Below you will find pages that utilize the taxonomy term “Tool”
May 13, 2025
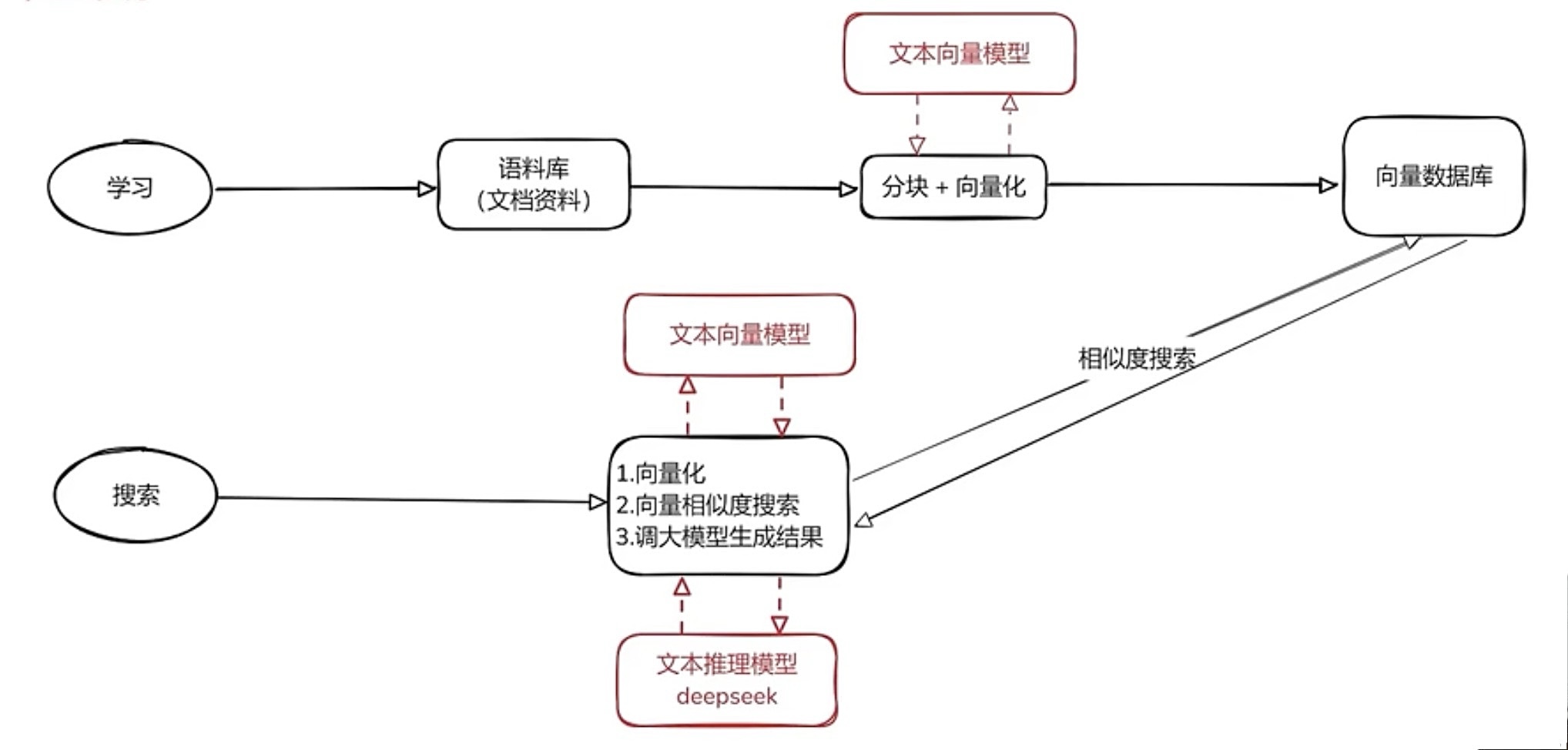
工具链-Carla
官方文档:https://carla.readthedocs.io/en/0.9.9/#getting-started
Carla是一款开源的 自动驾驶 仿真器,它基本可以用来帮助训练自动驾驶的所有模块,包括感知系统,Localization,规划系统等等。许多自动驾驶公司在进行实际路跑前都要在这Carla上先进行训练。
1. 基本架构
Client-Server 的交互形式
Carla主要分为Server与Client两个模块
April 17, 2025
工具链-PyTorch
1. 处理数据
PyTorch 有两个用于处理数据的基元: torch.utils.data.DataLoader 和 torch.utils.data.Dataset。
Dataset 存储样本及其相应的标签,DataLoader 将 Dataset 包装成一个迭代器。
下面以 TorchVision 库模块里的 FashionMNIST 数据集为例:
每个 TorchVision
Dataset都包含两个参数:transform和target_transform分别修改样本和标签
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
将 Dataset 作为参数传递给 DataLoader ,将一个可迭代对象包装在数据集上,支持自动批处理、采样、洗牌和多进程数据加载。
定义了一个 batch size 为 64,即 dataloader 迭代器中的每个元素将返回一个 64 features and labels 的 batch。

April 4, 2025
工具链-强化学习
1. gym
官方文档:https://www.gymlibrary.dev
最小例子
CartPole-v0import gymenv = gym.make('CartPole-v0') env.reset() for _ in range(1000): env.render() env.step(env.action_space.sample()) # take a random action
观测 (Observations)
在 Gym 仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据标志位 done 的状态,来决定是否进行下一次回合。代码表示:
env.step() 函数对每一步进行仿真,返回 4 个参数:
观测 Observation (Object):当前 step 执行后,环境的观测(类型为对象)。例如,从相机获取的像素点,机器人各个关节的角度或棋盘游戏当前的状态等;
奖励 Reward (Float): 执行上一步动作(action)后,智体(agent)获得的奖励,不同的环境中奖励值变化范围也不相同,但是强化学习的目标就是使得总奖励值最大;
完成 Done (Boolen): 表示是否需要将环境重置
env.reset。