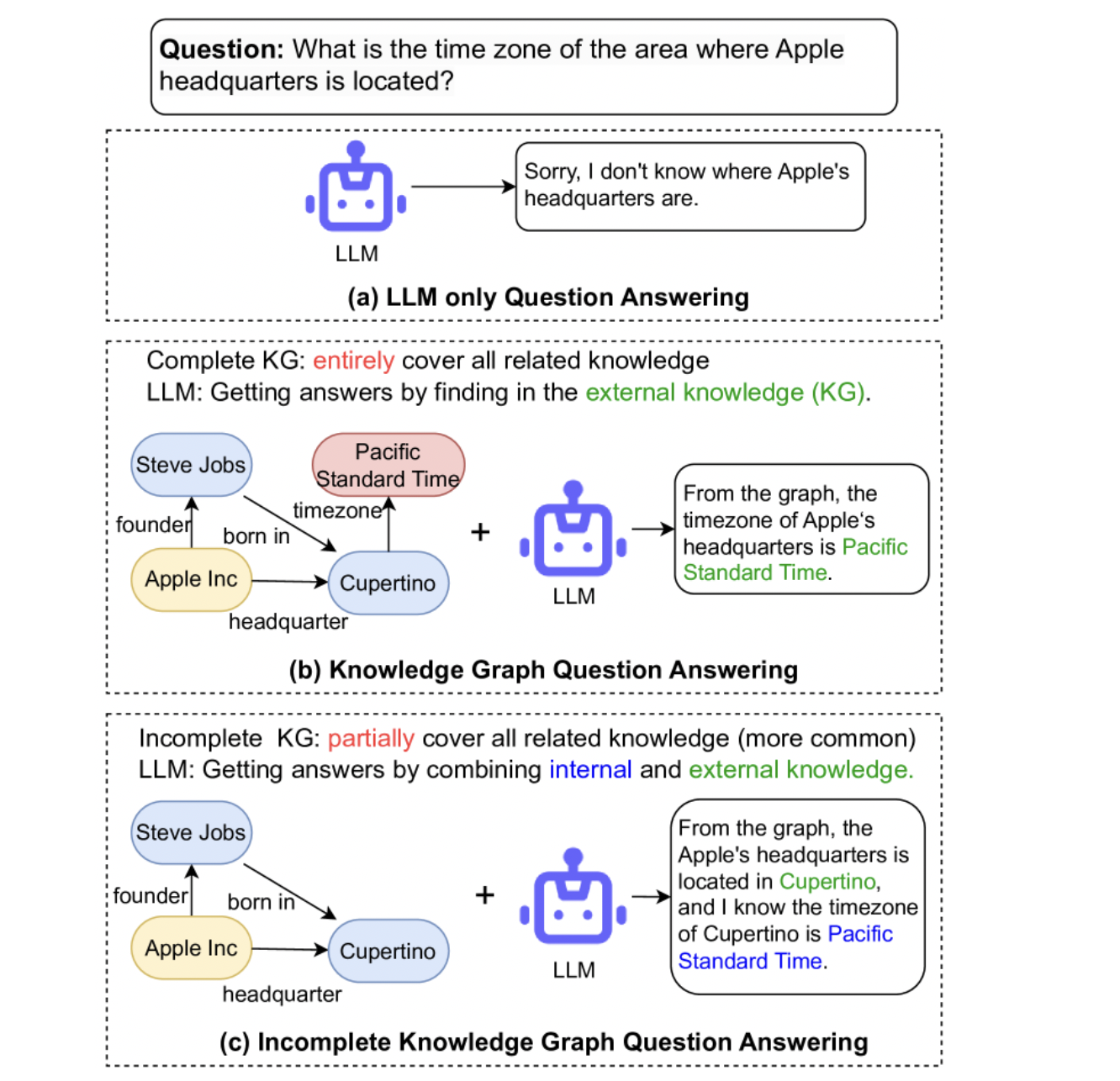
「论文阅读」Generate-on-Graph: Treat LLM as both Agent and KG for Incomplete Knowledge Graph Question Answering
这篇论文提出了一种称为 Generate-on-Graph(GoG) 的免训练方法,它可以在探索 KG 时,生成新的事实三元组。
具体来说,在不完全知识图谱(IKGQA) 中,GoG 通过 Thinking-Searching-Generating 框架进行推理,它将 LLM 同时视为 Agent 和 KG。
1 Introduction