Below you will find pages that utilize the taxonomy term “Pytorch”
July 14, 2025
分布式并行训练 - FSDP
Fully Sharded Data Parallel
DDP 回顾
名词解释
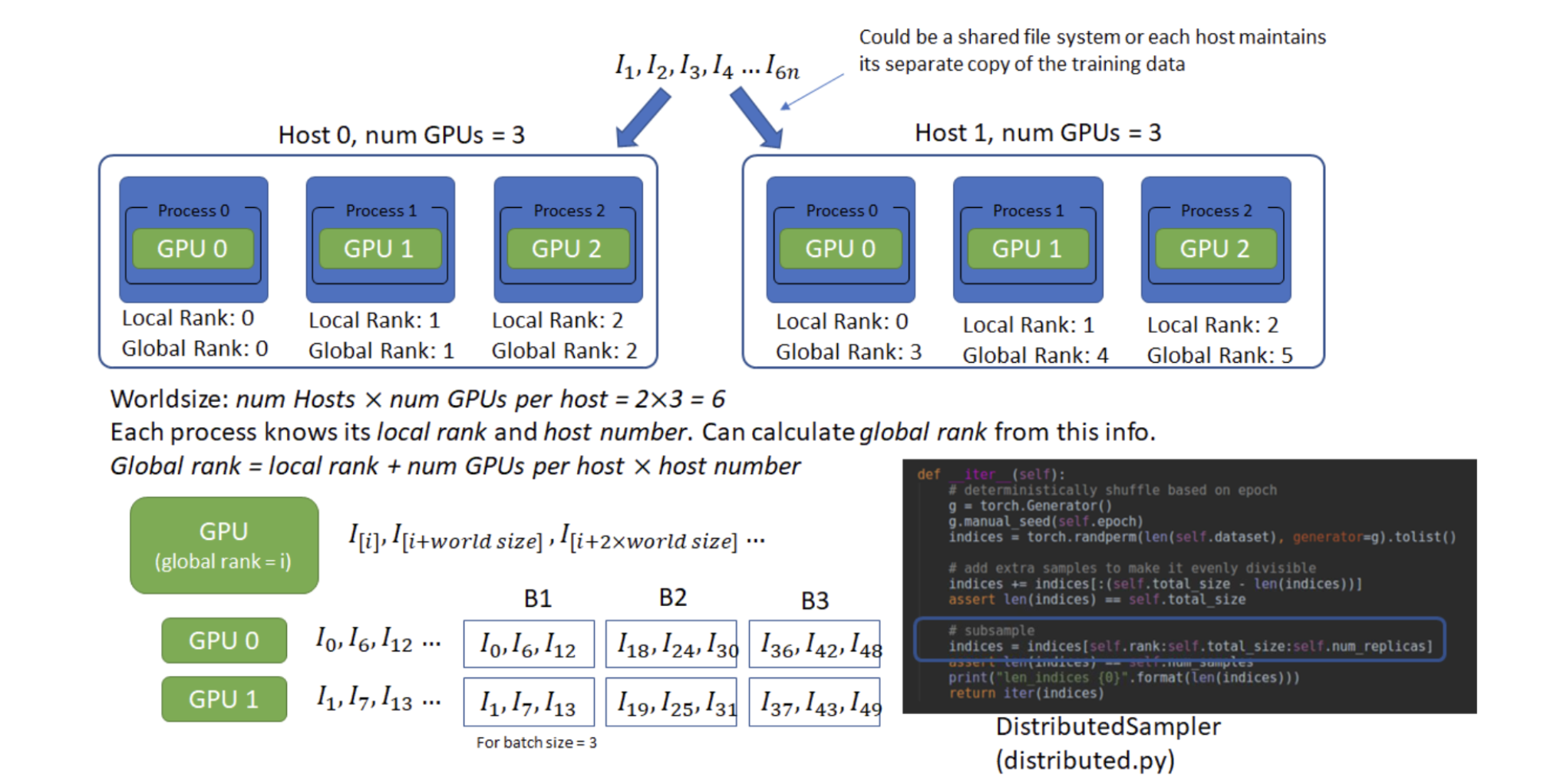
Host:可以理解为⼀台主机,每个主机有⾃⼰的IP地址,⽤于通信。
Local Rank:每个主机上,对不同GPU设备的编。
Global Rank:全局的GPU设备编号,Global Rank = Host * num GPUs per host + Local Rank。
Worldsize:总的GPU个数。num Hosts * num GPUs per host
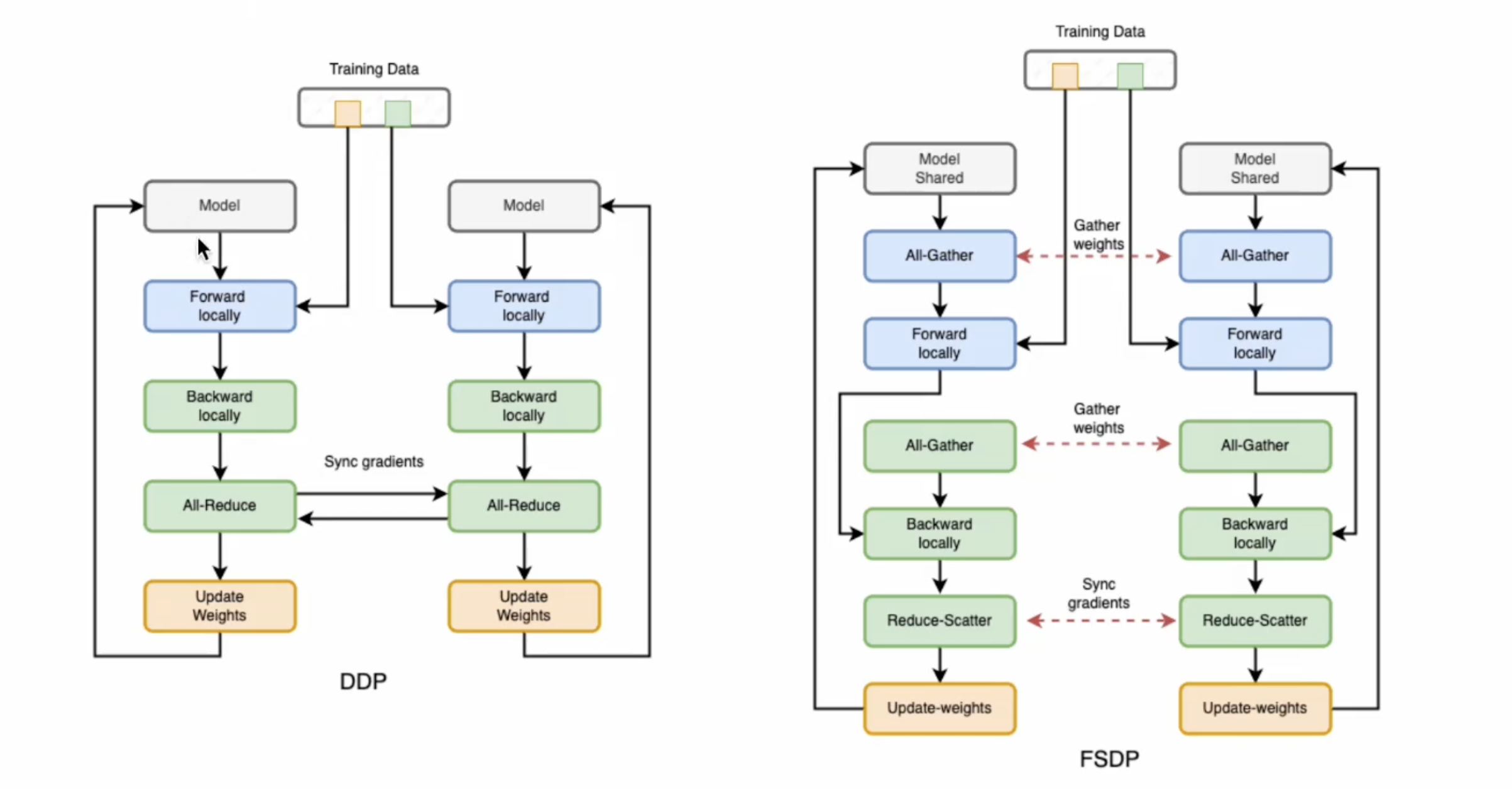
DDP 参数更新过程
July 11, 2025
分布式并行训练 - DDP
分布式训练将训练工作负载分散到多个工作节点,因此可以显著提高训练速度和模型准确性。
Distributed Data Parallel
- 为什么用 Distributed Training? 节约时间、增加计算量、模型更快。
- 如何实现?
- 在同一机器上使用多个 GPUs
- 在集群上使用多个机器
什么是DDP?
即在训练过程中内部保持同步:每个 GPU 进程仅数据不同。
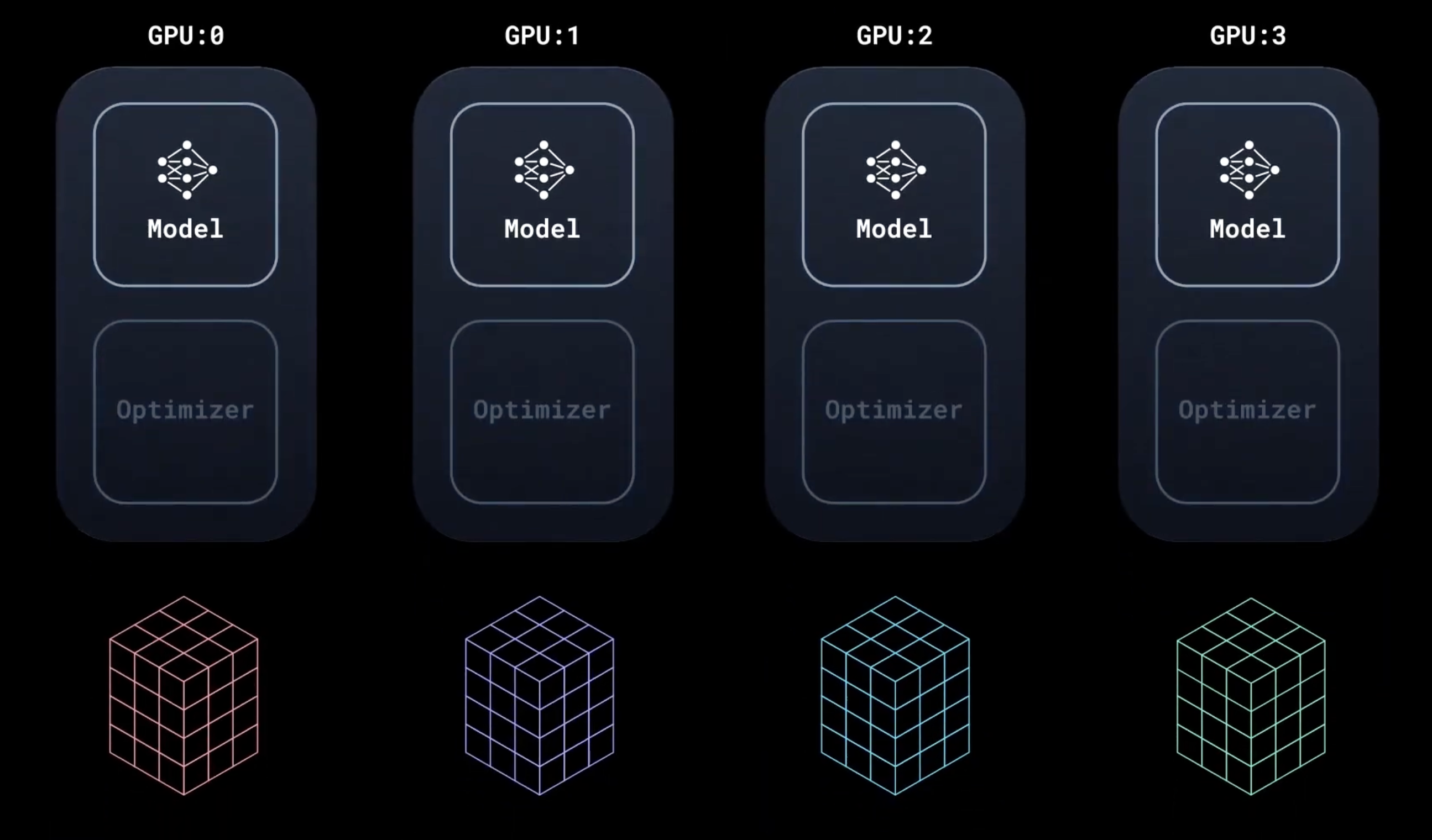
模型在所有设备上复制。DistributedSampler 确保每个设备获得不重叠的输入批次,从而处理 n 倍数据。

模型接受不同输入的数据后,在本地运行前向传播和后向传播。
July 10, 2025
pytorch 基础
数据
PyTorch 有两个用于处理数据的基元: torch.utils.data.DataLoader 和 torch.utils.data.Dataset
Dataset 存储样本及其相应的标签,DataLoader 则将一个可迭代对象封装在 Dataset 周围
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
PyTorch 提供特定于域的库,例如 TorchText、TorchVision 和 TorchAudio,所有这些库都包含数据集。以 TorchVision) 中的 FashionMNIST 数据集为例:
每个 TorchVision Dataset 都包含两个参数:transform 和 target_transform,分别用于修改样本和标签:
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)